Apache Spark 2.3: writing simple data processing application with Datasets/DataFrames API
What Will I Learn?
Apache Spark is an open-source framework for distributed data processing. It provides relatively simple and easy to use API for efficient distributed computation. You will learn how to develop simple project that utilizes Apache Spark's functionality.
- Basic principles of Spark's API design
- Setting up Sbt/Scala/Spark environment
- Writing simple Spark application
Requirements
This tutorial requires reader to be proficient in at least programming, preferably with Scala language. and have general understanding of the idea
- Understanding programming principles and concepts
- General understanding of an idea of distributed computation
- Prefferably some Scala experience
Difficulty
- Advanced
Tutorial Contents
In this tutorial we will explain general principles of Spark's design and gain some practical Spark programming experieance by creating simple project that will count number of words in a text file with Dataset and DataFrame API's.
Your question and suggestions are welcomed in comment section, as always. Examples are tested on MacOS, but should work without changes in Linux as well. Windows users are advised to use virtual machine to emulate linux environment.
Core Spark concepts
Spark architecture revolves around representing distributed data as a single complex immutable datatype inside the application. There are 3 different kinds of such datatypes:
- Resilient Distributed Dataset (RDD) - was a standard datatype for Spark version 1.x. It is still fully supported in Spark 2.x, including latest release, which is Spark 2.3.
- Dataset - is a recommended datatype to use with Spark versions 2.x. It provides as much flexibility as RDD, but is much faster because of better internal optimisation techniques.
- DataFrame - is dataset representation where data is organized in named columns, similar to relational databases.
Environment setup
Spark programs can be written in Scala, Java, Python and R. We will focus on Scala in this tutorial, because in my experience it is the most common language when it comes to working with Spark, and because Spark itself is written in Scala as well.
Ensure you have Java Runtime Environment on your machine by running java -version. If needed, navigate to Java Download web-page and follow instruction to install latest version of Java.
To install Scala follow to the Scala web-site and choose Download SBT option. SBT is short for Scala Build Tool, It handles everything related to project configuration and dependancy management for us, including running correction version of the Scala. We will show how to use SBT for Scala/Spark project shortly.
Next we will need to download Apache Spark. Head to the Apache Spark download web-page and choose Spark release 2.3.0, package type "Pre-built for Apache Hadoop 2.7 and later". Save the resulting archive and unarchive it to the suitable location in your system.
App Stracture
Spark applications look a bit different than normal Scala applications. Normally, point of entry for Scala application is an object that inherits from App, but with spark Application is usually just an object without App parent, which has main method. main accepts array of strings - command line parameters passed on application start.
So an empty spark application template looks like this:
object Tutorial {
def main(args: Array[String]) {
//... main application code goes here
}
}
Spark Session
In this tutorial we will focus on Spark Dataset API, as it is newer and more convenient way of writing Spark applications than RDD API.
With dataset API, application context is managed in SparkSession. SparkSession represents set of configuration parameters for connection between Spark application and Spark computing cluster.
SparkSession is created with Spark Session builder:
import org.apache.spark.sql.SparkSession // import SparkSession
object Tutorial {
def main(args: Array[String]) {
val spark = SparkSession
.builder()
.appName("LaxamSparkTutorial")
.master("local[4]")
.getOrCreate()
import spark.implicits._
//... main application code goes here
}
}
This Spark Session has application name set to LaxamSparkTutorial, and master url is configured to be local[4], which is spark's way of configuring execution to be performed on local machine using 4 cores.
import spark.implicits._ uses created SparkSession to import multiple syntactic helpers. Normally you will do this for each spark session, even in most trivial cases.
Setting up sbt project
"Word Count" program is to Data Processing world what "Hello World" is to classical programming. We will keep up with this tradition and write a simple program to count words in a file. As an input we will use my latest Steemit post Bitcoin: how it supposed to be, and what it turned out to be, but you can use any text you like.
Before extending our previous example with code for performing wordcount we need to organise our code into proper Scala project structure. Create a directory for our project and navigate into it.
$ mkdir laxam_spark_tutorial && cd laxam_spark_tutorial
Copy the text file you want to analyze in here. In my case it's called laxam_bitcoin_post.md.
Now create file with name build.sbt and open it for editing with your favorite text editor. This is a configuration file for sbt. For our project we just need to set four values:
name- human readable project nameversion- current version of the projectscalaVersion- version of Scala language to uselibraryDependencies- external libraries to load
Here is how built.sbt will look for our project:
name := "Laxam Spark Tutorial"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.3.0"
Note that for sbt configuration it is important to keep a blank line after each parameter!
Now you need to create subfolder main/scala where we will put the code for our app:
$ mkdir -p main/scala
Now create and open file main/scala/Tutorial.scala: this will be the location for our main program.
WordCount with spark
First thing we add to our Spark application is, of course, reading the data from a file:
val inFile = "<path_to_project_directory>/laxam_bitcoin_post.md"
val txt = spark.read.textFile(inFile).cache()
This line will read the whole file, create Dataset of strings out of it and, thanks to cache method, persist it in memory and on disk.
Now it's time to perform series of transformation on our data. Dataset API provides multitude of methods to choose from, among them are classical map, flatMap and filter which we are going to use.
val txt = spark.read.textFile(inFile).cache()
val df = txt
.flatMap(_.split(" ")) // split lines into words
.filter(_ != "") // remove empty lines (they don't count as words)
.map(_.toLowerCase()) // convert all words to lowercase
.toDF() // convert to DataFrame
/* Conversion to dataframe is needed because
it is much more convinient to use DataFrame api
for operations that has to do with grouping and
aggregation.
Let's continue... */
.groupBy($"value") // group data on values
.agg(count("*") as "count") // aggregate count
.orderBy($"count" desc) // sort in descending order
Thats whole opperation. It performs calculation through series of interconnected opperations on immutable sets, and this allows spark to make decisions on how to split the work between execution nodes. What's left is just to ask Spark to display the results for us, and stop the application. Complete Tutorial.java will look like this:
/* SimpleApp.scala */
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
object Tutorial {
def main(args: Array[String]) {
val inFile = "./laxam_bitcoin_post.md"
val spark = SparkSession.builder.appName("WordCount").getOrCreate()
import spark.implicits._
val txt = spark.read.textFile(inFile).cache()
val df = txt
.flatMap(_.split(" "))
.filter(_ != "")
.map(_.toLowerCase())
.toDF()
.groupBy($"value")
.agg(count("*") as "num")
.orderBy($"num" desc)
df.show()
spark.stop()
}
}
To build this application we need to run single command:
$ sbt package
< ... job logs omitted ... >
[info] Done packaging.
[success] Total time: 6 s, completed Mar 4, 2018 9:38:48 PM
Resulting jar-file is generated in target/scala-2.11/laxam-spark-tutorial_2.11-1.0.jar (note that name is created from the project name on in your build.sbt, so it might be different for you). Now we can use this jar to execute our program in Spark. Navigate to spark folder and execute spark-submit binary like this:
./bin/spark-submit --class "Tutorial" ../laxam_spark_tutorial/target/scala-2.11/laxam-spark-tutorial_2.11-1.0.jar
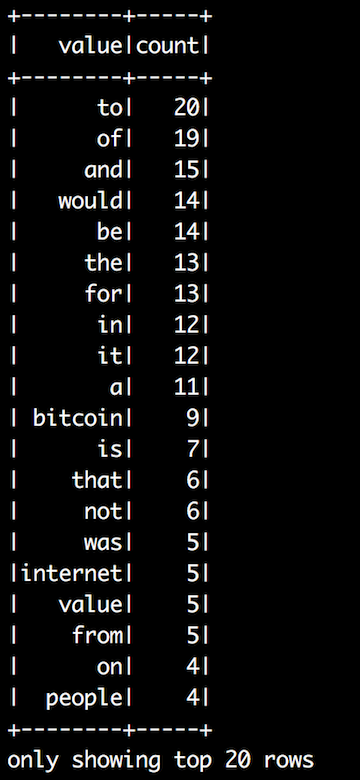
Spark will execute our program and print out the top 20 rows in DataFrame (I'm forced to insert this illustration as a picture because Utopian editor breaks formatting):
Summary
Spark is a very flexible framework for distributed computations. In this tutorial we have learned how to setup Spark environment, create simple Spark project in Scala with sbt and how to write a WordCount program using Dataset and DataFrame API.
I hope this tutorial was as fun to read as it was to write it.
Posted on Utopian.io - Rewarding Open Source Contributors
Hey @laxam I am @utopian-io. I have just upvoted you!
Achievements
Suggestions
Get Noticed!
Community-Driven Witness!
I am the first and only Steem Community-Driven Witness. Participate on Discord. Lets GROW TOGETHER!
Up-vote this comment to grow my power and help Open Source contributions like this one. Want to chat? Join me on Discord https://discord.gg/Pc8HG9x
Thank you for the contribution. It has been approved.
You can contact us on Discord.
[utopian-moderator]