[머신러닝] 파이썬 머신러닝 #6 - 스팀잇에서 유사한 게시물 찾기
안녕하세요. @anpigon입니다.
@nhj12311님의 "Node & Steem #11 - 글 아카이브 ... 포스팅 분류하기" 게시글을 보고 저도 비슷하게 구현해보았습니다. 시리즈 글을 찾아주는 기능은 @nhj12311님이 완벽하게 구현하였더군요. 그래서 저는 @nhj12311님과 다르게 시리즈 글이 아닌 유사도가 높은 게시글을 찾아내는데 초점을 맞추었습니다.

구현에는 이전에 작성한 "유사한 게시물 찾기"과 조대협님의 "NMF 알고리즘을 이용한 유사한 문서 검색과 구현"를 참고하였습니다. 그리고 구현 과정과 결과물을 아래에 간략하게 정리하였습니다

스팀잇 게시글 가져오기
steem api를 이용하여 내가 작성한 게시글(posts)을 모두 가져온다. 그리고 가져온 Post에서 분석에 필요한 데이터(title, body, author, permlink)만 사용한다.
from steem import Steem
from steem.blog import Blog
# 게시글(Post)에서 필요한 필드 정의
filter_post = ['title', 'body', 'author', 'permlink']
# 스팀잇 게시글 가져오는 함수
def loadSteem(username):
print('@%s님 글 가져오는 중...' % username)
b = Blog(username)
posts = b.all() # 게시글 모두 가져오기
# 필요한 데이터만 추려서 반환
return [{k: v for k, v in p.export().items() if k in filter_post} for p in posts]
# 스팀잇에서 글 가져오기
posts = loadSteem('anpigon')
posts # 결과 출력
형태소 분석
konlpy.Mecab를 이용하여 형태소 분석을 한다. 그리고 분석하는데 불필요한 품사는 모두 제거하였다. 품사 코드는 여기에서 참고하였다. 그리고 분석된 텍스트 데이터는 Pandas의 DataFrame 자료구조를 이용하여 처리하였다.
import pandas as pd
from konlpy.tag import Mecab
pos_tagger = Mecab()
# 분석에 필요한 품사 정의
filter_pos = ['NNG', 'NNP', 'NNB', 'NR', 'NP', 'VV', 'VA', 'VX', 'AX', 'VCP', 'VCN', 'MM', 'MAG', 'MAJ']
# 형태소 분석하는 함수 정의
def morphs(text):
tokens = pos_tagger.pos(text)
# 형태소 분석하여 필요한 품사의 단어만 문장으로 구성하여 반환
return ' '.join([word for word, pos in filter(lambda x: (x[1] in filter_pos), tokens)])
# DataFrame 객체 생성
df = pd.DataFrame(columns=['title', 'body'])
# 가져온 게시글(posts)을 DataFrame에 입력
for i, post in enumerate(posts):
key = post['author'] + '/' + post['permlink']
body = morphs(post['body']) # 형태소 분석
if len(body) > 10:
value = {
'title': post['title'],
'body': body,
}
df.loc[key] = value
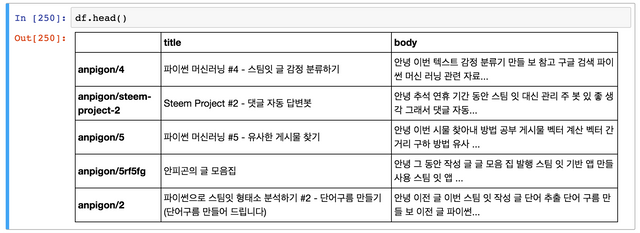
Pandas는 데이터 구조 및 데이터 분석 도구를 제공하는 파이썬 라이브러리이다. 그리고 오픈 소스 BSD 라이센스를 가지고 있다. pandas.DataFrame의 기능은 pandas 문서를 참고하면 된다.
DataFrame의 head를 출력하면 아래와 같다.
Tfidf 를 이용한 단어의 벡터화 구현
tfidf 모델을 이용하여 단어를 벡터화한다. sklearn에서 제공하는 TfidfVectorizer를 이용하면 쉽게 구현할 수 있다. TfidfVectorizer 객체를 생성하고 fit_transform을 이용하여 body에 담겨있는 텍스트 데이터를 벡터화한다.
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
vectors = vectorizer.fit_transform(df['body'].tolist())
print(vectors.shape)
NMF를 이용하여 게시글에서 특성 추출
NMF를 이용하여 각 게시글에서 특성을 추출한다. NMF에 넘겨주는 n_components=10값은 특성을 10개로 압축하여 추출한다는 의미이다.
from sklearn.decomposition import NMF
vector_array = vectors.toarray()
nmf = NMF(n_components=10)
nmf.fit(vector_array)
features = nmf.transform(vector_array)
피쳐 정규화
Normalizer를 이용하여 features를 0 ~ 1 로 스케일링을 한다. sklearn에서 제공하는 Normalizer를 이용하면 쉽게 구현할 수 있다.
from sklearn.preprocessing import Normalizer
normalizer = Normalizer()
norm_features = normalizer.fit_transform(features)

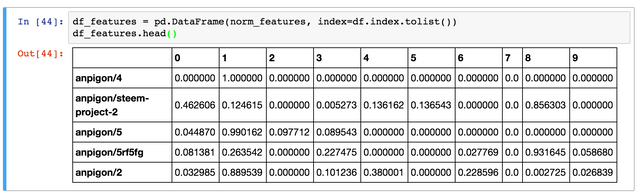
df_features에 게시글별 특징과 인덱스를 가지고 데이타 프레임을 만들어서 생성한다. 인덱스는 author/permlink의 형태이다. 그리고 0 ~ 9 컬럼은 각 게시글의 특징이다.
df_features = pd.DataFrame(norm_features, index=df.index.tolist())
df_features.head()
문서 유사도 계산
이제 기존에 작성한 게시글에서 파이썬 머신러닝 #4 - 스팀잇 글 감정 분류하기
글과 유사한 게시글을 찾아보자. DataFrame.loc 함수를 이용하면 해당 게시글의 특성 행렬을 가져올 수 있다. 가져온 특성 행렬은 article에 저장한다.
article = df_features.loc['anpigon/4']
print(article[:10])

DataFrame.dot 함수를 이용하면, 한 게시글의 특성 행렬을 전체 게시글의 특성 행렬에 대해서 계산할 수 있다. 전체 게시글에서 각 게시글의 특성 행렬과 article의 특성 행렬을 곱한다. 그러면 article과 각 게시글에 대한 유사도가 계산된다. 이렇게 계산해서 나온 값이 큰 순으로 정렬해서 top에 저장한다. 그리고 유사도가 높은 순으로 게시글의 제목 10개를 출력해보자.
similarities = df_features.dot(article)
top = similarities.nlargest(10)
texts = df.loc[top.index].values
i = 0
for title, body in texts:
print('=== 유사도 %.4f: %s' % (top[i], title))
i += 1

파이썬 머신러닝 관련 글이 상위에 모두 있다. 그리고 유사도가 90%에 가깝게 나와서 만족한 결과가 나왔다.
이제 다른 사람이 작성한 게시글로 테스트해보자.
테스트 결과
@nhj12311님의 [개발] Node & Steem #11 - 포스팅 아카이브 기능으로서의 첫 걸음. 포스팅 분류하기.
게시글과 유사한 게시글을 찾아보자.

결과를 보면 @nhj12311님은 비슷한 글을 많이 작성해서 그런지 대부분의 개발 관련 글은 높은 유사도를 보인다.
마지막으로 @forhappywomen님의 임·준·출 19화 - 기형아검사?!!!
게시글도 테스트 해보았다.

"임·준·출" 시리즈 글이 상위권에 포진해 있지 않다. 아마도 "임·준·출" 시리즈는 매 번 주제가 바뀌어서 그런 것 같다. @nhj12311님 말대로 머신러닝으로 시리즈 글을 묶어내는 건 매우 어려워 보인다.
단어를 벡터화해서 벡트 간의 거리 계산으로 유사한 글을 찾는 방법은 내용에 같은 단어가 많으면 유사한 글로 분류될 가능성이 높습니다. 그리고 Word2Vector와 딥러닝을 이용하면 정확도를 더 높일 수 있다고 합니다. Word2Vector와 딥러닝을 공부하고 난 후에 다시 도전해 볼 생각입니다.
여기까지 읽어주셔서 감사합니다.

아직 Payout 되지 않은 관련 글
모든 기간 관련 글
인터레스팀(@interesteem)은 AI기반 관심있는 연관글을 자동으로 추천해 주는 서비스입니다.
#interesteem 태그를 달고 글을 써주세요!
맞습니다. 실제로 유사한 글도 마찬가지고요. 유사도로 검사하는 것보다 핵심이 되는 품사로 구글에 대고 검색하는것이 더 유사도 높은 글을 찾을 수 있습니다. ^^ 고생 많으셨습니다. 아 댓글 쓰는것도 무섭네...
유사한 글 찾는건 정말 어렵네요. nhj12311님 말대로 구글 검색하는게 더 빠르겠어요. 이것도 나중에 구현해봐야겠어요. 잼미있겠어요.😆ㅎㅎ
그리고 이제는 댓글을 아껴 써야겠어요.ㅠ
예전에 구글 검색해서 댓글 달아주는건 만든적이 있습니다. ^^
저는 관련글 검색 기능을 구글 검색 기능으로 대체 해서 달아주려는 생각을 하고 있지요. ㅎㅎ 제목이나 본문에서 중요도가 가장 높은 단어 2개 정도로 구글에 대고 검색하는게 더 정확한 검색 결과를 낳지 않을까요?
ps. 그나저나 파이썬 api는 굉장히 편하네요. js는 극악으로 불편한데 ㅠㅠ
예전에 해당 기능을 벌써 구현하셨군요. 대단하십니다.👍 그리고 말씀대로 키워드를 추려서 구글 검색결과 보여주는 게 더 정확할 것 같네요.
python은 wrapper 함수가 많아서 사용하기가 좀 더 간편합니다. ㅎㅎ 하지만 저는 아직은 코딩할때 javascript가 편해요.
ps. 저는 이제 RC가 부족해서 댓글을 이어가지 못합니다.ㅠㅠ
안타까운 상황입니다... 아주 스파로 사람 잡는 포크군요. ㅎㅎ
RC 회복 시간은 매우 오래걸리네요.
안타깝습니다.ㅠㅠ
두분의 재미있는 개발 기대하며 임대드립니다.
제 아이디의 보팅마나가 부족한 바람에 우선 500 SP 임대드렸습니다.
활동에 불편함이 있으시면 알려주시면 추가로 임대 드리도록 하겠습니다. 좋은 하루 되세요.
왘~ 캄사합니다~😀 덕분에 스팀파워가 올라갔습니다. 이 정도면 활동하는데 지장 없습니다.🤗
벌써 밤이네요. 좋은 밤 되세요~⛼
두분 너무 재미있게 개발하시는것 같아서 부럽습니다 ㅎㅎㅎ
재미있게 하려고 하는데 포크로 사람을 찍어버리네요 ㅋㅋ
ㅎㅎㅎ 역시 이런 난관이 있을때 개발자 분들이 빛을 발하시는 것 같아요^^
어제 파이썬 처음 공부했는데 ㅋㅋㅋ
저두 나중에 알수 있겠죠?
ㅋㅋㅋㅋㅋ
계속 공부하다보면 언젠가 깨달음이 오는 날이 올꺼에요. 제 경우는 그랬어요.ㅎㅎ
저도 이제 파이선으로 dive를 ㅋ
안피곤님 글 보면서 조금씩 해봐야겠네요 ㅎㅎ
nodejs랑 python 이랑 spring 적절하게 섞어 짬뽕으로 ㅋ
정말 배울건 많고 쉽진 않네요 :)
좋은 글 감사요 / 아 flutter도 해야 되고 으윽
원사마님 플루터까지 하시나요? 대단해요~👍
저도 플루터 공부하고 싶은데 자료가 많이 없어서 엄두를 못내고 있습니다. 언제 한번 초보자도 따라할 수 있게 좀 가르쳐주세요.ㅎㅎ
Hi @anpigon!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your UA account score is currently 1.736 which ranks you at #29981 across all Steem accounts.
Your rank has not changed in the last three days.
In our last Algorithmic Curation Round, consisting of 726 contributions, your post is ranked at #450.
Evaluation of your UA score:
Feel free to join our @steem-ua Discord server