Learn how to program with Python #4 - Solving Puzzles from Advent of Code 2018

Repository
What will I learn
- What are defaultdicts?
- Extracting arguments with re.search
- Retrieving the max value of a dict
Requirements
- Python 3.7.2
- Pipenv
- git
Difficulty
- basic
Tutorial
Preface
This tutorial is part of a course where solutions to puzzles from Advent of Code 2018 are discussed to explain programming techniques using Python. Each puzzle contains two parts and comes with user specific inputs. It is recommended to try out the puzzle first before going over the tutorial. Puzzles are a great and fun way to learn about programming.
While the puzzles start of relatively easy and get more difficult over time. Basic programming understanding is required. Such as the different type of variables, lists, dicts, functions and loops etc. A course like Learn Python2 from Codeacademy should be sufficient. Even though the course is for Python two, while Python 3 is used.
This tutorial will look at puzzle 4
The code for this tutorial can be found on Github!
Puzzle 4
This puzzle is about guards that are performing a shift and fall asleep during that shift. Somebody has spied on the guards and for each guard, the guard id, the moment the guard falls asleep and when the guard wakes up again are recorded. The idea is to analyse this information to think of a plan to circumvent the guard.
Part one
Strategy 1: Find the guard that has the most minutes asleep. What minute does that guard spend asleep the most? What is the ID of the guard you chose multiplied by the minute you chose?
Taken from the puzzle question the total amount of minutes and the frequency per minute are needed to answer this question. To store this data defaultdicts will be used.
What are defaultdicts?
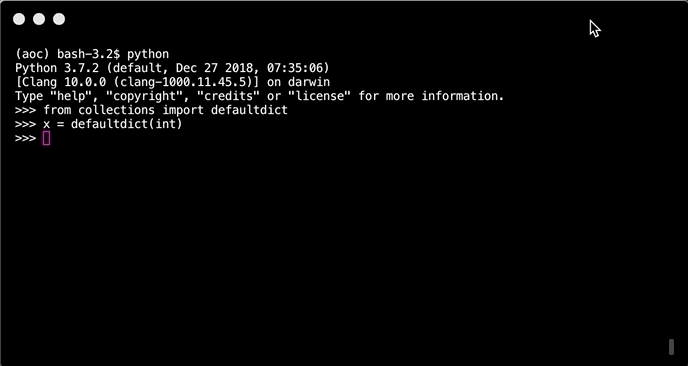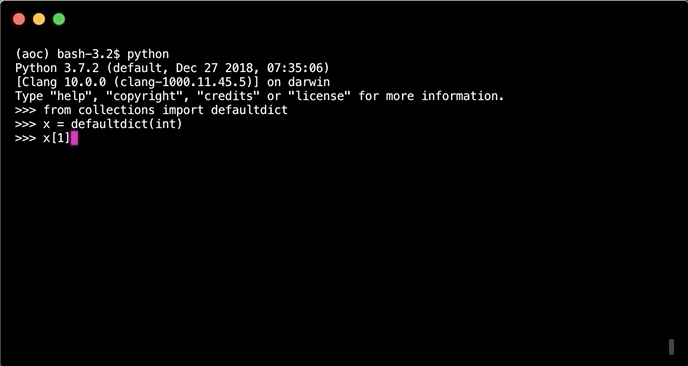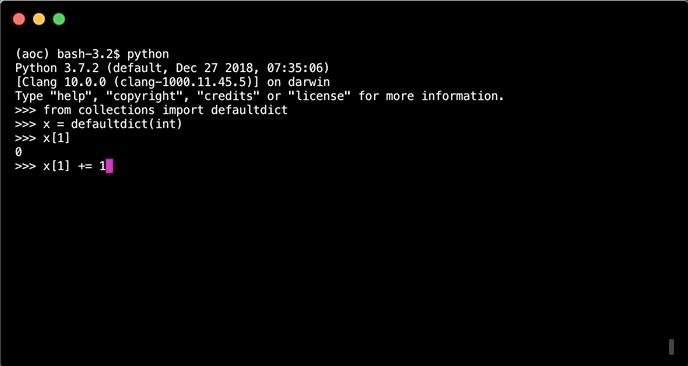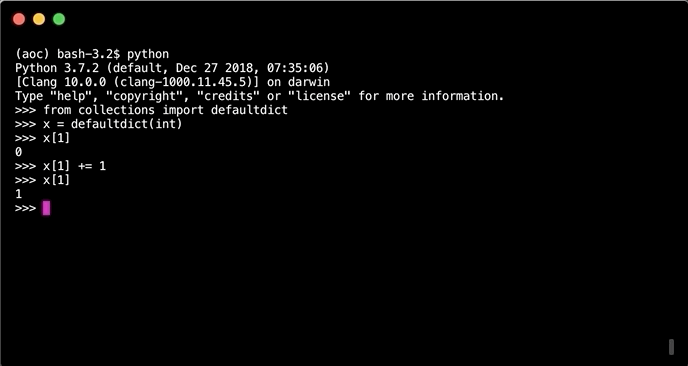
Unlike normal dicts when creating a new key, value pair or asking for a key that does not exist. Insteed of an error a default value will be returned or set. In the case one wants to increment a value inside the dict. If the key does not exist it will be added to the default value.
from collections import defaultdict
# totals holds the total amount of minutes a guard has spent sleeping
# frequency holds the frequency per minute (0-59) for each guard
totals = defaultdict(int)
frequency = defaultdict(lambda: defaultdict(int))
In python lamba is used to pass a function. In this case it creates a new defaultdict when the default value is called. Thereby creating a nested dict structure. However, the nested dict is not created until the the first time a new key is called.
Extracting arguments with re.search
The input for this puzzle has again become more complicated than seen so far. It is important to note that there is always only 1 guard on duty. The minute the guard falls asleep is included and the minute the guard wakes up is not. All guards only sleep between 0:00 and 0:59.
[1518-11-01 00:00] Guard #10 begins shift
[1518-11-01 00:05] falls asleep
[1518-11-01 00:25] wakes up
Each line contains a timestamp and an action. There are three different actions. When a guard starts a shift, the guard ID has to be extraced. If asleep or wakes is inside the line the start and end minute can be extracted.
# sort lines by timestamp
for line in sorted(lines):
# parse minute
minute = int(re.search(r':(\d+)', line).group(1))
if '#' in line:
guard = int(re.search(r'#(\d+)', line).group(1))
# guards falls asleep, minute included
elif 'asleep' in line:
start = minute
# guard wakes up, minute not included
elif 'wakes' in line:
end = minute
# for each minute add to totals and frequency
for m in range(start, end):
totals[guard] += 1
frequency[guard][m] += 1
The input does not come sorted. Python is clever enough to recognize the timestamp at the start of each line. To sort the input only sorted() had to be applied to the list of lines. Extracting the minute and guard id is done by using re.search(). Which requires a pattern and a string. r':(\d+) takes all digits after the : and r'#(\d+)' does the same but after a #. This functions returns a match object, to retrieve the value group(1) has to be called on the object.
When the input is sorted, whenever a guard wakes up all data for this shift is done and the guard can be added to the dicts. This is done for the range start, end. Which included the start minute but excludes the end minute.
Retrieving the max value of a dict
To solve the first puzzle the guard that has the most minutes of sleep has to be found and the minute this guard has been asleep the most. Since the data is inside dicts using a max() function is not as straight forward.
.items() returns the a list of tuples (key, value).
dict_items([(661, 498), (1663, 512), (419, 439), (859, 408), (2383, 216), (997, 466), (1367,
348), (61, 148), (3407, 385), (3391, 419), (739, 450), (2221, 253), (2297, 391), (2113, 198),
(1163, 323), (3203, 337), (733, 570), (113, 151), (2609, 222), (2713, 194)])
To retrieve the max value for the value an itemgetter can be used and passed as the key to the max() function.
from operator import itemgetter
def part_1(totals, frequency):
key = itemgetter(1)
guard = max(totals.items(), key=key)[0]
minute = max(frequency[guard].items(), key=key)[0]
return guard * minute
itemgetter(1) sets the index to 1, that of the value. Since the actual max value is not required, it just needs to be sorted by this value. [0] retrieves the first element.
What is the ID of the guard you chose multiplied by the minute you chose?
The answer can then be calculated with: guard * minute
Part two
Strategy 2: Of all guards, which guard is most frequently asleep on the same minute? What is the ID of the guard you chose multiplied by the minute you chose?
Solving this puzzle can be done by looping through all the guards inside the frequency dict. For each guard retrieve the minute with the heigest frequency and store that with the score (guard ID * minute). At the end sort the list and retrieve score associated with the highest frequency.
def part_2(frequency):
items = []
key = itemgetter(1)
# for each guard retrieve the minute with the highest
# frequency. Store freq and score (guard * minute)
for guard in frequency:
minute, freq = max(frequency[guard].items(), key=key)
items.append((freq, guard * minute))
# return by highest frequency
return sorted(items)[-1][1]
By default sorted() will look at the first value inside the set to sort the list of sets. And sorts from low to high.
before
[(14, 21813), (14, 51553), (13, 14246), (12, 36937), (7, 69107), (19, 37886), (12, 58781), (7, 2196), (12, 126059), (13, 125467), (16, 35472), (8, 71072), (13, 84989), (5, 71842), (9, 38379), (10, 99293), (17, 35184), (5, 3164), (8, 62616), (7, 116659)]
after sorted()
[(5, 3164), (5, 71842), (7, 2196), (7, 69107), (7, 116659), (8, 62616), (8, 71072), (9, 38379), (10, 99293), (12, 36937), (12, 58781), (12, 126059), (13, 14246), (13, 84989), (13, 125467), (14, 21813), (14, 51553), (16, 35472), (17, 35184), (19, 37886)]
The wanted value is at the end of the list, index [-1] and is the 2nd item in the set, index [1].
Running the code
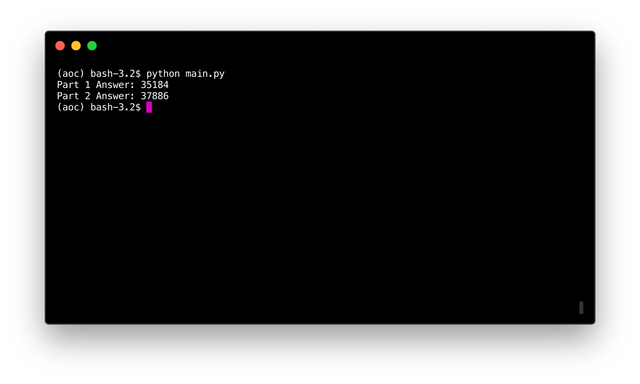
Run the code with: python main.py
if __name__ == "__main__":
# parse input into totals and frequency dicts
totals, frequency = parse_input()
print(f'Part 1 Answer: {part_1(totals, frequency)}')
print(f'Part 2 Answer: {part_2(frequency)}')
Curriculum
The code for this tutorial can be found on Github!
This tutorial was written by @juliank.
Thank you for your contribution @steempytutorials.
After reviewing your tutorial we suggest the following points listed below:
Your tutorial is very interesting in helping to solve a puzzle with code.
Your tutorial is very well structured and explained. It's very nice to be careful to write the text for readers who may not be very experienced in python language.
We suggest that you put the title a little less extensive, but that contains the key words of what you will explain in your tutorial.
Good work on developing this tutorial, we look forward to your next contribution.
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Chat with us on Discord.
[utopian-moderator]
Thank you for your review, @portugalcoin! Keep up the good work!
Congratulations! Your post has been selected as a daily Steemit truffle! It is listed on rank 23 of all contributions awarded today. You can find the TOP DAILY TRUFFLE PICKS HERE.
I upvoted your contribution because to my mind your post is at least 10 SBD worth and should receive 249 votes. It's now up to the lovely Steemit community to make this come true.
I am
TrufflePig, an Artificial Intelligence Bot that helps minnows and content curators using Machine Learning. If you are curious how I select content, you can find an explanation here!Have a nice day and sincerely yours,

TrufflePigHi @steempytutorials!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your post is eligible for our upvote, thanks to our collaboration with @utopian-io!
Feel free to join our @steem-ua Discord server
Thanks for your information, you have given very useful and important information.
https://nareshit.com/python-online-training/
Hey, @steempytutorials!
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Get higher incentives and support Utopian.io!
Simply set @utopian.pay as a 5% (or higher) payout beneficiary on your contribution post (via SteemPlus or Steeditor).
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!