Some numbers of the @usernames

1. MOTIVATIONS AND PURPOSE
I have always been attracted by the names of people, asking about their meanings, examining the phonemes and letters that compose them, the number of letters they have, etc. Now it has happened to me with the USERNAMES of the accounts in Steemit.
It is easy to know many usernames of the accounts that we follow or those that follow us, or the accounts that posts or make comments but this do not give a overview of all the usernames that have been chosen until now.
The rules for a valid Steem account username
[a-z][a-z0-9-]+[a-z0-9] :
The first character must be a-z (lower case), the last character can be a-z or 0-9 (lower case letter or number) and second and up to second last can be a-z, 0-9 and '-' (hyphen). The maximum length is 16, and the minimum is 3 characters.
How does an average person choose the username of their Steemit account?
What is clear is that this choice depends on the human psychology that infers some patterns and same random component due to the human psychological diversity.
Each person takes into account their subjective reasons. Some decide to identify the username with their real name or the name of a project; others, perhaps, prefer a symbolic, attractive, evocative username or simply an easy and/or short username.
In any case, this results in a general picture produced by the decisions of all users, which can be examined.
In this analysis I make a simple approximation focusing on two simple variables for all the 888,748 accounts created up to the moment of this analysis.
- The first letter of the username or INITIAL;
- The number of characters or LENGTH of the username.
Some questions I want to answer are:
- How are the statistical distributions for the values of the initials and the lengths?
- Do these distributions vary over time?
- Is there any correlation of these variables with the activity of the account?
2. ANALYSIS OF THE INITIALS
2.1 Average values for all the accounts
The initial of a username is one of the 26 letters (a/z). If we calculate the times that each of these 26 characters appears and calculate the percentages that each letter appears, we obtain:
TABLE 1.
| Initial | num. | % | Initial | num. | % |
|---|---|---|---|---|---|
| a | 74593 | 8,39% | n | 29848 | 3,36% |
| b | 47124 | 5,30% | o | 15858 | 1,78% |
| c | 53405 | 6,01% | p | 35797 | 4,03% |
| d | 49639 | 5,59% | q | 3280 | 0,37% |
| e | 27577 | 3,10% | r | 43827 | 4,93% |
| f | 26627 | 3,00% | s | 87731 | 9,87% |
| g | 29579 | 3,33% | t | 48271 | 5,43% |
| h | 28176 | 3,17% | u | 7423 | 0,84% |
| i | 22343 | 2,51% | v | 16886 | 1,90% |
| j | 46666 | 5,25% | w | 18115 | 2,04% |
| k | 37407 | 4,21% | x | 4527 | 0,51% |
| l | 34974 | 3,94% | y | 11660 | 1,31% |
| m | 76003 | 8,55% | z | 11412 | 1,28% |
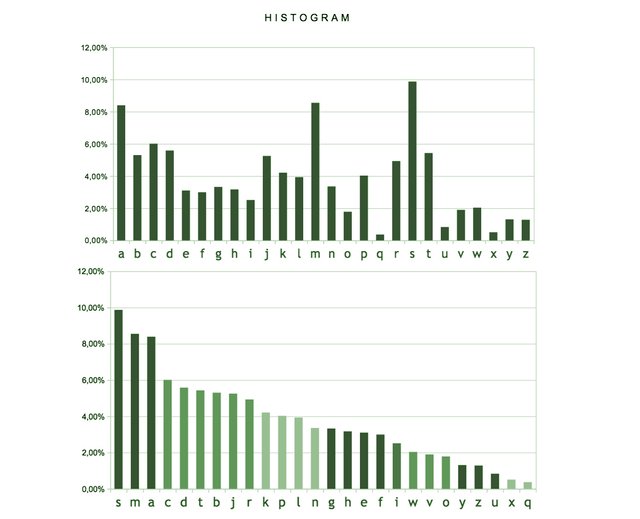
It can be observed that the distribution is not uniform since there are letters that are much more used than others. This is normal since it depends on human psychology that is governed by some patterns.
The letter "S".
The most used letter as initial is the "S" with 87,731 appearances that represent the 9.87% of the total. Does this high demand for the letter "S" as initial of the username represent a tribute or relation to Steem or Steemit?
- The letters "M" with 8.55% and "A" with 8.39% are the following most demanded ones.
- On the opposite side are the letter "Q" with only a 0.37% and the letter "X" with 0.51% of the appearances.
Why does this strange rejection of the letter "Q" as initial happen?* It may be because the combinations of the letter Q with the first four vowels to form Qa-, Qe-, Qi-, Qo- are not abundant or simply do not exist in the language, in comparison with other letters, such as S, in which the combinations Sa-, Se-, Si-, So- exist more.
2.2 Looking for variations in time of the statistical distributions
As one of the conditions when choosing a username for the account is that the username is not picked up by another user it is logical to think that distributions will vary in time.
I have calculated the distributions of the initials for the FIRST 10k and for the LAST 10k accounts
to compare those distributions with the average values for all the usernames..
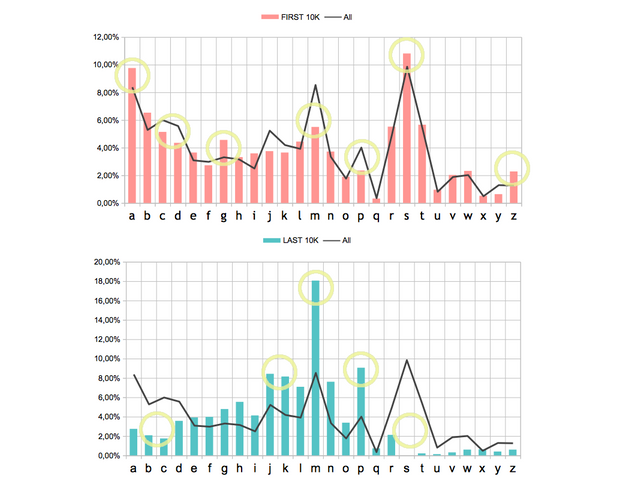
For the FIRST 10k accounts:

- The letter "S" was even more demand reaching 10.81% (compared to AVRG of 9.87% ) and the letter "A" also grows to 9.76% (compared to AVRG of 8.39%)
- The value for the letter"M" decreases to 5.50% (compared to AVRG of 8.55%) and the one for "P" decrease to 2.35% (compared to AVRG of 4.03%)
For the LAST 10k accounts

- There is a large increase of the letter "M" +9,51% compared to the average value.
- A striking decrease of the letter "S" down to 0.00% (9.87%) since in the last 10k accounts no account starting with "S" has been created.
NOTE: What could be the reason for this deviation from the global average values in the first months of Steem?
This anomaly prompted me to examine in detail the accounts created during the first months of operation and before the official launch of Steemit on July 4th, 2016.
I found usernames that caught my attention because of their meaning and I realized that many had been created by @register during 99 days. They refer to brands, companies, famous artists, biblical or mythological characters and words of sexual content. Most of this accounts have no activity in creating posts or comments.
Here I include a selection of usernames to give an idea of why they caught my attention:
@acid, @aerosmith, @antichrist, @bobdylan, @brucelee, @cia, @dracula, @evil, @evil.puppy, @fuck, @freepussy, @god, @hades, @harrypotter, @hercules, @iphone, @ironman, @jesuschrist, @jimihendrix, @johnlennon, @jupiter, @kurtcobain, @lesbian, @madonna, @megatron, @metallica, @michaeljackson, @mickeymouse, @morpheus, @murder , @orgy, @pink-floyd, @playboy, @popcorn, @porn, @prince, @putin, @queen, @reggae, @rocky, @rolex, @santa, @sara, @satan, @scoobydoo, @soccer , @spiderman, @starbucks, @steeminator, @stevejobs, @supergirl, @superman, @tarzan, @vagina, @waltdisney, @yahoo
My hypothesis is that many accounts were created (either for personal motivation or as a task agreed by a team) not to be used in a normal way but to prevent other people from creating and using them. Something like an "inappropriate names policy in Steem" since any Steem account can create other accounts.
Personally, I think this decision is quite logical although there are some of the usernames that I do not understand why they were included in this set or why other words were not included.
2.3 Looking for correlations with the activity of the accounts.
The idea here is to know if the initial of the username is correlated with the activity of the account based on the number of posts that each account have created. The logical thinking says that there is no relationship of one thing with the other, but let's see what the numbers have to say.
I have created two groups of 10k accounts each;
- The HI-ACTV group for those with a high level of activity on posting (more than 1000 posts),
- The LOW-ACTV group for those with a low level of activity (less than 10 posts ordered by descending number of posts)
I have re-calculated the distribution of the variable INITIAL to compare with the mean values.
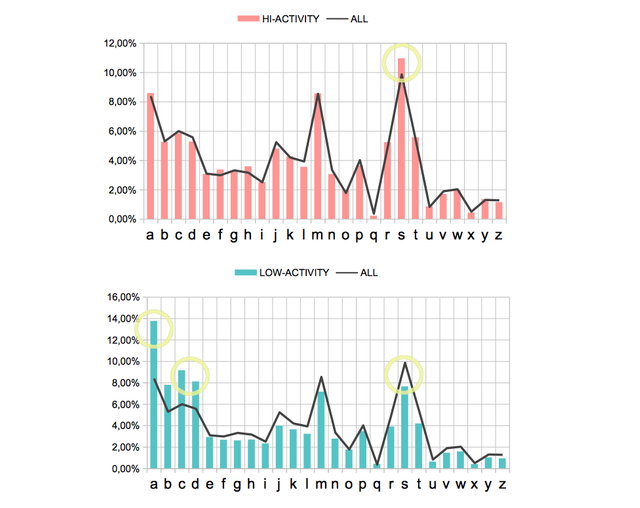
The HI-ACTV group
Do not present variations in their distributions compared to the average values, only highlighting that, again, the letter "S" is a bit more abundant.
The LOW-ACTV group
We see that there are some important variations that show that the letters "A", "B", "C" and "D" are more abundant in this LOW-ACTV group. These increments are:
| A | + 5.36% | |
|---|---|---|
| B | + 2.49% | |
| C | + 3.14% | |
| D | + 2.51% | |
This would mean that statistically the accounts with usernames starting with A, B, C or D, are less active with a higher probability. Or in other words: An account with low activity on posting start with A, B, C or D more likely.
3. ANALYSIS OF THE LENGHT
3.1. Average values for all the accounts
The calculations for the variable LENGTH using all the usernames produce the following table, graph and values.
TABLE 4.
| lenght | Num. accounts | % | lenght | Num. accounts | % |
|---|---|---|---|---|---|
| 3 | 7433 | 0,84% | 10 | 99483 | 11,19% |
| 4 | 21643 | 2,44% | 11 | 82212 | 9,25% |
| 5 | 51716 | 5,82% | 12 | 71886 | 8,09% |
| 6 | 91154 | 10,26% | 13 | 48233 | 5,43% |
| 7 | 108111 | 12,16% | 14 | 35676 | 4,01% |
| 8 | 119363 | 13,43% | 15 | 25858 | 2,91% |
| 9 | 109307 | 12,30% | 16 | 16673 | 1,88% |
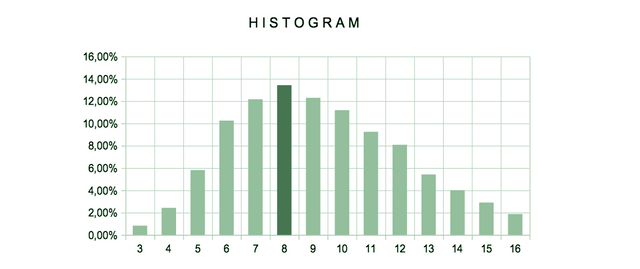
VALUES.
- Number of accounts: 888,748
- Average length: 9.17
- Most repeated value: 8
- Maximum length: 16
- Minimum length: 3
3.2. Looking for variations in time of the lenght
Let's look for variations in time of the distribution of the LENGHT using separately the data for the FIRST 10K and LAST 10K groups used above.
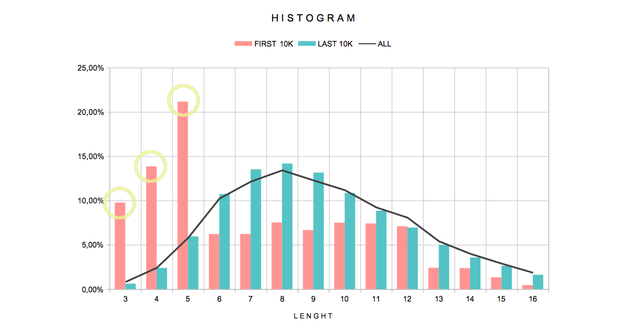
In the first 10k accounts the most repeated value is 5 and there is predominance by low lengths like 3 and 4.
In the last 10k accounts there are few differences with the average values. Perhaps one can highlight an increase of preference for lengths of 7, 8 and 9 characters compared with average values for all times.
This variation in time could be explained by the usual preferences for the shorter usernames that are progressively decreasing and forces users to choose longer usernames, just as it happens with the names of a domain for a website but the truth is that the lengths of 3 and 4 characters are generally poorly demanded, may be because they allow less personalization.
3.3 Looking for correlations with the activity of the accounts.
Repeating the process with the HI-ACTV and LOW-ACTV groups is obtained.
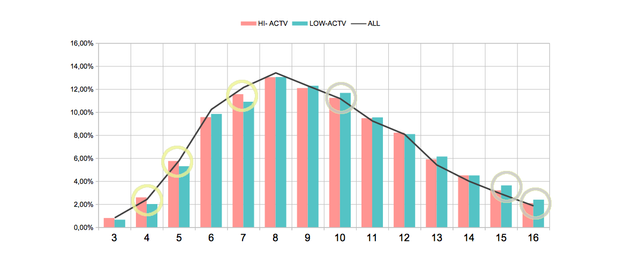
In general, it can be said that there are no major differences between the two groups and at the same time, they have similar values to the global average values, but if someone wanted to highlight some differences, I would say that
- The accounts in the HI- ACTV group show higher values for lengths 4, 5 and 7.
- The accounts in the LOW- ACTV group show higher values for lengths 9,10, 13 and 15.
5. SUMMARY AND CONCLUSIONS
With this simple analysis we now know some things about the first decision that is made when creating an account in Steemit, which is to decide the username.
Deciding the username is governed by psychological aspects and therefore is inferred from repetitive patterns and random components. By using a sufficient number of samples it is possible to observe the patterns that are repeated.
In this case, an approximation is exposed analyzing two simple variables that all the usernames have, which is theirs LENGTHS and INITIALS.
The mean statistical values for the two variables have been calculated and the statistical distributions of these two variables shown by tables and graphs.
INITIALS
- Most frequent: S > A > M
- Less frequent: Q < X < U
LENGTHS
- Most frequent: 8 > 7 > 9
- Less frequent: 3 < 16 < 4
Have been found some clear variations in time for the distributions of the two variables.
Also can be seen some correlations with the activity of the accounts, that have been exposed above in this analysis.
6. SCOPE, TOOLS AND CODE
Scope of Analysis
- Dates of the analysis: 11.04.2018
- Timeframe of the analysed data: 30.03.2016 to 01.4.2018
Tools
I have used KNIME, a free and open-source data analytics, reporting and integration platform, to get, filter and manipulated data from the database SteemData in the Public MongoDB Server created by @furion and Open Office to make graphs.
Workflow
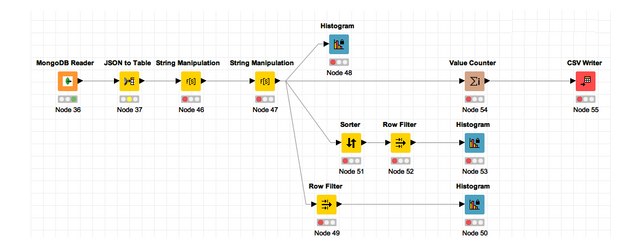
Queries
Using the mongoDB Reader node in KNIME
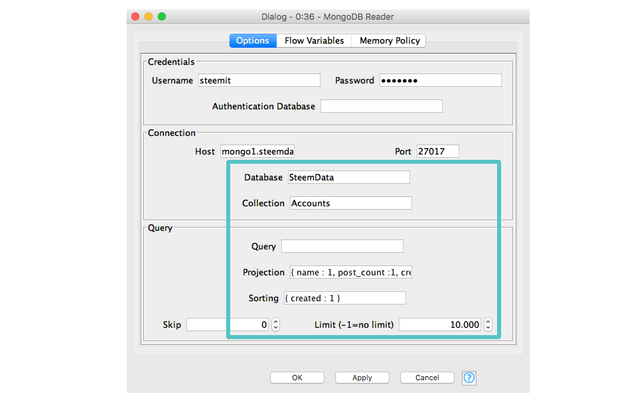
———————————-
Q1: ALL THE ACCOUNTS
Database : StemData
Collections: Accounts
Query:
Projection: { name :1, post_count :1, created :1 }
Sorting: { created :1 }
Limit: -1 (no limit)
———————————-
Q2:LAST 10K GROUP
Database : StemData
Collections: Accounts
Query:
Projection: { name :1, post_count :1, created :1 }
Sorting: { created :-1 }
Limit: 10.000
———————————-
Q3: FIRST 10K GROUP
Database : StemData
Collections: Accounts
Query:
Projection: { name :1, post_count :1, created :1 }
Sorting: { created :1 }
Limit: 10.000
———————————-
Q4: HIGH-ACTIVITY GROUP
Database : StemData
Collections: Accounts
Query: { post_count >1000}
Projection: { name :1, post_count :1, created :1 }
Sorting: { post_count : 1 }
Limit: 10.000
————————————
Q5: LOW-ACTIVITY GROUP
Database : StemData
Collections: Accounts
Query: { post_count <10}
Projection: { name :1, post_count :1, created :1 }
Sorting: { post_count: 1}
Limit: 10.000
———————————-
Thank you.
Posted on Utopian.io - Rewarding Open Source Contributors
Hi @sintoniz, great to see a new contributor in the analysis section! :)
Well done analyzing the user names. I didn't know about KNIME, that looks really cool!
Need help? Write a ticket on https://support.utopian.io.
Chat with us on Discord.
[utopian-moderator]
Thank you! I have recently discovered KNIME and I am very excited about its power and flexibility. It's like a dream come true... and Open Source!
Hey @sintoniz I am @utopian-io. I have just upvoted you!
Achievements
Utopian Witness!
Participate on Discord. Lets GROW TOGETHER!
Up-vote this comment to grow my power and help Open Source contributions like this one. Want to chat? Join me on Discord https://discord.gg/Pc8HG9x