Connect to multiple STEEM nodes in parallel to validate blocks

Repository
What will I learn
- Retrieve blocks via an API
- Connect to multiple nodes
- Thread synchronisation
- Returning data to the main thread
- Processing data from the worker threads
Requirements
- Python 3.7.2
- Urllib3
- Pipenv
Difficulty
- intermediate
Tutorial
Preface
STEEM allows for easy access to data from its Blockchain via the API that is publicly available. The downside of using one public API node is that the data can be compromised. When building an application that is dealing with important data to make financial decisions the reliability can be increased by connecting to multiple nodes and comparing the data from each node. This way one does not have to set up a full node, which can be expensive.
Setup
Download the files from Github and install the virtual environment
$ cd ~/
$ git clone https://github.com/Juless89/steem_api_verification.git
$ cd steem_api_verification
$ pipenv install
$ pipenv shell
Retrieve blocks via an API
For this tutorial the http library urllib3 is used. However, any http library should do the job. To request a block from a steem node a POST request has to be made that contains the following parameters.
PARAMS = {
"jsonrpc": "2.0",
"method": "block_api.get_block",
"params": {"block_num": self.block_num},
"id": 1
}
Important to note are the method, which sets which API function to be called, in this case block_api.get_block, more API functions and information can be found in the official API docs, and the params, which for this API function sets the block number to be requested. The id is returned as is and can be used to keep track of which thread made a specific API call.
The request can now be made. POST sets the type of request, the url is the url to the steem node and the PARAMS are passed as body. The PARAMS dict has to be converted to a string with json.dumps() and encoded with encode().
http = urllib3.PoolManager()
url = 'https://api.steemit.com'
r = http.request('POST', url, body=json.dumps(PARAMS).encode())
data = json.loads(r.data.decode())
The reply is an encoded string that needs to be decoded with decode() and converted to a dict with json.loads() for easy access. The reply has the following structure where result contains the block data. For this example the block data has been removed.
{
'jsonrpc': '2.0',
'result': {},
'id': 1
}
When requesting a block that does not exist yet result will be empty.
Connect to multiple nodes
This tutorial will be using the following nodes. These nodes are not the only ones and can be swapped out for different ones.
nodes = [
'api.steemit.com',
'api.steem.house',
'appbasetest.timcliff.com',
'rpc.steemviz.com',
'steemd.privex.io',
'rpc.usesteem.com',
]
Creating a class allows for threading and creating separate instances for each node. To create a thread class, the class must inherit from threading.Thread. In addition in the __init__ function, threading.Thread.__init__(self) has to be added. Each Node class is initialised with a url and a queue. Where the url is the node url and the queue is an object that is used to share data between threads. It includes all locking mechanisms to prevent data corruption. Data can be added by calling queue.put() and retrieved by calling queue.get().
import threading
import queue
class Node(threading.Thread):
def __init__(self, url, queue):
threading.Thread.__init__(self)
self.block_num = None
self.url = url
self.queue = queue
self.http = urllib3.PoolManager()
def get_block(self):
# function to retrieve block from the api
def run(self):
# loop function that is called when the thread is started
# should manage the thread
All the threads are created by looping over the node list. Each thread has a unique url and share the same queue. The threads are stored inside the threads list. .start() calls the run function inside the class.
# threads list and queue object
threads = []
queue = queue.Queue()
# create worker for each api, start and store
for node in nodes:
worker = Node(node, queue)
worker.start()
threads.append(worker)
The node threads will be referred to as worker threads, while thread that created the worker threads will be referred to as the main thread. The processing of the data retrieved from the worker threads will be done inside the main thread.
Thread synchronisation
Threads are separated from each other, which makes communication between threads limited. Shared data objects like the queue allow for shared data between threads. However, to prevent data corruption, in the case multiple threads write to the same data object, locking is implemented which makes threads have to wait for each other.
To prevent locking a different solution will be used to update the threads on which block they have to retrieve. A global variable block_num is initialised in the main file. Then from within the class this variable can be accessed by calling global block_num.
def run(self):
# global current block counter
global block_num
# check if the global block counter has been changed
# if so retrieve block via api and put into queue
while True:
if block_num != self.block_num:
self.block_num = block_num
if block_num != None:
block = self.get_block()
self.queue.put(block)
time.sleep(.1)
When the thread is initialised it sets global block_num. Then a loop gets created where the global block_num is compared with the local block_num. When this is different the block will be retrieved and put in the queue for the main thread to process. This works as the main thread is the only one changing the global block_num, the worker threads only read it. After each loop the worker thread sleeps for .1 seconds, this reduces stress on the cpu.
Returning data to the main thread
When data is stored inside the queue, the main thread does not know which thread stored this data. Therefor a set is returned which contains the node url, the block_num and the block data. In case of any exceptions None is returned instead of block data. This guarantees a response from each worker thread.
# Perform API call to get block return None for non existing blocks and
# any exceptions.
def get_block(self):
# API request
PARAMS = {
"jsonrpc": "2.0",
"method": "block_api.get_block",
"params": {"block_num": self.block_num},
"id": 1
}
url = 'https://' + self.url
try:
# perform and decode request
r = self.http.request('POST', url, body=json.dumps(PARAMS).encode())
data = json.loads(r.data.decode())
# Empty result for blocks that do not exist yet
if len(data['result']) == 0:
return (self.block_num, url, None)
return (self.block_num, url, data)
# retun None for any exceptions
except Exception:
return (self.block_num, url, None)
The set in then put inside the queue
block = self.get_block()
self.queue.put(block)
Processing data from the worker threads
The main thread waits until the queue reaches the size of the amount of nodes. This works as every worker thread is set up to reply, even when the api call fails.
while True:
# when the queue reaches the same size as the amount of nodes
# empty the queue
if queue.qsize() == len(nodes):
# process
else:
time.sleep(0.1)
All replies are removed from the queue, checked to be valid, and if so stored inside storage.
storage = []
# Check if block has been retrieved successfully store in storage
for x in range(len(nodes)):
block = queue.get()
if block[2] != None:
storage.append(block)
else:
print(block[1], block[0], 'Not valid')
The order in which the worker threads reply is non deterministic. Meaning, that the order is random. To keep comparing all blocks simple, the blocks are compared against the first block received. In the case the first block is corrupted the block will be retried. When blocks are the same, the score get increased by 1.
# Extract and compare block data
data = [x[2] for x in storage]
score = 0
# Check block data against the first block that has been
# received. As this is non deterministic, in case of a corrupted
# block, the order should be different when a retry is needed.
for x in data[1:]:
if x==data[0]:
score += 1
When all blocks are compared the final score is calculated. For this example a threshold of .75 is selected, meaning that if 75% of the received blocks are the same the main thread will go on to the next block.
# Calculate how many blocks are the same
final_score = (score+1)/len(nodes)
print(f'Block: {block_num} Score: {final_score}')
# When the score is higher than a certain treshhold go on to the
# next block. If not reset the global block num. Wait for the workers
# to update and retry.
if final_score > 0.75:
block_num += 1
else:
temp = block_num
block_num = None
time.sleep(0.5)
block_num = temp
Since the worker threads check for a difference in the global block_num, when the same block has to be retried this would fail the check. Therefor, the block_num is first set to None, then the main thread waits for the workers to update and then sets the block_num to the old value.
Running the code
The main file takes in one argument: block number
python main.py 25000000
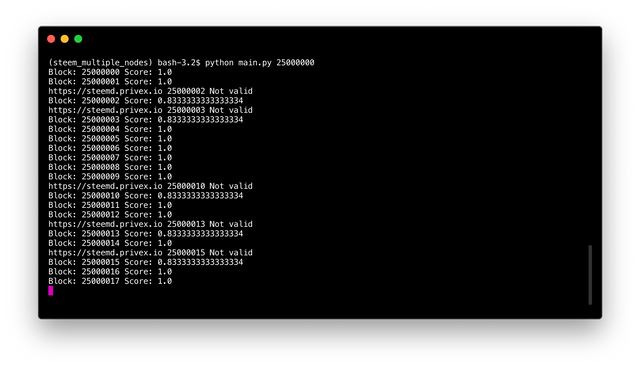
A not valid block does not mean the node has corrupted the block, it can also mean the node failed to deliver the block. As no difference has been made in the code.
The code for this tutorial can be found on Github!
This tutorial was written by @juliank.
Thank you for your contribution @steempytutorials.
After analyzing your tutorial we suggest the following:
Your tutorial is very interesting and well explained. However, we suggest that in your next tutorial put more screenshots in the course of the contribution.
Thanks for following some suggestions that we indicated in your previous tutorial. This contribution was made more detailed and complete.
Thank you for your work in developing this tutorial.
Looking forward to your upcoming tutorials.
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Chat with us on Discord.
[utopian-moderator]
Thanks for the feedback as always
Thank you for your review, @portugalcoin! Keep up the good work!
Hi @steempytutorials!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your post is eligible for our upvote, thanks to our collaboration with @utopian-io!
Feel free to join our @steem-ua Discord server
Hey, @steempytutorials!
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Get higher incentives and support Utopian.io!
Simply set @utopian.pay as a 5% (or higher) payout beneficiary on your contribution post (via SteemPlus or Steeditor).
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!