Writing Kafka Streams application
Writing Kafka Streaming application
What Will I Learn?
Write here briefly the details of what the user is going to learn in a bullet list.
- Kafka Streams concepts and design ideas
- Fundamental difference between KStreams and KTables
- Organising, packaging and running Kafka Streams app
Requirements
- Basic Java Experience
- Experience working with Apache Kafka
- Optionally: experience with data processing
Difficulty
- Advanced
Tutorial Contents
In this tutorial we will explain general ideas of behind Kafka Streams design and gain some practical Kafka Streams programming experieance by creating a simple project. Our application will count number of word appearances in a kafka topic.
Your question and suggestions are welcomed in comment section, as always. Examples are tested on MacOS, but should work without changes in Linux as well. Windows users are advised to use virtual machine to emulate linux environment.
About Kafka Streams
Apache Kafka is a great tool for fast, reliable and efficient message transfer over the network. Thanks to this characteristics it has become a popular data integration tool for data processing frameworks like Spark, Flink, Storm, Samza and others.
Starting from version 0.10.0, Kafka provides stream processing capabilities as well. Kafka Streaming quickly became gained wide populariy, since it is well integrated with Kafka messaging (for obvious reasons) and is very simple to set up, especially when you already have Kafka cluster in your production environment.
Streaming concepts
Traditional Kafka queues can be viewed as a real-time streams of events. What that implies that incoming messages are ordered in time and immutable. Each message has primarily key which, which uniquely identifies the record.
Tables in relational database contain data which is unordered and mutable. You can sort data in any way you like with corresponding query, but data itself does not have notion of order, like steamed data has. You can also change any row in database, or remove it entirely.
Conceptually, database represent the state of your data at any moment in time. State can change, so the database has this mutability characteristics. Data stream, on the other hand, represents the events that cause the state changes. Events can "override" themselves, but ultimately, once event is fired it exists and so cannot be "undone".
Both of those ideas revolve around different ways of representing finite state, and both of them have their strengths and weaknesses. Data stream can be replayed and any moment to build not just the final state, but also any intermittent state of your data. Databases are more powerful in terms of gathering insights from the data, performing aggregations and ordering the data.
Kafka Streams handles those two ways of representing data by providing two distinct abstractions:
- KStream - is a representation of continuous, timed and immutable event stream
- KTable - is a view of the ever-changing structured state of the data
These 2 abstractions are the basis for understanding Kafka Streams.
Word Count application
“Word Count” program is to Data Processing world what “Hello World” is to classical programming. We will keep up with this tradition and write a simple program to perform wordcount in a topic.
We will use Java 8 programming language for this tutorial, because it's the most common language to write Kafka Streams programs (although there exists third party wrappers for Kafka Streams API in other popular data processing languages like Python and Scala). If you don't have Java 8 Runtime Environment installed in your system, please follow instructions in Java Download Page.
We will also use Maven as our project/dependency management tool of choice. Follow instructions in Maven Documentation to install it on your system.
Kafka Streams, obviously, relies on Kafka cluster as it's messaging transport. If you don't know how to quickly set up small local Kafka distribution, refer to my tutorial on the topic.
When all components installed, let's create folder structure for our Java project. Maven can save us from doing it manually:
$ mvn archetype:generate \
-DgroupId=io.utopian.laxam \
-DartifactId=streams-tutorial \
-DarchetypeArtifactId=maven-archetype-quickstart
Accept default options when asked by Maven, and confirm choses settings in the end. First run of this command might take some time because Maven need to download it's dependencies.
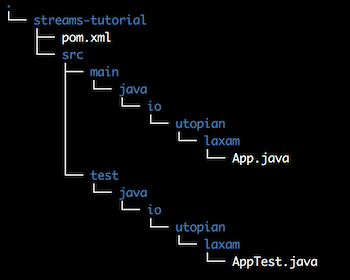
Project structure
Now we need to add Kafka Streams library to the list of dependencies of our project. To do that, open pom.xml on the root level of our newly-created project, and add following lines in the <dependencies> section:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>1.0.0</version>
</dependency>
We also need to tech Maven to package all the dependencies into one jar file (commonly called uberjar). To do this we need to configure maven-compiler-plugin and maven-shade-plugin. I will not go into details of configuring Maven, because it's a very broad topic, definitely out of the scope for this tutorial. To reach our goal of teaching maven to build uberjar, copy following code into <project> section.
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
<configuration>
<finalName>uber-${artifactId}-${version}</finalName>
</configuration>
</plugin>
</plugins>
</build>
Now the project setup is finished and we are ready to start writing actual application. Open the file src/main/java/io/utopian/laxam/App.java, which was generated for us by Mave. Inside you will find generic "Hello World" application, which will serve us as a starting point. We don't need to actually print "Hello World" to the stdout, so just remove that line.
We will start writing our application from specifiying following Kafka Streams configuration parameters:
BOOTSTRAP_SERVERS_CONFIG: Kafka bootsrap addressAPPLICATION_ID_CONFIG: unique application ID, used to create Kafka consumer groups groupsKEY_SERDE_CLASS_CONFIGandVALUE_SERDE_CLASS_CONFIG: serializers for keys and values correspondingly.
Here's how it looks in code:
package io.utopian.laxam;
import java.util.Properties;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.common.serialization.Serdes;
public class App {
public static void main( String[] args ) {
Properties props = new Properties();
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "WordCount");
props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
}
}
Next step is to configure our input stream. This is done through builder pattern. For this tutorial we will use topic named text as an input:
// ... couple of new imports
import org.apache.kafka.streams.kstream.KStreamBuilder;
import org.apache.kafka.streams.kstream.KStream;
// ... in the main method
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> input = builder.stream("text");
Now we need to define transformations and output of our program. What we want to see in the output topic is a "snapshot" of word counts at any given moment:
Input: Output:
one one 1
two two 1
one one 2
If you think about it, the output stream is just a stream of updates of the state of "table" representing count of word in an input. Each input line results in update on some row in a table, and key of that row, along with incremented value, gets published in the output topic. For this reason we will need to transform our input KStream into KTable:
// ... more imports
import org.apache.kafka.streams.kstream.KTable;
// ... main function
KTable<String, Long> wordCounts = input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, value) -> value)
.count()
The 3-step transformation is performed as follows:
flatMapValues: Transform incoming stream of text events into stream of words, by splitting input with regular expression;groupBy: Group stream on values;count: Aggregate count of grouped values into KTable.
What's left is to convert our KTable into output stream, and direct that stream into Kafka topic, and tell Kafka Streams to start application.
import org.apache.kafka.streams.kstream.Produced;
import org.apache.kafka.streams.KafkaStreams;
...
wordCounts.toStream().to("wordcount", Produced.with(Serdes.String(), Serdes.Long()));
KafkaStreams streams = new KafkaStreams(builder.build(), config);
streams.start();
At this point our program is finished. To get the uberjar run
$ mvn package
Unlike with most other data processing engines, Kafka Streams application is a normal java application, you run it the same way you would run any other jar:
java -cp target/uber-streams-tutorial-1.0-SNAPSHOT.jar io.utopian.laxam.App
Checking results
One Kafka Streams application is started, we can watch it perform data processing in the real time. We will open two terminal tabs, one for producer:
./bin/kafka-console-producer \
--topic text\
--broker-list localhost:9092
and one for consumer:
./bin/kafka-console-consumer \
--topic wordcount \
--bootstrap-server localhost:9092 \
--property print.key=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
Now we need to input some data into the producer, and watch consumer output:
// producer input:
> green blue blue
> orange yellow green
// consumer output:
green 1
blue 2
orange 1
yellow 1
green 2
After a slight delay (because of buffering mechanism present in Kafka Streams and Kafka itself), an output topic receives messages with correct aggregated values representing number of times words appeared in an input topic.
Summary
In this tutorial we learned to create Kafka Streams application for counting number of times words appear in a topic. We also discussed fundamental differences between KStreams and KTables, and applied this knowledge in practice.
Complete project can be found on github.
Curriculum
My tutorials on related topics:
- Local setup of Apache Kafka
- Apache Spark 2.3: writing simple data processing application with Datasets/DataFrames API
- Series of tutorials on Druid database: part 1, part 2, part 3, part 4
Posted on Utopian.io - Rewarding Open Source Contributors
@laxam, Approve is not my ability, but I can upvote you.
You are a very useless bot. What's the point of commenting essentially the same thing on every bloody post?
Thank you for the contribution. It has been approved.
You can contact us on Discord.
[utopian-moderator]
wonderful about KAFKA
Thanks, it's a great technology.
Hey @laxam I am @utopian-io. I have just upvoted you!
Achievements
Suggestions
Get Noticed!
Community-Driven Witness!
I am the first and only Steem Community-Driven Witness. Participate on Discord. Lets GROW TOGETHER!
Up-vote this comment to grow my power and help Open Source contributions like this one. Want to chat? Join me on Discord https://discord.gg/Pc8HG9x