STEEM Contribution Score - From Concept to Model

A few months back I posted about a creating a Contribution Score that would score STEEM Accounts with a value based on engagement and activity on the block. An alternative to reputation and a way of finding highly engaged people on the block. Since then I have been researching different theory’s that could be used to create this score with data from the block and testing some data to see what is possible.
After a positive reaction to the first post, and some further positive discussions on discord, I would like to present to you the concept of Contribution Score(CS).
Take @abh12345 engagement league (which has been proven to increase retention on the platform); now let’s add a load more data points.
Next, we need to weight the data points. This is very subjective, but what if we could use a ML algorithm that would best decide how to weight these?
Introducing Communication Theory/Information Theory and Entropy with Information Gain.
This theory is often used in decision trees to establish the most accurate and efficient route to take. A decision tree is a set of questions used to filter information allowing you make a more informed decision. It is commonly applied by banks when approving credit or loans.
Entropy is a direct measure of the "amount of information" in a variable. This all boils down to a mathematical way of calculating information measured in bits. Once the noise has been filtered, the more bits of information something provides, the more valuable it is. The aim of the algorithm is to find accounts on Steemit that are highly engaged with the platform and that contribute the most in terms of both content and curation.
Let me try and explain how it works.
For those interested in the theory and math involved check out this article and scroll down to Entropy and Information gain.
Applying this to Steemit we can take accounts and see how much information they give and how much information they received. By taking enough data points that will measure both information given and information received we should be able to highly reduce the scores of spam accounts as they tend to send out information more than they receive it.
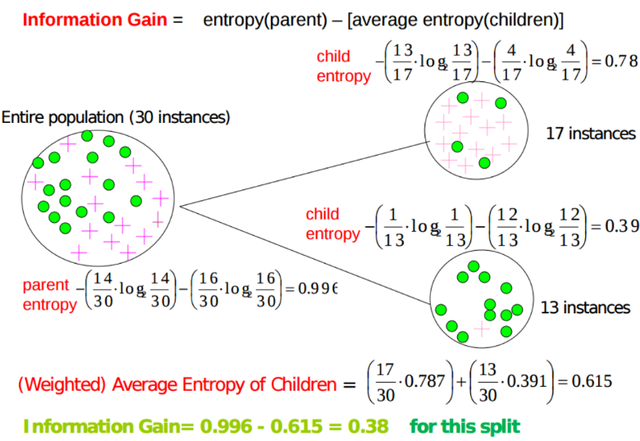
The information gain from each data point is measured and this is used to calculate the weighting of each of the data points. All calculations are based on probabilities and so the sum of all the final scores should and does = 1
If we look at the number of Root posts per author for example, the probability for each observation/Steemit account would be their count of posts/total post count. This is the probability that they will provide the next post on Steemit.
Once we have the probabilities, we can then calculate the entropy for each observation. To keep the entropy between 0 and 1 for the data point, I have used a Log to the count of accounts.
From the entropy we can then calculate the information gain. In a decision tree, this would decide the next step. However, if we use the information gain to calculate an information gain probability, this can be used to weight the probabilities from each data point removing the subjectivity.
The total score is the sum of the probabilities*information gain probability.
I have carried out some sample workings in Excel, although Excel is not made for big data, I have pushed on as far as I can go in terms of file size and file usability. The table below shows the data points that I wanted to try this with. The fields in Green are as far as I have gone.
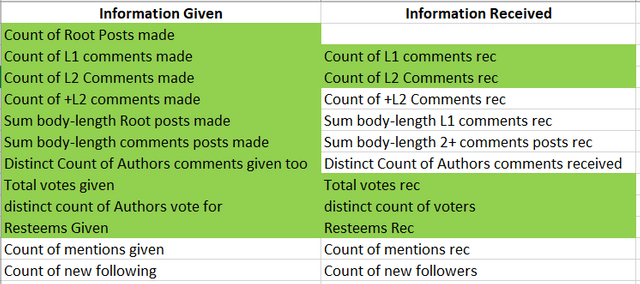
As you can see I currently have include more ‘information given’ data points than ‘information received’. As bots/autoresponders/spam accounts give information on a greater scale than receiving it, that means the test model does not do much to reduce the score on these type of account. However, by adding the additional data points we should see a great change in the score.
I am happy to share my current workings, but please be mindful that this is not a complete model as it is missing to many data points and lacks vigorous testing and used sample data.
The file, linked to below, has a worksheet for inputs, this feeds to the probability calculations sheet, then feeds to the entropy working and then the information gain sheet. The information gain probabilities on this sheet feeds to the scores workings sheet, which is also linked to the probabilities sheet. You will find the final scores, ranked in the score sheet sorted worksheet. The names highlighted in yellow are the top 10 accounts on Ashers league.
This is iteration 1 for the last 14 days, a second iteration is needed for days 15-28. The weighting on the scores would be based on the information gain from each time period. These durations are not set, just what I was using to start with. Other durations should also be tested.
You can access the excel file here to get an understanding of the calculations. However, building further on this model in excel is a waste of time as there is already over 4.5M and this workbook is now way to slow for me to proceed.
Now I need to work with someone to run this in code with all the data points listed and many more so we can test it and work on improving it. As an example, In my testing I have used count of comments. A better result may be achieved using count of unique comments as people often copy/paste comments and spam comments are often repeats.
You can view the excel file here:
https://www.dropbox.com/s/povlxr4wxt6x1cj/C_score%20workings_2.xlsx?dl=0
bit of a large shout out - the following people engaged with the previous post on this subject and I thought you might be interested in seeing the developments so far, sorry if I missed anyone.
@bashadow, @glenalbrethsen, @gniksivart, @jusipassetti. @tarazkp, @enjar, @algo.coder, @mrday, @jestemkioskiem, @paparodin, @revisesociology, @felix.herrmann, @aneukpineung78, @tfq86, @fullcoverbetting, @just2random, @cryptkeeper17, @curatorcat, @mattclarke, @mountainjewel, @gillianpearce
Hey, @paulag.
When you say this excel file is huge, you're right. I know I've never produced anything that's come close to taking 30 seconds to load. :) Good job just being able to do that!
All kidding aside, I like where this is headed. I think any form of engagement metric will need to measure both sides of the equation.
I guess for me, the question is, what's the ultimate goal with this. The idea behind the current reputation model was, via upvote you could discern those who have the best content. That seems to be the same idea behind UA, just involving followers but with the same idea that it will lead a person to the best content.
Is the idea of best content being expanded here to include comments or engagement, then? Is the idea to basically change the way we look at reputation or the best content? I don't know. Maybe I'm barking up the wrong tree here.
I'm for a different way to evaluate user interaction. The current reputation system has long since failed. I'm not completely sold on UA, but it seems to be a step in the right direction. This intrigues me a lot because it seems to be based more on what I do, and then what I might be able to influence others to do. I like that idea so far the best.
"One of the primary goals of Steem’s reward system is to produce the best discussions on the internet"
That is taken from the whitepaper. it takes more than just a good post for the best discussions to happen, people need to engage. These metrics try to find the people on steemit that are making the best discussion happen by looking at certain metrics.
Very good. So, as you were saying to someone else, the contribution score would be something that would work in concert with, say, UA, and therefore give us all a better idea of who is potentially producing good content as well as producing the best discussions.
yes, they should be able to be used together and in isolation, it really depends on the needs. but the whole idea is as you say to give us a better idea of who is actively engaged in the best discussions
Thanks for the shout out!
I knew it. You can't sleep well before pushing some magics to a little bit higher level, Ma'am. And I know it won't end here. 😎
Thanks for the shoutout @paulag; appreciate the update! Can't actually look at the excel file here; my laptop is too puny to process it without locking up. However, from your description, I think you're onto something viable...
I have also been watching what the Steem UA guys have been doing, and I realize they are measuring something else that's less "activity specific" but it seems like there might be an opportunity for resource sharing and collaboration here.
It's slightly alarming to me just how FAR that is from current reality. Which, I suppose, just illustrates the Human condition; We have great ideals... and once money is involved, everything goes down the drain. So far, we have seen "Those with the most SP win" and "those who can buy the most votes win."
Anyway, I'm still holding some hope for that original ideal, and I'll be interested in seeing your ongoing efforts to quantify them!
=^..^=
With a bit of heavy lifting support this could be a better indicator than both standard reputation and steem-au. Hope to see the idea progressed.
A lot of heaving lifting and work is needed on this to make it a reality, but the good news is that I have spoken with a few talented people with the skills needed.
I missed the @excelclub post on Machine Learning, cool stuff!
While UA is leading the way as far as an alternative solution, I've seen numerous comments over the past week on their initial post, my post yesterday, and in @tarazkp's post this morning with regards to the scoring potentially lacking an engagement element.
I've just seen that in the steem-ua discord however that they are starting to look into engagement as a metric:
The information in/out sounds most interesting with regards to this concept and model. But there is obviously still lots of work to do for everyone looking at a better solution to reputation :)
yes its good to see that UA are implementing ideas to include engagement, and they are open to feedback as this was a suggestion that I had made to them
However UA and CS are rather different and cater for different needs. I believe these two scoring systems could easily compliment each other.
Thanks for your suggestion, it is improving the UA vote calculation. Engagement is my weak spot, now I have a score for it. This will help me to write more answers and comments on my posts, hopefully ;).
we all bring different things to the block. Some are awesome engagers, some are awesome developers, some are awesome at promoting steemit to the wider public. each quality has its own value and merit.
You already know I am a fan of UA, and we are all batting for the same team here, the steem team :-) I even have a much higher UA score than CS score which I find rather funny
Interesting to see where this one leads! Great work @paulag. <3
oh i like this very much... makes a lot of sense to me to incorporate this asap actually...
wow 'asap' now I am under pressure lol. Glad you like the idea @meno, I know you are keen on the engagement side, its a metric many community leaders focus on.
This is mind blowing. We need this to be fully developed. It's time we figure out true and organic reputation score not some artificial numbers. I am really looking forward to see you roll out the model @paulag. I see a project changing the way we look at the STEEM ecosystem.
Cheers @bait002, lets hope we can make a difference 😃
Posted using Partiko Android
Love this Paula, and am glad to see UA already open to want to implement something like this. It will make the scores more rounded, giving us a more complete picture. Thanks for this!
UA are not implementing this from what i know but they have taken suggestions on bord which is cool
Posted using Partiko Android
I am glad to see the response and responses to your your post. (I am still waiting for the file to download, slow connection for me). Using it in combo with other scores can give a user a little bit of an idea on an account. Even though Rep is broken, it is somewhat easy to see the Rep buyers not always but sometimes. With UA and now your CS scoring we can have three things to look at and decide. A combination of CS and UA would be useful the most I think.
I am not sure but I think in the UA post they talked about not showing most of the bots via their system, so with it and CS a mostly bot free system type score.
It was nice to read so many nice comments and to see there are people working on issues, which we do not get to see often enough.
I think, but not sure UAs system was designed to score bots/spam poorly too.
What is important to remember that both systems score different metrics and cater to different needs. Therefore can be used in isolation or together.
Posted using Partiko Android
This is very interesting, @paulag! The concept of information given and received sounds reasonable. I have no experience with ML, but I guess tuning the algorithm is key to find a reasonable metric? I had a quick look into the excel (close to 100 MB - wow :) ). I see a couple of bots in the current top 50. Some of them post more or less the same content repeatedly, which could somehow be ruled out by looking into the entropy across comments. Others echo user comments, which is probably harder to filter out. I also noticed a couple of steemhunt mods, giving dozens of comments daily. Overall great work, looking forward to updates!!
a metric like word diversity, or count of 'unique' comments are on my list to test. Tuning and testing is key. This was a very raw model, a very early starting point. Glad you got the file open, many didn't lol, but I needed to do some sort of testing and well thats the tool I know how to use best. Delighted you came by to have a read, thanks for taking the time to review the idea.
Very interesting.. How will this account for things like that it's, who engage with enough intelligence to spam a few unique comments to various users with high engagement or reputation or other metric scores, simply to augment their own reputation by playing the numbers game of the algorithm. Almost "reverse calculating" who they need to interact with and how they need to interact as opposed to being human and interacting naturally?
Let's face it, we're playing a zero sum game here against the people who are building these bots for profit... There will always be an incentive to game the system or metrics that are in place to "protect the content". And bots will always win in the long-run based on the resources available to them vs the resources available to a valid and interesting content creator.
reverse calculations would not be impossible but the information gain probability on each data point used for the weighting would change each day so it would mean working out which metric is the best on the day, rather difficult for the average person. You are so right there will always be an "incentive to game" and so we would need to continuously evolve and we would not be able to eliminate this,
I'm not trying to say that your efforts are for naught, but this is something that I feel any "rating" efforts will need to consider. In my previous analysis of the blockchain, before SteemSQL was a for-purchase tool, there were many attributes that overwhelmingly identified bots/spammers/scammers, but also found valid users who were new and unaware of "acceptable" posting etiquette. The same will occur for providing rankings of valid users, except the "smart bots" will adapt to appear like valid users. The monetary incentive will always murky even the most complex and thoughtful algorithm.
I wish you all the best of luck, but I hope that expectations are tempered and considerable value is not weighted on any of these new scoring mechanisms until they are fully vetted. Looking solely at the top rank and bottom rank may be tempting, but sampling the middle ranks will be paramount to developing a truly reliable scoring method.
I value your input and my efforts my very well be for naught but at least I can say I tried to come up with solutions, and I will keep trying. Steemit allows us do that, help try shape the future of the platform. My intentions are good.
I hear you, and know that you are one of the (few) people who have good intentions for Steemit. I truly do hope that your methods work and improve the platform. Nothing in life is perfect, and I don't want to be a spout of negativity.
I just wanted to offer some feedback on how I've seen things like this pan out here in the past.
"The road to hell is paved with good intentions." -- sometimes even good acts have unintended negative consequences. Just look at the bidbots...