Natural Language Text Analysis for January 2018

Abstract
This is the third and final part of a Natural Language Text Analysis. It is a follow-on to prior work that analyzed text and emoji. This analysis differs in that we are focusing on natural language word cluster analysis seeking markers of successful or high quality posts.
Scope
We will be considering data for the month of January 2018 and will include foreign languages and character sets. We exclude the following multimedia catagories:
| Music & Video | Photography | Memes |
|---|---|---|
| dtube, youtube, music | photography, colorchallenge, architecturalphotography, vehiclephotography, photofeed, photo | dmania, decentmemes, meme |
The dataset includes 1,203,022 posts from 58,846 categories (excluding those above) and 110,474 distinct authors.
Tools
The analysis will be performed in R using only Open Source Public Domain tools (particularly Quanteda) and on a 10 year old MacBook(!).
Top 10 most popular categories by Post count
| Rank | Category | Total Posts | Avg Votes | Authors |
|---|---|---|---|---|
| 1 | life | 59,087 | 11.327619 | 16,804 |
| 2 | bitcoin | 37,777 | 11.784737 | 10,059 |
| 3 | news | 30,257 | 5.156856 | 3,973 |
| 4 | kr | 29,771 | 13.549830 | 3,282 |
| 5 | spanish | 29,626 | 29.367886 | 5,621 |
| 6 | cryptocurrency | 28,918 | 11.535791 | 8,443 |
| 7 | art | 28,389 | 12.981331 | 6,979 |
| 8 | steemit | 28,140 | 16.085821 | 10,653 |
| 9 | food | 26,751 | 11.792718 | 7,894 |
| 10 | introduceyourself | 21,460 | 13.443290 | 16,079 |
Vote Statistical Summary
Standard Deviation
46.51859
Quantiles
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
-93 1 1 2 3 4 6 8 12 23 4023
Summary
Min. 1st Qu. Median Mean 3rd Qu. Max.
-93.00 2.00 4.00 12.87 10.00 4023.00
Subsetting Best & Worst Posts
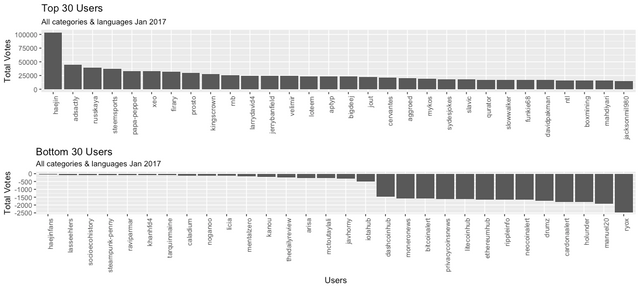
Here we subset posts by votes (specifically, net_votes per post) and illustrate the author of those posts. We will subset at the bottom 10th percentile (< 1 vote) and the top 90th percentile (> 23 votes).
Illustrated here is the top and bottom 30-user cohort from each subset.
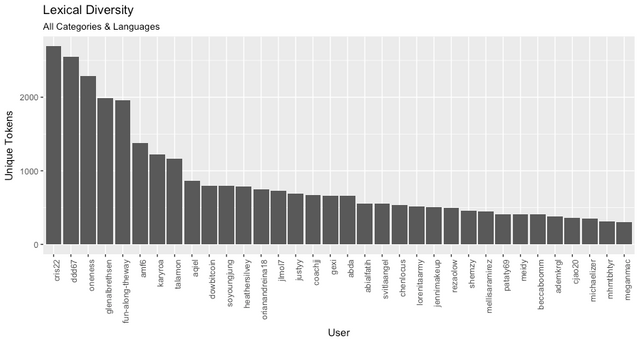
Lexical Diversity
There is some evidence to suggest that vocabulary is correlated with intelligence. In this study we equate size of vocabulary with Lexical Diversity to test the hypothesis that smart users produce high performing, high quality content.
In Natural Language Processing, sentences are tokenized into individual words. Strictly speaking, a lexical token is a character vector and may not be an actual word. e.g. "Ah-ha!" would be a valid token. A Chinese character would also be a valid token.
In this analysis we use Token count as a proxy for Lexical Diversity. We also use the terms "word" and "token" interchangeably.
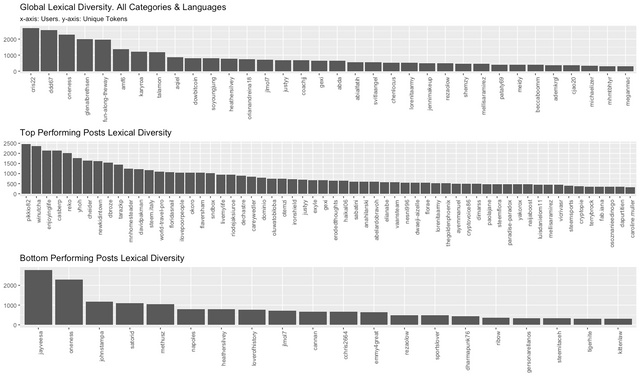
This chart illustrates Global Lexical Diversity for all Posts. These are users with lexical diversity greater than 300.
This is an arbitrary cut-off. We know the average 4 year old (native english speaker) knows approximately 5,000 distinct words. I am intentionally setting the cut off well below average to include non-native english speakers.
We can now compare these authors with high lexical diversity (big vocabularies and presumably smart) to high and low performing post authors (our subsets).
Highest Voted Authors
Our top performing user (@haejin) by vote count doesn't appear in our list of users with high lexical diversity (the smart people with big vocabularies). This doesn't suggest he's not smart just that he uses a narrow vocabulary. This user publishes specialized, technical content on Eliot Wave Analysis.
The following 14 authors from the Top Performing Post subset also appear in the High Lexical Diversity group. These users have large vocabularies and high votes.
| Rank | Author | Tokens | Total Votes |
|---|---|---|---|
| 1 | @glenalbrethsen | 1991 | 23 |
| 2 | @amf6 | 1381 | 91 |
| 3 | @karyroa | 1224 | 40 |
| 4 | @aqiel | 864 | 37 |
| 5 | @orianandreina18 | 748 | 28 |
| 6 | @justyy | 689 | 5602 |
| 7 | @gexi | 664 | 83 |
| 8 | @abialfatih | 551 | 30 |
| 9 | @svitlaangel | 551 | 23 |
| 10 | @lorenitaarmy | 517 | 3513 |
| 11 | @mellisaramirez | 451 | 39 |
| 12 | @pataty69 | 410 | 52 |
| 13 | @meidy | 407 | 48 |
| 14 | @michaelizer | 347 | 164 |
Lowest Voted Authors
We also have six users with low performing posts and high lexical diversity. These users have low performing posts but also large vocabularies. It would suggest, being smart and having a big vocabulary is not an indicator of how well your content will perform.
| Rank | Author | Tokens | Total Votes |
|---|---|---|---|
| 1 | @ddd67 | 2551 | 0 |
| 2 | @oneness | 2284 | 0 |
| 3 | @karyroa | 1224 | 0 |
| 4 | @shemzy | 453 | 0 |
| 5 | @meidy | 407 | 0 |
| 6 | @mhmtbhtyr | 315 | 0 |
Visual Comparison
Lining the plots up we observe the Top Performing cohort (middle chart) contains consideraly more authors with Lexical Diversity greater than 300. We're seeing more users in the Top Performing cohort using large vocabularies. While we can not draw conclusions, it would suggest there are more smart people in the top performing cohort.
Word Frequency
To analyze word frequency we must coerce our post data into a Corpus and then to a Document Frequency Matrix (DFM). Creating the Corpus and DFMs takes approximately 45 mins processing time.
Word Frequency
During this process, I removed the following stop-words. Stop-Words are discussed in earlier posts. This step is considered data preprocessing or cleansing.
Stop Word List
"steem","steemit","steemian","steemians","resteem","upvote","upvotes","post","SBD","SP","jpeg","jpg","png","www","com","td","re","nbsp","p","li","br","strong","quote","s3","amazonaws'com","steemit'com","steemitimages'com","img","height","width","src","center","em","html","de","href","hr","blockquote","h1","h2","h3","960","720","div","en","que","la","will","y","el","https","http","do","does","did","has","have","had","is","am","are","was","were","be","being","been","may","must","might","should","could","would","shall","will","can","un","get","alt","_blank","i","me","my","myself","we","our","ours","ourselves","you","your","yours","yourself","yourselves","he","him","his","himself","she","her","hers","herself","it","its","itself", "they","them","their","theirs","themselves","what", "which","who","whom","this","that","these","those","am","is","are","was","were", "be","been","being","have","has","had", "having","do","does","did","doing","would", "should","could","ought","i'm","you're","he's", "she's","it's","we're","they're","i've","you've", "we've","they've","i'd","you'd","he'd","she'd", "we'd","they'd","i'll","you'll","he'll","she'll", "we'll","they'll","isn't","aren't","wasn't","weren't", "hasn't","haven't","hadn't","doesn't","don't","didn't", "won't","wouldn't","shan't","shouldn't","can't","cannot", "couldn't","mustn't","let's","that's","who's","what's", "here's","there's","when's","where's","why's","how's", "a","an","the","and","but","if", "or","because","as","until","while","of", "at","by","for","with","about","against", "between","into","through","during","before","after", "above","below","to","from","up","down", "in","out","on","off","over","under", "again","further","then","once","here","there", "when","where","why","how","all","any", "both","each","few","more","most","other", "some","such","no","nor","not","only", "own","same","so","than","too","very"
Sparse Word Removal
As part of data preparation for illustration we also remove sparse terms. Ths is known as trimming the DFM of sparse terms. This leaves us with words (terms, tokens) used more than 10 times and appear in more than 25% of posts.
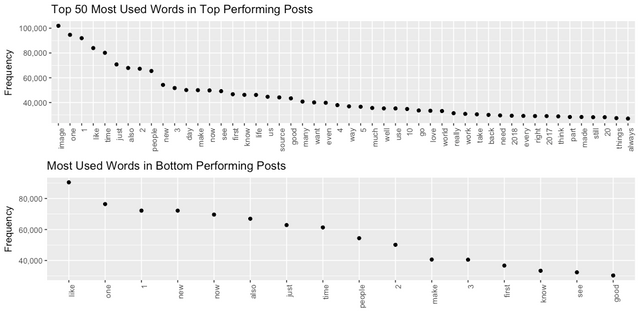
Top Performer Cohort
When we examine the most frequently used words in the Top Performing Cohort, we again observe high lexical diversity. This word cloud illustrates words used more than 5,000 times across all Top Voted posts.

These are the Top 10 tokens in this wordcloud. I have chosen not to remove numbers at this point.
| image | one | 1 | like | time | just | also | 2 | people | new |
|---|---|---|---|---|---|---|---|---|---|
| 101916 | 94650 | 91955 | 83957 | 80139 | 70767 | 67883 | 67275 | 65488 | 54249 |
Bottom Performer Cohort
By comparison, the bottom performing posts use far fewer words 5,000 or more times. The lexical diversity is much lower.

The Top 10 most frequently used words in this cohort appears to be a subset of those used in the Top Performer Cohort (above). In other words, a similar core vocabulary is used but fewer times and in the context of a much narrower vocabulary.
| like | one | 1 | new | now | also | just | time | people | 2 |
|---|---|---|---|---|---|---|---|---|---|
| 90445 | 76413 | 72181 | 72170 | 69627 | 66945 | 62857 | 61338 | 54410 | 50133 |
Topic Models
Latent Dirichlet allocation (LDA) is a generative statistical model used to identify groups of similar words across documents. I'm using it here in an attempt to identify Topics or Themes.
This is as much art as science as it requires manual tweaking of the algorithms parameters. The algorithm is computationally intensive and takes a long time to run on my crappy MacBook, so I have not invested a lot of time seeking the optimum set of parameters.
Top Performer, Top 5 Topics
Topic 1 Topic 2 Topic 3 Topic 4 Topic 5
[1,] "people" "one" "source" "image" "1"
[2,] "time" "also" "new" "watch" "2"
[3,] "life" "like" "follow" "2017" "3"
[4,] "just" "first" "2018" "part" "4"
[5,] "know" "even" "use" "made" "5"
[6,] "day" "way" "also" "2018" "10"
[7,] "see" "well" "come" "used" "20"
[8,] "like" "much" "world" "today" "7"
[9,] "go" "just" "year" "day" "6"
[10,] "now" "time" "time" "long" "2018"
Bottom Performer, Top 5 Topics
Topic 1 Topic 2 Topic 3 Topic 4 Topic 5
[1,] "time" "one" "also" "1" "like"
[2,] "people" "first" "new" "2" "now"
[3,] "make" "see" "one" "3" "just"
[4,] "good" "people" "make" "new" "new"
[5,] "know" "just" "first" "first" "make"
[6,] "just" "know" "time" "make" "first"
[7,] "like" "make" "people" "time" "one"
[8,] "see" "like" "like" "one" "know"
[9,] "one" "good" "3" "like" "time"
[10,] "first" "time" "2" "good" "3"
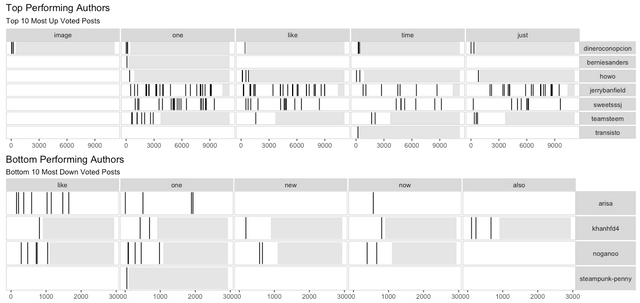
Lexical Dispersion Plots
Using the most frequently used terms from above we can examine how they're used in the top performing posts by Author. This plot illustrates how authors are using particular high frequency words.
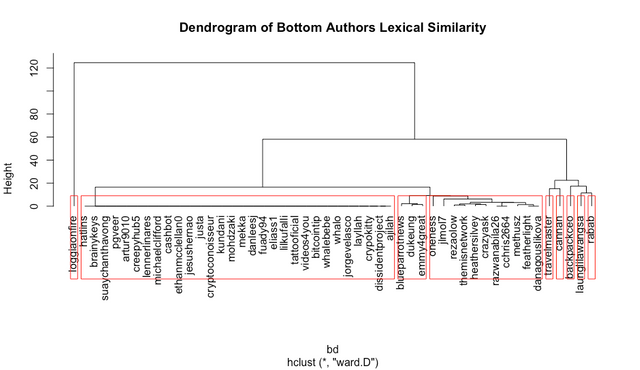
Heirarchical Clusters & Dendrograms
Finally, we perform a heirarchical cluster analysis using an agglomeration method called "ward.D". We are examining similar clusters across posts from authors in each subset. I have attempted to bin the clusters into 9 arbitrary groups.
We are suggesting the users in each red box are using statistically similar vocabulary.

Conclusions
This analysis only scratches the surface and is severely limited by my time and crappy laptop. However, it seems to suggest that authors with high lexical diversity (the potentially smarter ones) seem to gain more Up Votes.
Readers should note some acknowledged confounding factors such as,
- Some posts are duplicated and translated into two or more languages. This doubles or trebles their token count.
- I was unable to account for the effects of Resteeming posts of others.
- Some content is straight language translations of other work (e.g. Utopian.io translations)
- There are several kanji characters that equate to an english one. This distorts the token count in favor of asian language speakers.
Posted on Utopian.io - Rewarding Open Source Contributors
Thank you for the contribution. It has been approved.
You can contact us on Discord.
[utopian-moderator]
Hey @crokkon, I just gave you a tip for your hard work on moderation. Upvote this comment to support the utopian moderators and increase your future rewards!
Congratulations! This post has been upvoted from the communal account, @minnowsupport, by morningtundra from the Minnow Support Project. It's a witness project run by aggroed, ausbitbank, teamsteem, theprophet0, someguy123, neoxian, followbtcnews, and netuoso. The goal is to help Steemit grow by supporting Minnows. Please find us at the Peace, Abundance, and Liberty Network (PALnet) Discord Channel. It's a completely public and open space to all members of the Steemit community who voluntarily choose to be there.
If you would like to delegate to the Minnow Support Project you can do so by clicking on the following links: 50SP, 100SP, 250SP, 500SP, 1000SP, 5000SP.
Be sure to leave at least 50SP undelegated on your account.
It's a comprehensive long analysis. Thanks for the information @morningtundra
@morningtundra, Contribution to open source project, I like you and upvote.
Hey @morningtundra I am @utopian-io. I have just upvoted you!
Achievements
Community-Driven Witness!
I am the first and only Steem Community-Driven Witness. Participate on Discord. Lets GROW TOGETHER!
Up-vote this comment to grow my power and help Open Source contributions like this one. Want to chat? Join me on Discord https://discord.gg/Pc8HG9x
Very interesting
I have never seen a statistical analysis of this kind and it seems to me an impeccable job on your part
That’s very kind if you. Thank you.
Hola soy nueva en esta gran comunidad, espero tener su apoyo, como dice el un dicho: El que se arriesga no pierde nada y el que NO se arriesga no gana... Éxito
You are doing interesting work here @morningtundra,
how is your leg/foot healing up?
On the mend. Thanks for asking 🙂