Learn Python Series (#14) - Mini Project - Developing a Web Crawler Part 2
Learn Python Series (#14) - Mini Project - Developing a Web Crawler Part 2

What Will I Learn?
- You will learn how to build a useful real-life web crawler that discovers Steem accounts via the steemit.com website,
- how to think strategically what the most optimal algorithmical solution is by comparing multiple possible programmatical options, how to reason about the pros and cons of each approach, and picking the best one available,
- how to distill the data you need from a wall of code,
- how to use intermediate plain text file storage to read from and save to without needing a database or the Steem API,
- how to modularize your code in functions and execute those functions in the right order.
Requirements
- A working modern computer running macOS, Windows or Ubuntu
- An installed Python 3(.6) distribution, such as (for example) the Anaconda Distribution
- The ambition to learn Python programming
Difficulty
Intermediate
Curriculum (of the Learn Python Series):
- Learn Python Series - Intro
- Learn Python Series (#2) - Handling Strings Part 1
- Learn Python Series (#3) - Handling Strings Part 2
- Learn Python Series (#4) - Round-Up #1
- Learn Python Series (#5) - Handling Lists Part 1
- Learn Python Series (#6) - Handling Lists Part 2
- Learn Python Series (#7) - Handling Dictionaries
- Learn Python Series (#8) - Handling Tuples
- Learn Python Series (#9) - Using Import
- Learn Python Series (#10) - Matplotlib Part 1
- Learn Python Series (#11) - NumPy Part 1
- Learn Python Series (#12) - Handling Files
- Learn Python Series (#13) - Mini Project - Developing a Web Crawler Part 1
Learn Python Series (#14) - Mini Project - Developing a Web Crawler Part 2
In the previous Learn Python Series episode, Mini Project - Developing a Web Crawler Part 1, we learned how to use the Requests and BeautifulSoup4 libraries to get and parse web data. After discussing a few useful properties and methods, we coded a function that returned the latest (max) 20 article post urls for any Steemit user.
Multiple data retrieval steps
However, we finished Mini Project - Developing a Web Crawler Part 1 with having done just "one step": we fetched the latest (<=) 20 article post urls. However, what's really useful about a web crawler is that we can use the fetched data from "step 1" and use that as input for "step 2".
How does a "regular" web crawler (such as GoogleBot) work?
Google's sole objective with its web crawler "GoogleBot" is to find / retrieve as much new web content as possible. The newly found data is then used (in another software process) to analyze and index as the foundation for the search functionality. But that index / search functionality is not the task of a web crawler ("GoogleBot").
How does GoogleBot work, in essence, and can we use the same mechanism for our own web crawler?
The core mechanism of GoogleBot, or any general-purpose web crawler, works as follows:
- start on any page, but preferable a page that contains many hyperlinks to other pages
- get the page contents (and store it, in case of GoogleBot), and distill from it all the hyperlinks (urls) in the page (more or less like we did in
Mini Project - Developing a Web Crawler Part 1) - check if the newly-found hyperlink urls are "new" (not saved / discovered before) and save each of them in a "ToDo list"
- mark the current url as "visited"
- continue the same procedure with the next url on the "ToDo list"
This way, more and more new urls are found, diverging from the start point, intra-domain and cross-domain. As you have now probably understood, the discovery of new content is done purely by following all links on a page, and repeating that process.
Test case: repeatedly discover unique Steem accounts via web crawling Steemit.com
Problem: Not all data is available at the initial pageload due to client-side JS events causing dynamically loading of new data
As explained in the previous episode, the Steemit.com website uses reactJS. At the initial pageload of any Steemit.com page, not all data is loaded. On the contrary, in a browser, when a user clicks a button, or scrolls down a page, a JavaScript method is called that fetches new data (for example older article posts, not initiailly shown). That newly-loaded content is then added to the HTML DOM (Document Object Model) and in a regular browser shown to the user. Lots of other websites are more "static" in nature, meaning most (or all) of teir pages' content is indeed loaded at runtime.
However, for our new Steemit.com web crawler testcase, where the goal is to repeatedly discover unique Steem accounts via web crawling Steemit.com, therefore not using an API connector like steem-python but instead purely relying on web crawling mechanisms, "clicking a button" is not a (simple) option to implement. In order to simulate some user event (like clicking on a "Next" button) we could "dig deep"and find out which events are triggered (client-side, inside the browser) and try to see if we can get the same data via a POST request. We could also set up an additional library containing a so-called headless browser: a real browser, with all the functionality of a normal browser, but it doesn't show anything, but we can automate it. We could then "simulate" user clicks, as if we were inside a real browser. I might cover both of these options in a later episode of the Learn Python Series but for now, let's find another strategy onhow to deal with the problem of "not all data is available at initial pageload".
Alternative web crawler strategies to discover unique Steem accounts
What could be valid ways to discover Steem accounts via web crawling Steemit.com?
Option 1: The most obvious one seems to be fetching accounts from either https://steemit.com/@scipio/followers (followers) or https://steemit.com/@scipio/followed (following). However, since I currently have 972 followers and because the follower page initially shows only 50 followers (the others could be found in a browser by clicking "Next" but as explained we don't have that option available in our Python script right now), and - most importantly - because on every user's /followers page the list is alphabetically sorted in ascending order, we would quickly discover, after fetching / discovering followers from about 300 accounts, that we will have most of the usernames starting with an a, also quite a lot of b's, and some c's, but then the numbers would drop pretty fast. This way, it would be very hard to discover account names starting with a z (such as @zyman, @zulman, @zulfikririsyad, etc.). The exact same problem exists when using the /followed page.
Option 2: Begin at the trending page (https://steemit.com/trending/), save the author account names found there, and also visit and parse the trending article urls themselves and save the article keyword tags found at the bottom of the page. By gathering many keyword tags, we can get more account names (and afterwards more keyword tags) by visiting https://steemit.com/trending/<keyword>. While this approach could work, it seems likely that mostly the same dolphin and whale accounts will be found on the trending pages.
Option 3: More or less the same approach as option 2, but instead of crawling the trending pages (including keyword tags) we can also crawl the New page found on https://steemit.com/created/ and https://steemit.com/created/<keyword>. One big advantage of this approach vs crawling the trending pages, is that the refresh rate of the New pages is much higher than that of the trending pages (meaning we can re-crawl the new pages roughly every 5 minutes) because all new articles can be found here. Another advantage is the much bigger account diversity, meaning we have a higher probability to discover new accounts at every iteration / re-crawl.
Option 4: We can fetch new account names from the /recent-replies page on any account page, for example in my case https://steemit.com/@scipio/recent-replies. The advantage of this mechanism is that it is pretty easy to implement and doesn't require a lot of steps (like is the case with options 2 and 3). One potential downside is that groups of interconnected people oftentimes comment / reply to eachother, because they know eachother (are friends for example) which may cause problems for discovering new account names.
... And of course we could also use both option 3 & 4 strategies!
Nota bene: Of course this is still just a web crawler tutorial, and the test case we're discussing here is intended as an excercise regarding the development of custom web crawlers. But of course we could also use the steem-pyton or beem libraries, and connect to the Steem API and fetch account names from there. Or we could query SteemData's MongoDB collections. But -a- we haven't discussed how to use the Steem API nor -b- use database queries. So we'll stick to using one of the strategy options as discussed above, and develop the web crawler code logic and results.
I choose option 4: fetching new account names from the /recent-replies pages.
Fetching new account names from the /recent-replies pages
First we begin with importing the Requests and BeautifulSoup4 libraries again:
import requests
from bs4 import BeautifulSoup
Next, let's create a function get_commenter_accounts() to which we'll pass account names (beginning with just my own acocunt name scipio) as an argument. The function needs to construct a requests object, fetch all page content using the get() method to which we will pass the account's /recent-replies page. Then we will convert the result string to a bs4 object.
def get_commenter_accounts(account):
url = 'https://steemit.com/@' + account + '/recent-replies'
r = requests.get(url)
content = r.text
soup = BeautifulSoup(content, 'lxml')
return
In order to distill the commenter accounts that replied recently to said account, we must first inspect the page HTML structure to identify which selector to use. Just like we did in the previous episode, open your web browser go to https://steemit.com/@scipio/recent-replies, open the developer console / inspector, point and click a commenter account to select it, and then investigate the DOM using the browser console.

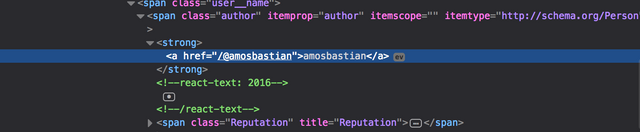
On this page the hyperlink we're interested in doesn't have a class name, so we need to look for a parent element that does have a class and / or id name to select it. It seems the <span> with class="author"> is the most nearby parent element having a class, so let's try to use this to expand our get_commenter_accounts() function, like this:
def get_commenter_accounts(account):
url = 'https://steemit.com/@' + account + '/recent-replies'
r = requests.get(url)
content = r.text
soup = BeautifulSoup(content, 'lxml')
anchors = soup.select('span.author a')
return anchors
anchors = get_commenter_accounts('scipio')
print(anchors, len(anchors))
[<a data-reactid="232" href="/@onderakcaalan">onderakcaalan</a>, <a data-reactid="292" href="/@zoef">zoef</a>, <a data-reactid="352" href="/@androssgb">androssgb</a>, <a data-reactid="412" href="/@amosbastian">amosbastian</a>, <a data-reactid="472" href="/@biddle">biddle</a>, <a data-reactid="544" href="/@mdfahim">mdfahim</a>, <a data-reactid="604" href="/@utopian.tip">utopian.tip</a>, <a data-reactid="664" href="/@utopian-io">utopian-io</a>, <a data-reactid="730" href="/@yandot">yandot</a>, <a data-reactid="790" href="/@onderakcaalan">onderakcaalan</a>, <a data-reactid="850" href="/@idjoe">idjoe</a>, <a data-reactid="910" href="/@utopian.tip">utopian.tip</a>, <a data-reactid="970" href="/@clayjohn">clayjohn</a>, <a data-reactid="1030" href="/@tensor">tensor</a>, <a data-reactid="1090" href="/@yavinlecretin">yavinlecretin</a>, <a data-reactid="1150" href="/@fishmon">fishmon</a>, <a data-reactid="1210" href="/@sanjeevm">sanjeevm</a>, <a data-reactid="1282" href="/@sanjeevm">sanjeevm</a>, <a data-reactid="1354" href="/@gentlemanoi">gentlemanoi</a>, <a data-reactid="1414" href="/@zoef">zoef</a>, <a data-reactid="1486" href="/@utopian-io">utopian-io</a>, <a data-reactid="1552" href="/@utopian.tip">utopian.tip</a>, <a data-reactid="1612" href="/@rahmanovic">rahmanovic</a>, <a data-reactid="1672" href="/@rojibblack">rojibblack</a>, <a data-reactid="1732" href="/@rojibblack">rojibblack</a>, <a data-reactid="1792" href="/@amosbastian">amosbastian</a>, <a data-reactid="1864" href="/@abasifreke">abasifreke</a>, <a data-reactid="1924" href="/@dongentle2">dongentle2</a>, <a data-reactid="1984" href="/@mdfahim">mdfahim</a>, <a data-reactid="2044" href="/@muhammadkamal">muhammadkamal</a>, <a data-reactid="2104" href="/@zoef">zoef</a>, <a data-reactid="2176" href="/@shoganaii">shoganaii</a>, <a data-reactid="2236" href="/@amosbastian">amosbastian</a>, <a data-reactid="2296" href="/@cryptoandcoffee">cryptoandcoffee</a>, <a data-reactid="2356" href="/@utopian-io">utopian-io</a>, <a data-reactid="2422" href="/@utopian.tip">utopian.tip</a>, <a data-reactid="2482" href="/@utopian-io">utopian-io</a>, <a data-reactid="2542" href="/@utopian-io">utopian-io</a>, <a data-reactid="2608" href="/@zoef">zoef</a>, <a data-reactid="2680" href="/@samexycool">samexycool</a>, <a data-reactid="2740" href="/@joenath">joenath</a>, <a data-reactid="2800" href="/@raymondbruce">raymondbruce</a>, <a data-reactid="2866" href="/@kazimyrex">kazimyrex</a>, <a data-reactid="2926" href="/@raymondbruce">raymondbruce</a>, <a data-reactid="2986" href="/@eldahcee">eldahcee</a>, <a data-reactid="3052" href="/@zafaralise">zafaralise</a>, <a data-reactid="3112" href="/@zafaralise">zafaralise</a>, <a data-reactid="3172" href="/@wendie">wendie</a>, <a data-reactid="3232" href="/@kilbride">kilbride</a>, <a data-reactid="3292" href="/@lagosboy">lagosboy</a>] 50
This works just fine! A list of anchors containing the last 50 commenter accounts is given, although all accounts inside the list may not be necessarily unique (less than 50 unique commenter accounts found on the page). Now let's first clean this list up, by iterating over all anchors and distilling the account name. Please also notice that for the account names, I don't want the first two /@ characters every account name begins with in the href:
def get_commenter_accounts(account):
url = 'https://steemit.com/@' + account + '/recent-replies'
r = requests.get(url)
content = r.text
soup = BeautifulSoup(content, 'lxml')
anchors = soup.select('span.author a')
account_list = []
for a in anchors:
# slice away the first 2 characters
commenter_account = a.attrs['href'][2:]
account_list.append(commenter_account)
# make account_list unique by converting to set,
# convert back to a list, and sort that list of unique values
# in an alphabetically ascending order.
account_list = sorted(list(set(account_list)))
return account_list
# call the function
account_list = get_commenter_accounts('scipio')
print(account_list, len(account_list))
['abasifreke', 'amosbastian', 'androssgb', 'biddle', 'clayjohn', 'cryptoandcoffee', 'dongentle2', 'eldahcee', 'fishmon', 'gentlemanoi', 'idjoe', 'joenath', 'kazimyrex', 'mad-karma', 'mdfahim', 'muhammadkamal', 'onderakcaalan', 'rahmanovic', 'raymondbruce', 'rojibblack', 'samexycool', 'sanjeevm', 'shoganaii', 'tensor', 'utopian-io', 'utopian.tip', 'yandot', 'yavinlecretin', 'zafaralise', 'zerocoolrocker', 'zoef'] 31
Cool! As a result, we now have 31 unique account names (instead of 50 we started with), and sorted in an alphabetically ascending order as well.
Intermediate file-based account name storage
Thus far we have created a function get_commenter_accounts() running one time per passed-in account name as its only argument. This function returns an ascendingly sorted alphabetical list of unique account names as found on a user's /recent-replies page (containing maximally 50 unique account names each). For the first iteration, indeed the returned 31 account names are unique.
As a next step, we can now use each of those discovered account names to look on their /recent-replies page to discover new account names from there. However, how do we know that any account name found in a next iteration is indeed 'new' and hasn't been discovered before? We can of course create a new variable, called total_account_list for example and keep that in RAM, but in case something goes wrong, for example when the Python program crashes or even when the entire computer the program runs on shuts down, then all work done before that - hence all accounts discovered - are lost.
Nota bene: Normally, I would store the intermediate results in a database, like MongoDB, but since the Learn Python Series is like an interactive book, I cannot use technical mechanisms I didn't explain before (and properly explaining how to use MongoDB as a document store / NoSQL database isn't exactly done in one or two paragraphs).
So instead, since I have already explained how to store data in regular .txt text files, I will use that. It's surely not as easy, convenient or efficient as using MongoDB (or MySQL for example) would be, but let's use what we know already!
Initiating a base file
To begin with, let's first create and save a new file called todo.txt in the current working directory, and in it (using your code editor) insert and save just my account name, like this:
scipio
Reading and updating account files
The technical strategy I am using is like this:
- I will first pick the first account (in this case my own) from the file
todo.txt, and call thattodo; - then I'll pass that "todo accunt" to the
get_commenter_accounts()function (but I'll be moving the sorting part to another function); - then I'm reading from another file
total.txt(which doesn't exist in the first iteration, so I'll create it) all the accounts that were already discovered, add the "todo account" to the "total list", and compare that "total list" with the newly discovered commenter accounts, then make an alphabetically sorted unique list from it (removing commenter accounts that were already stored in total.txt), and (over)write that total accounts list tototal.txt; - because we do not want to re-visit accounts we already visited, I'm then appending (first step: creating) the "todo account" to
done.txt; - and then we need to update the
todo.txt: by comparing the difference oftotal.txtanddone.txtwe have a newtodo.txtwhich is the disjunct subset of "total" and "done"!
By repeating this procedure in a for loop we have built a real-life web crawler with - at the core - the exact same mechanism as GoogleBot uses to discover new webpages, only we are discovering Steem accounts: without the need of a database, and without the need of a Steem API!
import os
import requests
from bs4 import BeautifulSoup
todo_file = 'todo.txt'
done_file = 'done.txt'
total_file = 'total.txt'
def get_todo(file_name):
file_path = os.getcwd() + '/' + file_name
with open(file_path, 'r') as f:
todo = f.readline()
return todo.rstrip('\n')
def get_commenter_accounts(account):
url = 'https://steemit.com/@' + account + '/recent-replies'
r = requests.get(url)
content = r.text
soup = BeautifulSoup(content, 'lxml')
anchors = soup.select('span.author a')
commenter_list = []
for a in anchors:
commenter = a.attrs['href'][2:]
commenter_list.append(commenter)
#commenter_list = sorted(list(set(commenter_list)))
return commenter_list
def update_total_file(todo, newly_found_accounts, file_name):
# read total.txt and convert to list
file_path = os.getcwd() + '/' + file_name
total_accounts = []
try:
with open(file_path, 'r') as f:
acc_list = f.readlines()
for acc in acc_list:
acc = acc.rstrip('\n')
total_accounts.append(acc)
# if total.txt does not exist, pass
except:
pass
# append the todo-account to total accounts
total_accounts.append(todo)
# combine commenters with total accounts
total_accounts.extend(newly_found_accounts)
# remove double accounts and sort total accounts alphabetically
total_accounts = sorted(list(set(total_accounts)))
# write to total.txt
with open(file_name, 'w') as f:
for account in total_accounts:
f.write(account + '\n')
return len(total_accounts)
def update_done_file(todo, file_name):
# simply append the todo account to done.txt
with open(file_name, 'a') as f:
f.write(todo + '\n')
def update_todo_file(todo_file, total_file, done_file):
# read total.txt and convert to list
file_path = os.getcwd() + '/' + total_file
total_accounts = []
with open(file_path, 'r') as f:
acc_list = f.readlines()
for acc in acc_list:
acc = acc.rstrip('\n')
total_accounts.append(acc)
# read done.txt and convert to list
file_path = os.getcwd() + '/' + done_file
done_accounts = []
with open(file_path, 'r') as f:
acc_list = f.readlines()
for acc in acc_list:
acc = acc.rstrip('\n')
done_accounts.append(acc)
# the todo list is the (disjunct) difference
todo_accounts = list(set(total_accounts) - set(done_accounts))
# write todo_accounts to todo.txt
with open(todo_file, 'w') as f:
for account in todo_accounts:
f.write(account + '\n')
# Let's do 50 iterations and see how we progress!
for iter in range(1,51):
todo = get_todo(todo_file)
newly_found_accounts = get_commenter_accounts(todo)
num_total = update_total_file(todo, newly_found_accounts, total_file)
update_done_file(todo, done_file)
update_todo_file(todo_file, total_file, done_file)
print('{} accounts stored!'.format(num_total))
else:
print('Done!')
32 accounts stored!
44 accounts stored!
55 accounts stored!
85 accounts stored!
102 accounts stored!
129 accounts stored!
170 accounts stored!
214 accounts stored!
230 accounts stored!
265 accounts stored!
288 accounts stored!
314 accounts stored!
340 accounts stored!
377 accounts stored!
403 accounts stored!
448 accounts stored!
471 accounts stored!
493 accounts stored!
526 accounts stored!
564 accounts stored!
575 accounts stored!
600 accounts stored!
624 accounts stored!
661 accounts stored!
704 accounts stored!
732 accounts stored!
756 accounts stored!
772 accounts stored!
799 accounts stored!
841 accounts stored!
844 accounts stored!
877 accounts stored!
905 accounts stored!
936 accounts stored!
962 accounts stored!
977 accounts stored!
1001 accounts stored!
1009 accounts stored!
1057 accounts stored!
1084 accounts stored!
1101 accounts stored!
1136 accounts stored!
1168 accounts stored!
1185 accounts stored!
1197 accounts stored!
1222 accounts stored!
1240 accounts stored!
1271 accounts stored!
1289 accounts stored!
1306 accounts stored!
Done!
file_path = os.getcwd() + '/' + done_file
done_accounts = []
with open(file_path, 'r') as f:
acc_list = f.readlines()
for acc in acc_list:
acc = acc.rstrip('\n')
done_accounts.append(acc)
print(len(done_accounts))
50
Cool huh! :-)
What did we learn, hopefully?
In this episode, I showed you how to "strategically think for algorithmical problem solving", using only the techniques we have discussed thus far in the Learn Python Series. We've built a real-life, useful, web crawler that auto-discovers Steem accounts, does it pretty efficiently (without re-visiting the same accounts) as well, and we did not need to use a database or the Steem API.
Thank you for your time!
Posted on Utopian.io - Rewarding Open Source Contributors
There's a third option that you could've gone for with saving the intermediate state – you could have used the
picklemodule and simply saved out a representation of the data structure which would hold the list of names to do, done, and all of them. That is pretty efficient, even though it doesn't really mimic the way that you're using the files as a persistent buffer here.And this method has a strange advantage: as long as you can get the system to make use of file locking appropriately, you can actually treat those file locks as process locks and distribute the actual processing of the creation lists over multiple machines. Effectively a poor man's cluster, which is great fun and I encourage everyone to try building at least once in their lives.
Probably not what you intended, but certainly amusing.
I know ;-)
But because the
Learn Python Seriesis intended as a book, I'm limiting myself to only using what was covered in the previous episodes! Andpicklehasn't been explained yet! ;-)While writing this, I initially used just one .txt file holding
account_name,statuslines (like:scipio,todo). But that led of course to a nested list, and I hadn't explained theany()function yet, so I changed my code to using 3 files functioning as persistent buffers ;-)Since we are thinking algorithms eh, I think one way we could make this more dynamic, and to solve the "related users" problem going with the "recent-replies" method, is to do option 3, then 4. That way, we get totally unrelated and widespread users.
First, we try to fetch the new posts, then for each of these users, we carry out method 4 to obtain users in their recent replies. This might actually be able to crawl the full blockchain, assuming that each user on the blockchain is linked to/has commented on at least one other user on the blockchain.
Quick one though (probably unrelated ): I was really interested in the posts fetching algorithm you mentioned...
So our API returns the first 20 or 50 posts as the case may be. Then, onClick of the "next" button, it fetches the next 20 or 50. What parameter do you specify that tells the API to fetch second set of 20 or 50? Because I dont think I find any such specification in the Steem API. Is there a workaround I'm not seeing?
Wow, this is really good. Keep going. I am waiting your next article. By the way, thanks for your welcome to discord, i will contact you as soon as possible...
Thx! And I will continue ;-)
Well, charming as always!
Thank you for the contribution. It has been approved.
You can contact us on Discord.
[utopian-moderator]
Wonderful
Realy i appreciate this post...so nice...
nice and well detailed post sir...following you and your writing style so that i can also write quality iOS tutorials.
Lovely tutorial.. Guess i need to start from the first
Informatics. Thanks