So different but still together: exploring Steem community with machine learning
Money is one of the most human incentives, so it's not surprising that many people start blogging on Steem - a blockchain platform that gives rewards for social activity. But as with many other things getting rich on Steem is not an easy job. Although everyone can get inspired by top authors who get enjoy success, the real life is much more prosaic, and it may take a long time to get on the top.
And one of the most exciting questions is how success is distributed across the platform? How many users receive a lot of upvotes and steems for their activity? Are there some workarounds that can make the way to the top easier? Or maybe actually all of the goods go to a small clique?
Sometimes, all of this questions can be answered by a simple statistical analysis that for example counts the distribution of important variables or searches for correlations between some factors such as the number of users outgoing comments and number of likes. But unfortunately, most of the data about steemians activity varies greatly. For example, let's look at the distribution of a post upvotes number:
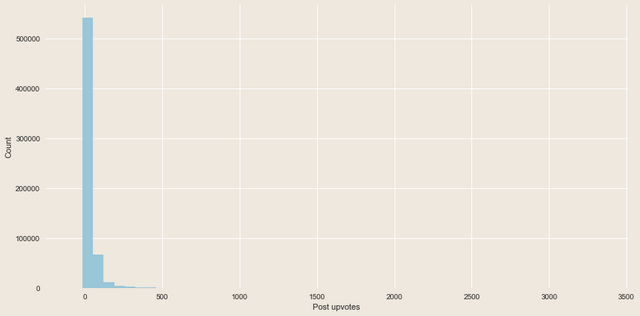
As we can see, most of the posts receive a minimal amount of upvotes, but some of them get thousands. The same thing happens if we try to plot the posts payouts distribution:
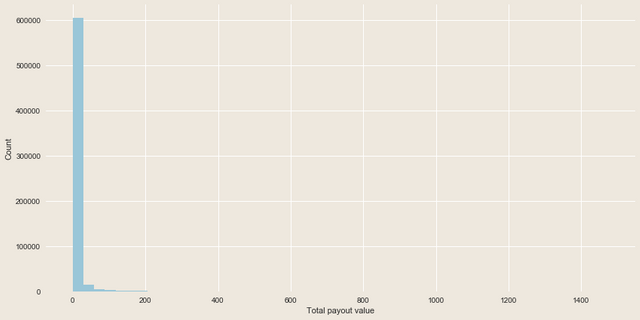
And since this variables are not always codependent, it would be difficult to manually divide data into subgroups.
Fortunately, there are a lot of well-established machine learning methods that can divide tangled data into the meaningful subgroups. So I've decided to run one of them - KMeans clustering algorithm - on the dataset consisting of info about the post published between 1 and 30 April and share the results with you.
Data
Data used in this research consists of 628633 rows which represent posts and has the following columns: author, total payout value (author + curators rewards), votes count, comments count and author reputation. After data collection, I calculated statistics for each author presented in the dataset. These statistics include median values of comments and votes count as well as median payout values for each author's post.
Overall, there are 59 204 authors presented in the dataset. It has the following structure:
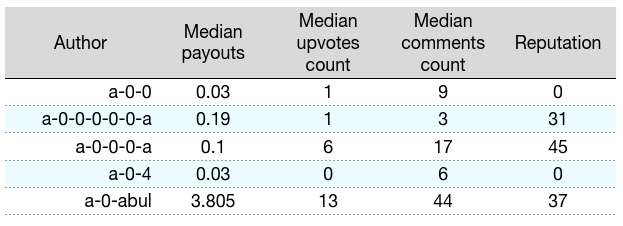
Eventually, recieved authors data was divided into 7 clusters by the KMean algorithm.
Results
After running KMeans, I got the following results:
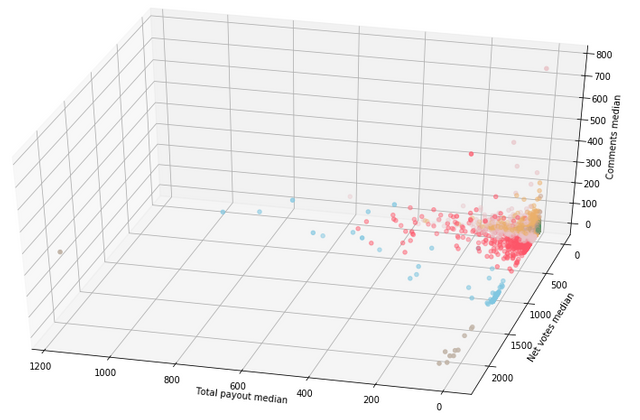
As we can see from this plot, two subgroups (highlighted by blue and grey) can be separated merely from other authors due to very high median upvotes count. But the other subgroups form a dense 'core' and haven't visibly separable boundaries.
But if we will look at the following table, we will see these subgroups have clear differences, so let's examine them closely:
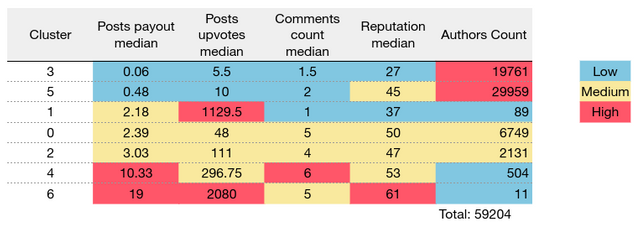
All of the groups that have a normal count of upvotes divides into three categories. Cluster #3 most likely represents newbies as users in this group have a low reputation. Cluster #5 looks more intriguing as users in this group have higher reputation score but relatively small payouts. It would be interesting to know your suggestions why can't these users get more attention from steemians.
Clusters #0 and #2 forms a "middle class" of the platform. They have average values for all of the variables. The only difference between clusters is in a votes count. It is interesting that although the median votes count in the second group twice as much first, the median payout differs only insignificantly.
Cluster #4 represents "rich and famous" of Steem. These authors have much higher median payouts and upvotes count. But the latter number doesn't exceed few hundreds. They also have highest median comments count. It can signify that these users rely more on readers sympathy than the usage of upvote services.
The remaining two groups have a common feature: very high number of upvotes, which can be related to the usage of bots and paid upvotes services. After the closer look at the cluster #6
we can see that this small subgroup of 11 users consists mostly of users that are related to the service named shadowbot, such as @jonbit.
Eventually, the last cluster (#1) also consists mostly of upvote services user, but their achievements are more modest than in the previous group. Another interesting feature of this group is that it includes a lot of russian-speaking users:
Summary
Although this analysis is very simple, I assume we can infer some interesting results from it.
Steem society have relatively well-defined subgroups of bottoms, middle class, and upper class
These subgroups are diverse too and have several subclusters with different behavior strategies
We can see that more than two-thirds of users don't have much success on Steem. One-third of users looks like minnows, 50% looks like more experienced users but have low median payouts
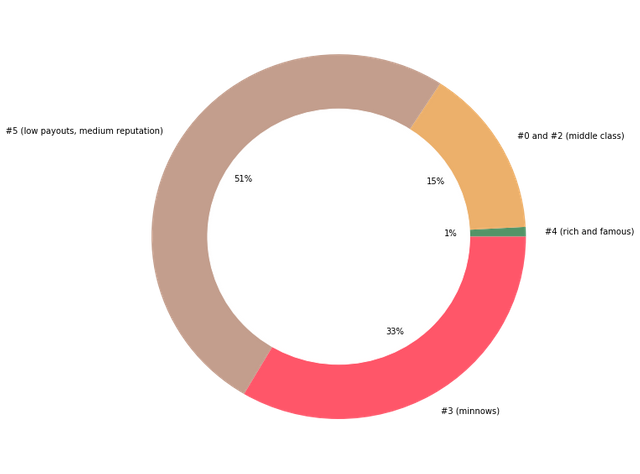
15% of users have average values. And only one percent of users are having the top stats.Some subgroups of users that use paid upvote services can be easily separated from other users. Moreover, maybe, a larger number of clusters can reveal more such subclusters in the overall community.
Future directions
I prefer that such kind of analysis gives us a good starting point for more detailed research of Steem community. It will be very interesting to try to find possible correlations between community subgroups and variables that define social activity (e.g., number of posts in a week or voting patterns).
I also should say about limitations of the presented analysis:
- Amount of data. Dataset used in this analysis includes an only small proportion of posts published on Steem, so I'm not sure that we can extrapolate these finding on the total amount of data. I also dropped small part of data describing posts with very little payout values (<0.0001)
- The number of subgroups. This value was chosen based on elbow rule which is not the best estimation method. So maybe a greater number of clusters can give us a better result.
- Limitations of the algorithms. Sometimes KMeans clustering can't give the best result due to some data features. Therefore, there is a need for comparison with results of other algorithms
Resteemed to over 18200 followers and 100% upvoted. Thank you for using my service!
Send 0.200 Steem or 0.200 Steem Dollars and the URL in the memo to use the bot.
Read here how the bot from Berlin works.
#resteembot #bestofresteembot
Feel free to join our partner crypto exchange: https://www.binance.com/?ref=10230705.
@resteem.bot
Congratulations @ninjas! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOPSTOP
Notifications have been disabled. Sorry if I bothered you.
To reactivate notifications, drop me a comment with the word
NOTIFYCongratulations @ninjas! You have received a personal award!
Click on the badge to view your Board of Honor.
Do not miss the last post from @steemitboard!
Participate in the SteemitBoard World Cup Contest!
Collect World Cup badges and win free SBD
Support the Gold Sponsors of the contest: @good-karma and @lukestokes