R을 이용하여 파일로부터 문서를 읽어 WordCloud 그려보기
지난(3.18) 포스팅(https://steemit.com/gartner/@hironlee/5-top-10-strategic-technology-trends-from-gartner-inc) 에 이어, R(RStudio)을 이용하여 최근 5년간의 전략기술 트렌드를 다룬 뉴스의 내용을 읽어 들여, 많이 언급된 단어의 빈도 순으로 크기를 조절하여 WordCloud를 만들어 보는 실습을 해보았습니다.
결과 WordCloud

사용한 R Package 목록
- KoNLP : 한글 자연어 처리 패키지 (Korean Natural Language Processing)
- wordcloud : 주어진 데이터를 WordCloud 형태로 그리는 패키지
- rvest : 웹페이지를 크롤링하는 패키징, 간단히 사용만 해봤으며, 디테일한 크롤링은 안해 봄
- RColorBrewer : R시각화 패키지
사용한 주요 함수
- readLines(szFileName)
• szContents <- readLines(szFileName)
• szFileName 경로의 파일을 한 라인단위로 읽어 들이기 - gsub("찾을단어","바꿀단어",szContents)
• szContents <- gsub("AI","인공지능",szContents) : “AI” 라는 단어를 “인공지능”으로 치환
• szContents <- gsub("'","",szContents) : “’” 특수문자를 공백으로 치환
• 등 문장 중 특정 단어를 치환, 필터링 하는 함수 - sapply(szContents, extractNoun, USE.NAMES=F)
• 각 라인에서 명사 단어만 가져오기 - display.brewer.all() : 제공 색상타입 모두 보기
- wordcloud(….) : WordCloud 그리는 함수
• scale : 빈도가 가장 큰 단어와 가장 빈도가 작은 단어 폰트 사이 크기, scale=c(5,0.2)
• rot.per=0.1 : 90도 회전해서 보여줄 단어 비율
• min.freq=3, max.words=100 : 빈도 3이상, 100미만 단어 표현
• random.order=F : True(랜덤배치) / False(빈도수가 큰단어를 중앙에 배치)
• random.color=T : True(색상랜덤) / False(빈도수순으로 색상표현)
• colors=brewer.pal(11, "Paired") : 11은 사용할 색상개수, 두번째는 색상타입이름, 색상타입은 display.brewer.all() 참고
• family : 폰트 - savePlot(szWordCloudImageFile, type="png") : WordCloud 결과를 이미지 파일로 저장
R 소스코드
# 필요 Package 설치
install.packages("rvest") #웹페이지 크롤링을 위한 패키징
library("rvest")
szPostUrl1 <- "http://www.itworld.co.kr/news/106768"
szPostData1 <- read_html(szPostUrl1)
# 전체 페이지 크롤링은 쉬우나, 특정 영역 크롤링은 간단하지 않으므로 우선 Pass, 다음에 실습 예정
# 필요 Package 설치
install.packages("KoNLP") #한글 자연어 처리 패키지 (Korean Natural Language Process)
install.packages("wordcloud") #wordcloud 패키지
install.packages("RColorBrewer")
# Library 로드
library("KoNLP")
library("wordcloud")
library("RColorBrewer")
useSejongDic() #한글 세종사전
szFileName <- "D:\Documents\R\RStudy\data\Gartner_2014_18_TechTrend.txt"
szWordSaveFileName <- "D:\Documents\R\RStudy\data\Gartner_2014_18_TechTrend_Word.txt"
szWordCloudImageFile <- "D:\Documents\R\RStudy\data\Gartner_2014_18_TechTrend_Word.png"
szContents <- readLines(szFileName) # 기사를 담은 파일에서 한 라인씩 읽어들이기
View(szContents) # 파일 내용 확인 (아래 그림1 참고)
# 불필요한 문자 필터링, 치환
szContents <- gsub("'","",szContents)
szContents <- gsub("‘","",szContents)
szContents <- gsub(""","",szContents)
szContents <- gsub("“","",szContents)
szContents <- gsub("”","",szContents)
szContents <- gsub("기술","",szContents)
szContents <- gsub("가트너는","",szContents)
szContents <- gsub("하게","",szContents)
szContents <- gsub("10","",szContents)
szContents <- gsub("들이","",szContents)
szContents <- gsub("하기","",szContents)
szContents <- gsub("부사장","",szContents)
szContents <- gsub("가지","",szContents)
szContents <- gsub("AI","인공지능",szContents)
szNounsContents <- sapply(szContents, extractNoun, USE.NAMES=F) #각 라인마다 명사단어들만 남기기
View(szNounsContents)
szNounsContentsList <- unlist(szNounsContents) #단어들만 가져오기
View(szNounsContentsList)
# 2글자 이상의 단어만 필터링
szLastData <- Filter(function(x) {
nchar(x)>=2
},szNounsContentsList)
## 최종 2글자 이상의 단어들의 목록
View(szLastData) ## 목록 확인 (아래 그림2 참고)
write(szLastData, szWordSaveFileName) # 결과 목록을 파일로 저장
szDataTable <- read.table(szWordSaveFileName)
View(szDataTable)
ListWordCount = table(szDataTable) # 테이블형태 변환해서 저장
View(ListWordCount) ## 테이블 형태로 저장 (아래 그림3 참고)
#### Word Cloud 그리기..
windows()
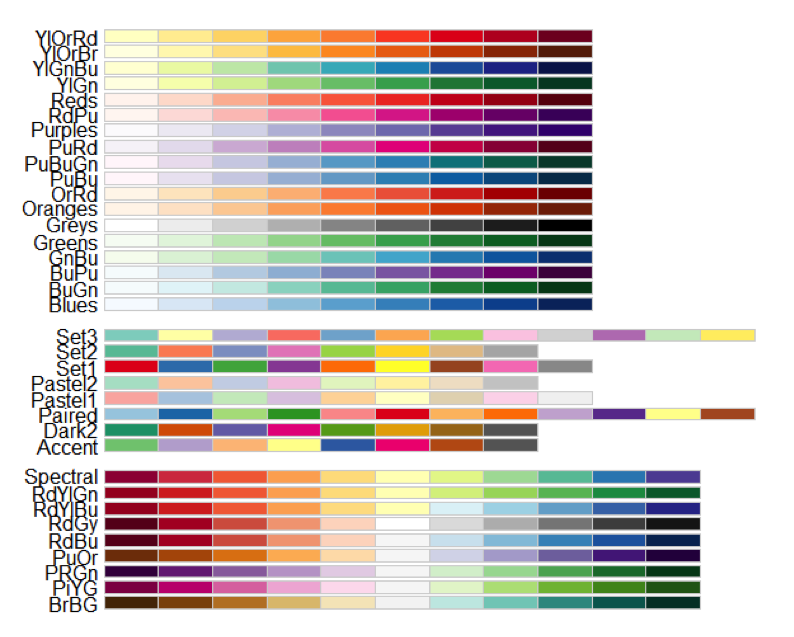
display.brewer.all() # 제공 색상타입 모두 보기 (아래 그림4 참고)
windowsFonts(font=windowsFont("맑은 고딕"))
### Word Cloud 함수 호출
wordcloud(
names(ListWordCount),
freq=ListWordCount,
scale=c(5,0.2), #빈도가 가장 큰 단어와 가장 빈도가 작은단어 폰사 사이 크기
rot.per=0.1, #90도 회전해서 보여줄 단어 비율
min.freq=3, max.words=100, # 빈도 3이상, 100미만
random.order=F, # True : 랜덤배치, False : 빈도수가 큰단어를 중앙에 배치
random.color=T, # True : 색랜덤, False : 빈도순
colors=brewer.pal(11, "Paired"), #11은 사용할 색상개수, 두번째는 색상타입이름
family="font")
## 최종 이미지파일로 저장
savePlot(szWordCloudImageFile, type="png”)
그림 1) : 문서 파일로부터 한 라인씩 읽어 들인 목록

그림 2) : 문서에서 2글자 이상의 단어들로만 재구성한 목록

그림 3) : 테이블 형태로 빈도 포함한 단어 목록
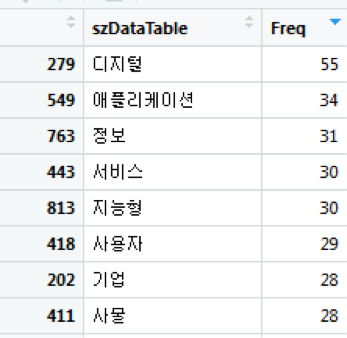
그림 4) : display.brewer.all() 함수 호출을 통해 확인할 수 있는 색상타입 목록 전체
Reference
- https://cran.r-project.org/web/packages/wordcloud/
- https://cran.r-project.org/web/packages/KoNLP/
- https://cran.r-project.org/web/packages/RColorBrewer/
**) 테스트에 사용된 기사모음 파일 : Gartner_2014_18_TechTrend.txt 파일 다운로드
****** 2018.3.25 이호철([email protected])
Love this! Nice use of color and placement. Keep up the great work.
Thank you for your praise. ^^ Have a nice day.
Great! This is really helpful for me!!