선형 데이터 구조 …계속 — 스택, 큐 및 해시 테이블 작성자 Dineshchandgr 중간
선형 데이터 구조 …계속 — 스택, 큐 및 해시 테이블
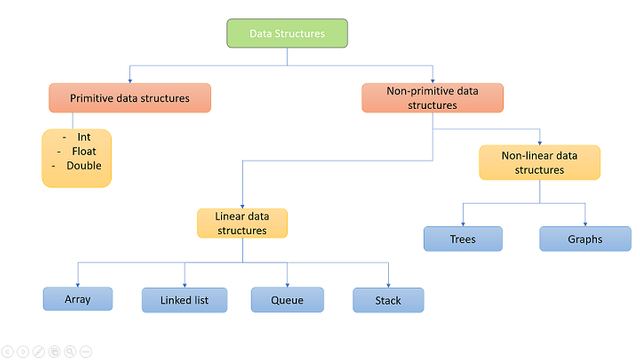
이미지 출처: https://upload.wikimedia.org/wikipedia/commons/6/6d/Data_Structure.png
{kind=link}
여러분, 안녕하세요. 이 기사는 이전 기사의 연속입니다. 데이터 구조의 기본 사항과 배열 및 LinkedList에 대한 자세한 정보에 대한 아래 기사를 참조하십시오.
알고리즘의 시간 복잡도에 대해 알고 싶다면 내 기사를 참조하십시오.
이 기사에서는 Stack, Queue 및 HashTable과 같은 다른 선형 데이터 구조를 자세히 살펴볼 것입니다.
이러한 데이터 구조는 내부적으로 Array 또는 LinkedList를 사용하는 래퍼 데이터 구조입니다.
스택
스택은 LIFO(Last In First Out) 개념을 기반으로 구현된 데이터 구조입니다. 스택은 책 더미와 같은 실제 시나리오를 묘사합니다. 아래에 놓은 책이 마지막으로 집어들고 맨 위에 놓은 책이 먼저 집어들게 됩니다.

이미지 출처: https://freesvg.org/img/1527134288.png
{kind=link}
스택의 응용
스택에는 다음과 같은 많은 응용 프로그램이 있습니다.
- 실행 취소 기능을 구현하려면
- 컴파일러 빌드
- 대괄호와 같은 표현식 평가
- 반전
- 탐색(웹 브라우저)
인터뷰의 많은 데이터 구조 및 알고리즘 질문은 스택을 사용하여 해결할 수 있습니다.
스택의 구조
스택 데이터 구조는 자체적으로 존재하지 않습니다. 위에서 설명한 대로 배열 또는 LinkedList를 둘러싼 래퍼입니다.
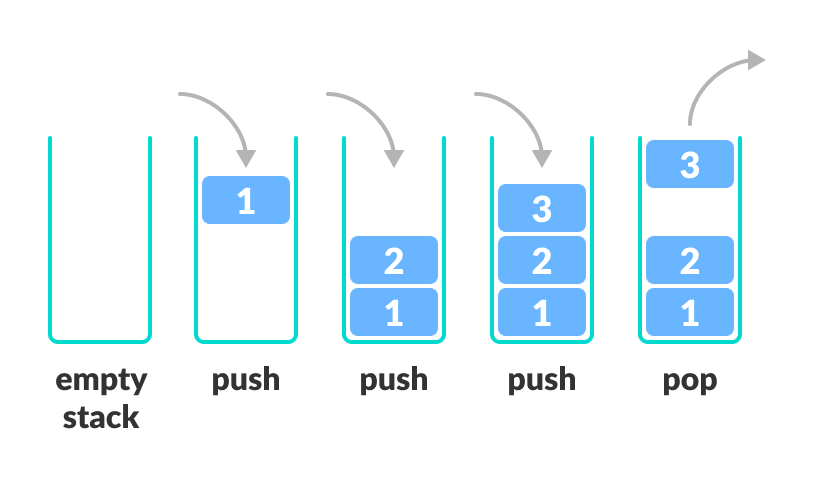
스택에는 스택의 헤드인 top이라는 포인터가 있습니다. 삽입 및 삭제는 스택의 헤드에서만 발생합니다. 아래 다이어그램은 스택에서 작업이 수행되는 방식을 보여줍니다.
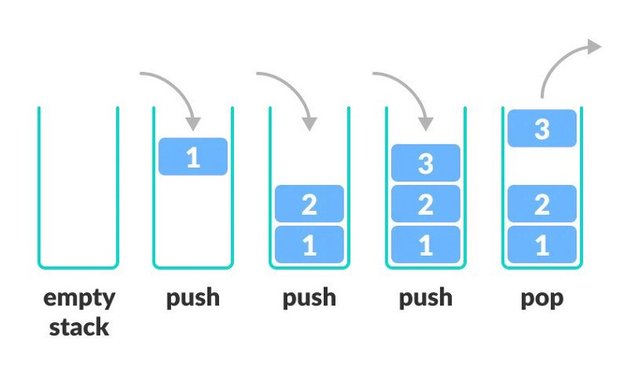
이미지 출처: https://cdn.programiz.com/sites/tutorial2program/files/stack.png
{kind=link}
스택에서 수행되는 작업
스택에서 수행할 수 있는 4가지 작업이 있으며 O(1) 시간 복잡성 으로 수행할 수 있습니다.
- 푸시 — 항목을 스택에 푸시합니다.
- Pop — 스택에서 항목을 제거하려면
- Peek — 스택 맨 위에 있는 항목을 검색/가져옵니다. Pop과 달리 항목을 제거하지 않습니다.
- isEmpty — 스택이 비어 있는지 확인
대기줄
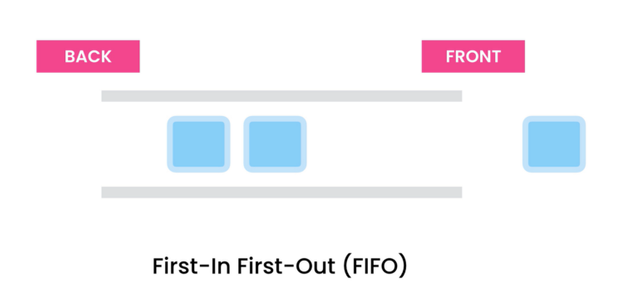
대기열은 실제 대기열을 따르는 프로그래밍의 데이터 구조입니다. FIFO 패턴(First In First Out)을 따릅니다. 대기열에 들어가는 사람이 먼저 존재합니다. 마찬가지로 Queue 데이터 구조에서 먼저 추가된 요소가 먼저 제거됩니다. 요소는 뒤쪽(뒤), 즉 꼬리에서 큐에 들어가고 큐의 맨 앞(앞)으로 나갑니다.
대기열의 응용
대기열은 실제 세계에서 광범위하게 적용되며 그 중 일부는
- 프린터
- 운영 체제
- 웹 서버
- 간 지원 시스템
- 레스토랑 주문
대기열의 구조
Queue는 내부적으로 Array 또는 LinkedList를 사용하며 Stack과 같은 래퍼입니다. Front 및 Back이라는 두 개의 포인터가 있습니다. 대기열이 비어 있으면 앞뒤가 같은 위치를 가리킵니다. 항목이 계속 추가되면 대기열의 앞쪽이 계속 앞으로 이동합니다. 대기열에서 항목이 삭제되면 대기열의 앞쪽이 계속 뒤로 이동합니다.
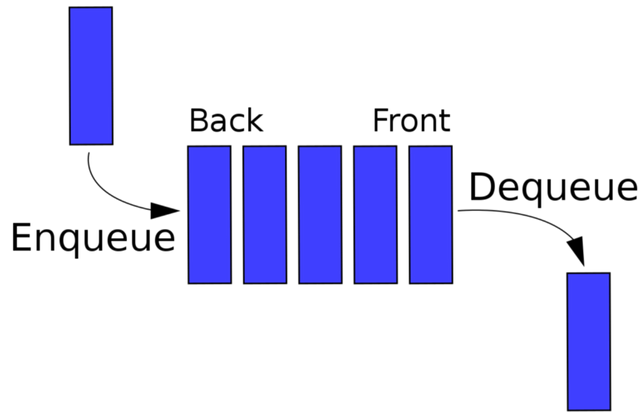
이미지 출처: https://upload.wikimedia.org/wikipedia/commons/thumb/5/52/Data_Queue.svg/1200px-Data_Queue.svg.png
{kind=link}
대기열에서 수행되는 작업
Queue에서 수행할 수 있는 작업은 5개이며 모든 작업은 O(1)입니다.
- Enqueue — 항목을 대기열에 추가합니다.
- Dequeue — 대기열에서 항목을 제거합니다.
- 엿보기 — 대기열 맨 위에 있는 항목을 검색/가져옵니다. dequeue와 달리 항목을 제거하지 않습니다.
- isEmpty — 대기열이 비어 있는지 확인
- isFull — 대기열이 가득 찼는지 확인
대기열 유형
- 우선순위 대기열
- 순환 대기열
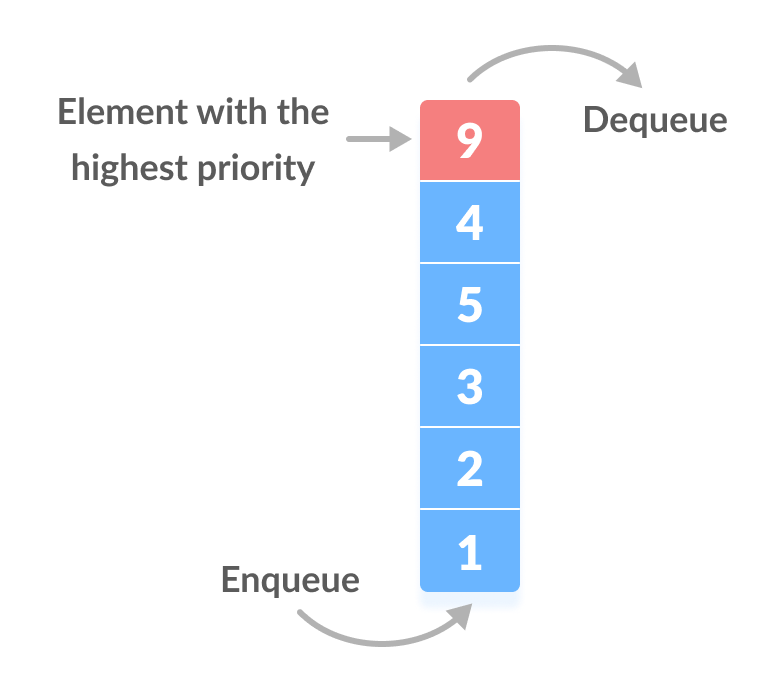
우선순위 대기열
우선순위 큐는 각 요소에 우선순위가 할당되어 있고 우선순위에 따라 요소가 제거되는 큐 유형입니다.
개체는 삽입 순서가 아닌 우선 순위에 따라 처리됩니다.
이 대기열에서 요소는 우선 순위에 따라 매번 이동하므로 항목을 대기열에 추가하는 데 O(n) 시간 이 걸립니다.
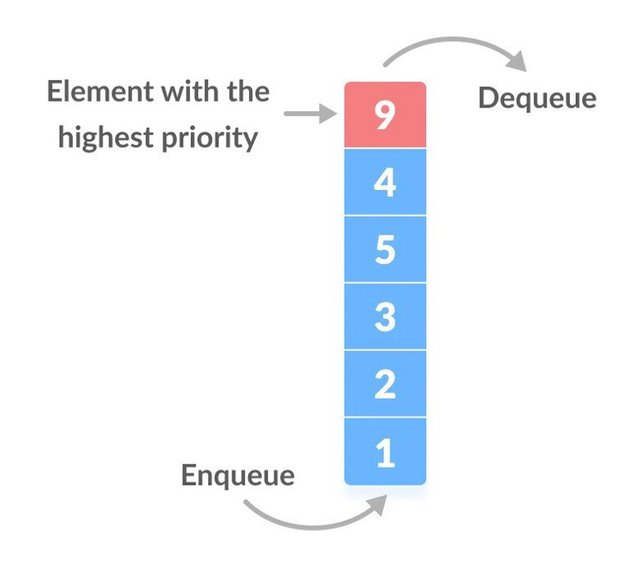
이미지 출처: https://cdn.programiz.com/sites/tutorial2program/files/Introduction.png
{kind=link}
순환 대기열
원형은 일반 대기열과 같지만 후면 요소가 전면 요소에 연결되어 원을 형성합니다. 이렇게 하면 사용하지 않는 위치에 요소를 삽입하고 후면 포인터를 해당 위치로 이동하여 메모리를 효율적으로 관리하는 데 도움이 됩니다.
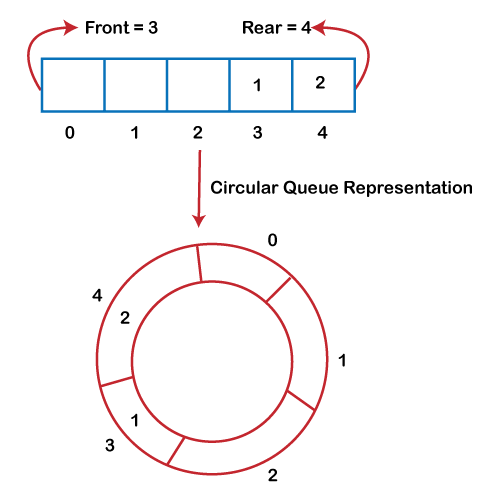
이미지 출처: https://static.javatpoint.com/ds/images/circular-queue.png
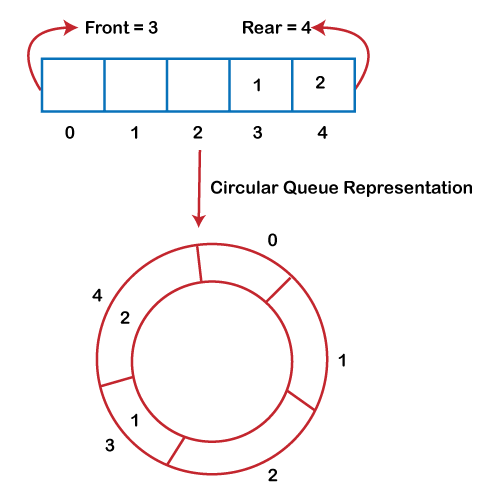{kind=link}
해시 테이블
해시 테이블은 일반적으로 LinkedList의 배열을 사용하여 구현되는 또 다른 데이터 구조입니다. 모든 배열 인덱스는 선형적으로 증가할 수 있고 특정 시나리오에서 사용할 수 있는 LinkedList에 대한 포인터를 보유합니다.
해시 테이블은 빠른 조회를 제공하며 O(1) 시간 에 알고리즘을 최적화하는 데 사용됩니다 . 다음과 같이 다른 언어로 다른 이름을 가지고 있습니다.
자바 — 해시맵자바스크립트 — 객체파이썬 — 사전C# — 사전
HashTable의 응용
HashTable은 여러 곳에서 응용되고 있으며 그 중 일부는 다음과 같습니다.
- 맞춤법 검사기
- 사전
- 컴파일러
- 코드 편집기
해시테이블의 구조
HashTable에는 버킷이라는 요소의 배열이 있습니다. 삽입하는 모든 요소에는 키와 값 쌍이 있습니다. 키는 고유하고 값은 고유하지 않습니다.
각 버킷은 배열의 메모리 위치이며 개별 LinkedList를 가리킵니다.
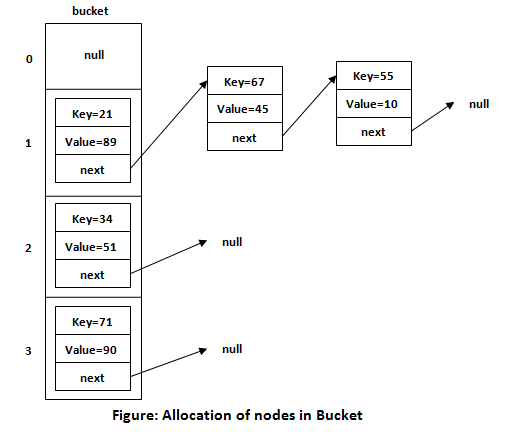
이미지 출처: https://static.javatpoint.com/images/core/working-of-hashmap-in-java2.png
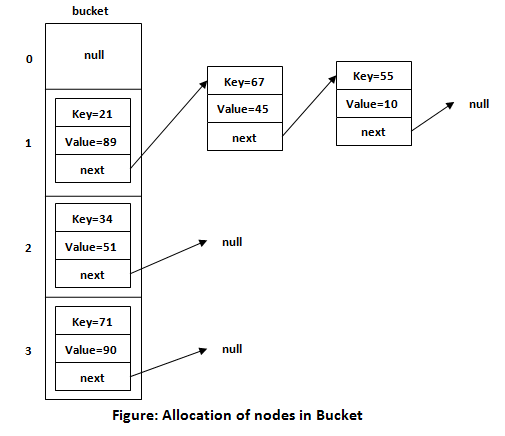{kind=link}
해시 함수
HashTable의 삽입 및 검색 프로세스는 Hash Function에서 Hash를 생성한 후에 발생합니다.
모든 키는 해시 함수를 통해 해시되고 해당 키의 값은 제공된 버킷에 삽입됩니다.
해시 함수는 항상 동일한 키에 대해 동일한 값을 반환합니다.
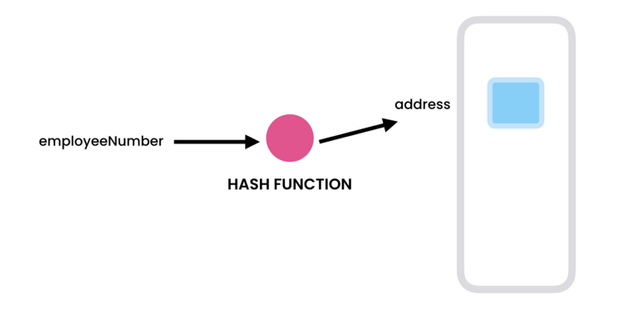
해시 테이블의 작업
배열에서 다음 세 가지 작업을 수행할 수 있습니다.
- 삽입 — 배열에 요소를 추가합니다.
- 삭제 — 배열에서 요소를 삭제합니다.
- 조회 — 배열에서 요소 검색
Hash Function 및 Array 인덱스를 사용한 조회로 인해 모든 작업에 대한 최상의 사례는 O(1) 입니다.
그러나 Hash Function이 제대로 구현되지 않으면 연산의 최악의 경우는 O(n) 시간 이 될 것입니다.
충돌
2개의 개별 키가 동일한 해시 값을 생성하면 이를 충돌이라고 합니다. 위에서 언급했듯이 Array의 각 셀은 LinkedList를 구현합니다.
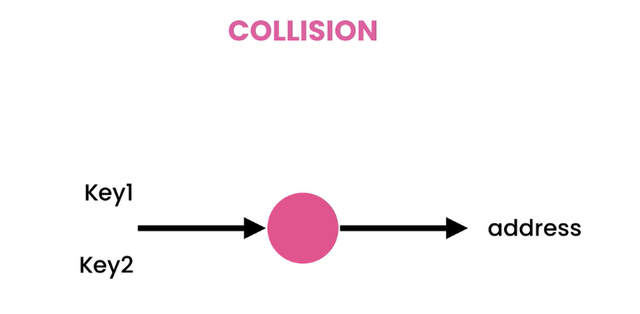
동일한 버킷에서 요소가 충돌할 때마다 따라야 할 두 가지 접근 방식이 있습니다. 그들은 다음과 같습니다
체이닝
오픈 어드레싱
체이닝
2개의 값이 동일한 버킷에 있으면 이러한 요소는 LinkedList를 사용하여 연결됩니다. 이 프로세스는 요소의 체인을 형성하고 충돌이 많으면 선형으로 계속 성장하기 때문에 체인화라고 합니다.
최악의 경우 시간복잡도는 O(n)이 된다. 따라서 Java 버전 8에서는 특정 임계값 에 도달한 후 LinkedList를 Red-Black 트리로 변환하여 HashMap의 내부 구현을 변경했습니다.
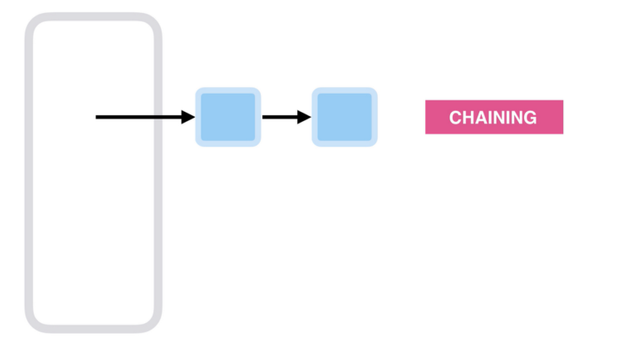
즉, HashMap은 연결 목록에 항목 개체를 저장하는 것으로 시작하지만 임계값에 도달한 후에는 연결 목록이 내부적으로 재정렬되어 균형 잡힌 트리가 됩니다. 이것은 시간 복잡도를 O(n)에서 O(n logn)로 가져옴으로써 효율성을 향상시킬 것입니다.
시간 복잡도의 차이를 이해하려면 시간 복잡도에 대한 내 기사를 참조하십시오.
2. 오픈 어드레싱
충돌의 경우 LinkedList에 요소를 추가하는 연결과 달리 Open Addressing은 항상 배열 자체 내에서 키의 새 위치를 찾으려고 시도합니다.
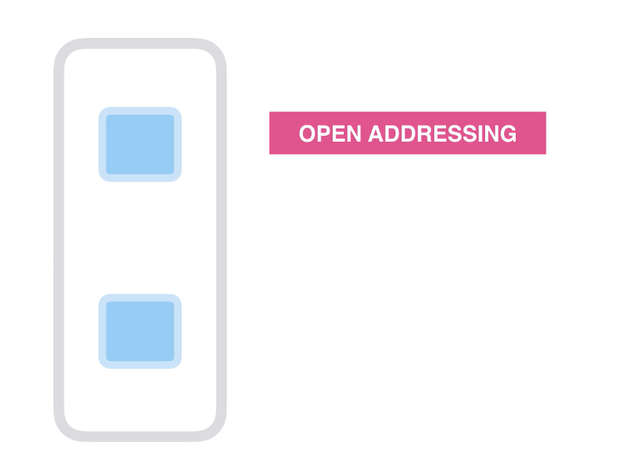
우리는 LinkedList에 저장하지 않고 같은 배열에 저장합니다. Open-Addressing에서 키-값 쌍의 주소는 해시 함수에 의해 결정되지 않습니다. 값을 검색하고 찾아야 합니다.
개방형 주소 지정 알고리즘의 유형
ㅏ. 선형 프로빙
비. 2차 프로빙
씨. 이중 해싱
ㅏ. 선형 프로빙
충돌이 발생하면 값을 저장할 여유 슬롯을 찾을 때까지 다음 여유 인덱스를 검색합니다. 단점은 어레이가 가득 차면 어디에도 저장할 수 없다는 것입니다.
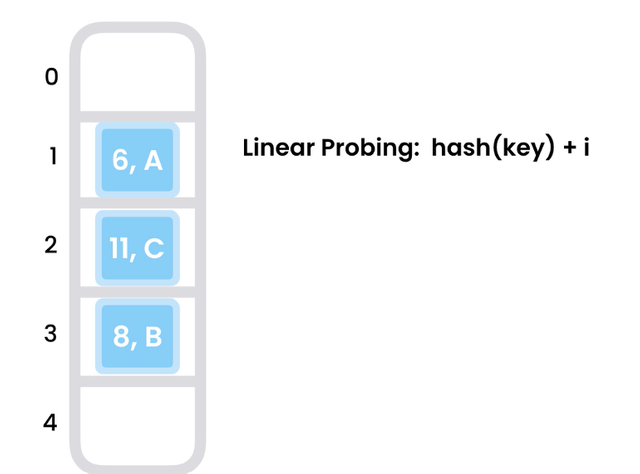
해시 값으로 시작하여 1씩 증가시킵니다. 중간에 항목이 있으면 요소 클러스터의 형성으로 인해 향후 검색 속도가 느려집니다.
비. 2차 프로빙
2차 탐색 방법에서는 i의 값을 제곱하고 해시 키에 추가하여 중간에 요소가 클러스터링되는 것을 방지합니다.
해시 값의 차이는 다음과 같습니다.

i 값이 배열의 경계 내에 있도록 하려면 테이블 크기에 대해 모듈로를 항상 수행해야 합니다.
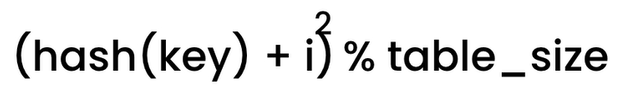
이 접근 방식의 단점은 해시 값에 요소(예: 1,4,9,15,25)가 있는 경우 무한 루프에 빠질 수 있다는 것입니다.
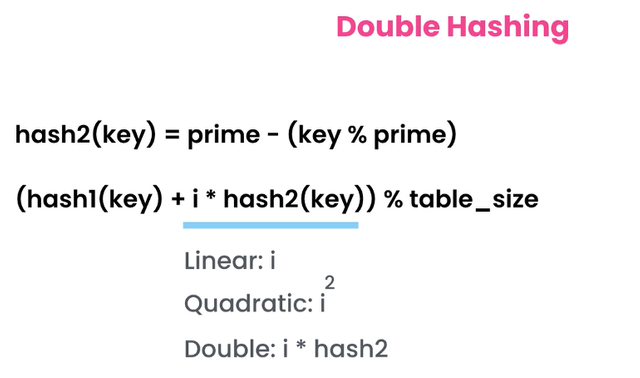
3. 더블 해싱
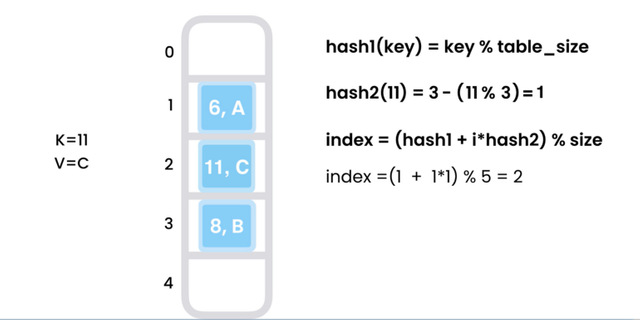
Double Hashing은 두 번 해싱하는 개념으로 작동합니다. 아래와 같이 다른 해시 키를 사용합니다. 우리는 아래 공식에서 hash2 키를 가지고 i 값에 2번째 해시 함수를 곱하고 1번째 해시 키에 더하여 고유한 값을 얻습니다.
아래 다이어그램은 충돌이 있을 때 이중 해싱을 사용하는 요소의 인덱스를 찾는 방법을 보여줍니다.
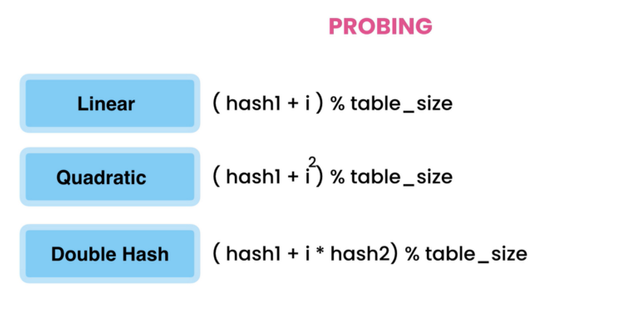
프로빙 요약
우리는 Open Addressing에서 세 가지 기술을 보았고 아래 다이어그램은 세 가지 프로빙 기술 각각에 사용되는 공식을 요약한 것입니다.
데이터 구조 설정
대부분의 사용자는 키만 있고 값은 없는 Set 데이터 구조에 익숙할 것입니다. HashTable과 마찬가지로 중복 키를 허용하지 않으므로 고유한 요소만 포함합니다.
Set은 고유성을 유지하기 위해 널리 사용되며 내부적으로 HashTable을 사용합니다.
예: 중복 숫자 목록이 주어진 경우 -> Set에 요소를 추가하여 고유하게 만듭니다. 그런 다음 목록을 고유하게 만들기 위해 다시 목록으로 변환합니다.
HashSet은 Java에서 가장 널리 사용되는 Set 구현입니다.
요약
이 기사에서는 Stack, Queue 및 HashTable이라는 세 가지 선형 데이터 구조에 대해 자세히 살펴보았습니다. 우리는 스택으로 시작한 다음 큐와 큐의 두 가지 유형에 대해 살펴보았습니다. 그런 다음 HashTable에 대해 자세히 알아보고 Hash 함수, Collision 및 이를 방지하기 위한 다양한 기술에 대해 배웠습니다. 그럼 간단하게 Set에 대해 알아보고 이 글을 마치도록 하겠습니다.
[광고] STEEM 개발자 커뮤니티에 참여 하시면, 다양한 혜택을 받을 수 있습니다.