Machine learning and Steem #3: Account classification - accuracy improvement up to 95%
Repository
https://github.com/keras-team/keras
What Will I Learn?
- Collect data from beem and SteemSQL
- Build neural network model for multiclass classification problem
- Build decision tree for multiclass classification problem
- Visualize decision tree
Requirements
- python
- basic concepts of data analysis / machine learning
Tools:
- python 3
- pandas
- matplotlib
- seaborn
- jupyter notebook
- scikit-learn
- keras + tensorflow (as backend to keras wrapper)
It looks like a lot of libraries, but it's a standard python toolset for data analysis / machine learning.
Difficulty
- Intermediate
Tutorial Contents
- Problem description
- Collecting data
- Building neural network
- Building decision tree
- Visualization of the decision tree
Problem description
The purpose of this tutorial is to improve the accuracy of the model used to classify Steem accounts (content creator vs scammer vs comment scammer vs bid-bot). In the previous part of this tutorial, we achieved an accuracy of 83%. And this is what the confusion matrix looks like:
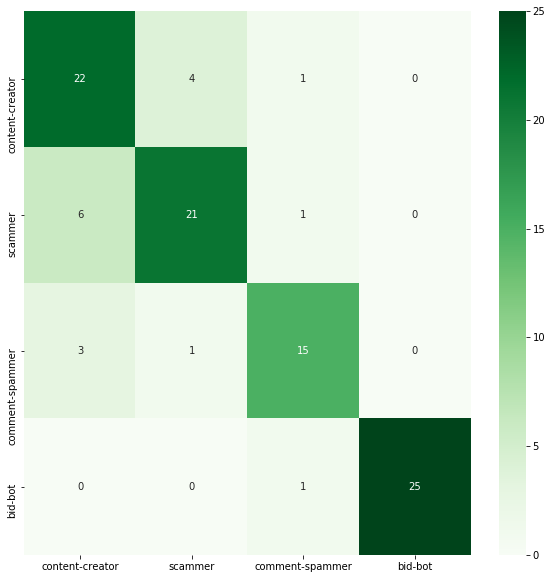
We will try to get improvement through:
- enlarging the training set
- increasing the number of iterations
- using a decision tree instead of a neural network
Collecting data
The data will be downloaded in a similar way to the previous part of the tutorial, but we want to collect as much as possible. Last time, each class had 100 elements, but this is not enough.
Scammers will be collected from the comments of the users guard and arcange, who warns about this type of accounts. For example:
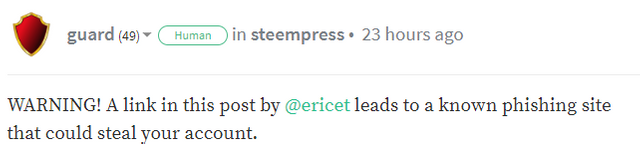
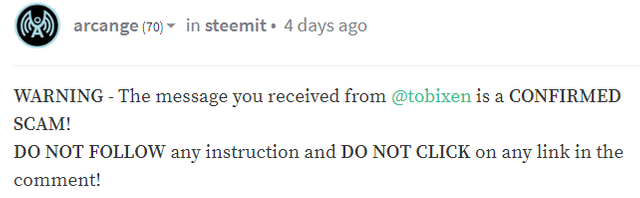
We will use the following queries:
SELECT DISTINCT SUBSTRING(body, CHARINDEX('@', body) + 1, CHARINDEX(' leads', body) - CHARINDEX('@', body) - 1) as account
FROM Comments (NOLOCK)
WHERE depth > 0 AND
author = 'guard' AND CONTAINS(body, 'phishing')
SELECT DISTINCT SUBSTRING(body, CHARINDEX('@', body) + 1, CHARINDEX(' is a', body) - CHARINDEX('@', body) - 1) as account
FROM Comments (NOLOCK)
WHERE depth > 0 AND
author = 'arcange' AND
CONTAINS(body, 'CONFIRMED AND SCAM') AND
body LIKE '%The message you received from%'"""
In this way, we've obtained 750 unique accounts. Therefore, we will try to get the same number of elements for other classes.
Content creators will be collected from the SteemSQL database with the following script:
SELECT TOP 750 author
FROM Comments (NOLOCK)
WHERE depth = 0 AND
category in ('utopian-io', 'dtube', 'dlive', 'steemhunt', 'polish')
ORDER BY NEWID()
To get a list of spammers, first find the more frequent short comments.
SELECT body, COUNT(*) as cnt
FROM Comments (NOLOCK)
WHERE depth = 1 AND LEN(body) < 15 AND created BETWEEN GETUTCDATE() - 60 AND GETUTCDATE()
GROUP BY body
ORDER BY cnt DESC
This gives us the following list:
spam_phrases = [
'nice', 'nice post', 'good', 'beautiful', 'good post',
'thanks', 'upvoted', 'very nice', 'great', 'nice blog',
'thank you', 'wow', 'amazing', 'nice one', 'awesome',
'great post', 'lol', 'like', 'cool', 'hi',
'nice, upvoted', 'good job', 'nice article', 'nice pic', 'nice photo',
'welcome', 'hello', 'good article', 'nice picture', 'nice info',
'promote me', 'fantastic', 'super', 'nice work', 'nice video',
'good project', 'wonderful', 'nice bro', 'lovely', 'nice shot'
]
Now we can collect the list of spammers with the following query:
query = """\
SELECT TOP 750 author
FROM Comments (NOLOCK)
WHERE depth = 1 AND
created BETWEEN GETUTCDATE() - 60 AND GETUTCDATE() AND
body in """ + to_sql_list(spam_phrases) + """
GROUP BY author
ORDER BY COUNT(*) DESC"""
The list of bid-bots has been collected manually from https://steembottracker.com/. But here's the problem, we only have 100 records. There are two options:
- leave 100 records and thus have unbalanced classes
- use some method to add records
We will use the simplest method - we copy data to get 750 records. This is not an ideal situation, but rather a better than unbalanced class.
The full script that retrieves the features of accounts can be found here.
As a reminder, the features analyzed are:
['followers', 'followings', 'follow ratio', 'muters',
'reputation', 'effective sp', 'own sp', 'sp ratio', 'curation_rewards',
'posting_rewards', 'witnesses_voted_for', 'posts', 'average_post_len', 'comments',
'average_comment_len', 'comments_with_link_ratio', 'posts_to_comments_ratio']
I will not focus on visualization here, because it was shown in previous parts and I do not want to repeat myself. The sample chart looks as follows and all of them can be seen here.
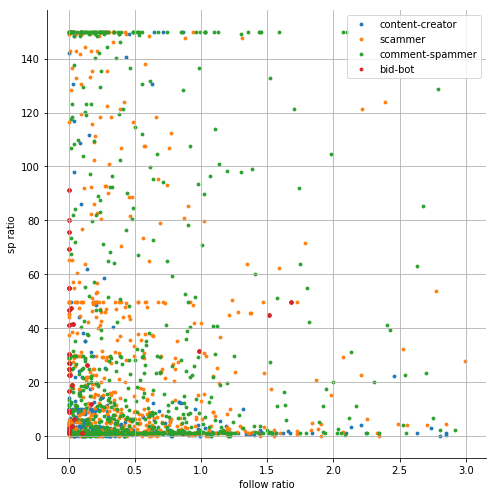
Building neural network
Let's start with the simplest neural network possible.
model = Sequential()
model.add(Dense(17, input_dim=17, activation='relu'))
model.add(Dense(4, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='nadam',
metrics=['accuracy'])
model.fit(X_train, y_train, epochs=50, batch_size=1, verbose=0)
score = model.evaluate(X_test, y_test,verbose=0)
y_pred = model.predict_classes(X_test)
print('accuracy: %.3f' % score[1])
cm = confusion_matrix(np.argmax(y_test, axis=1), y_pred)
plot_confusion_matrix(cm)
accuracy: 0.847
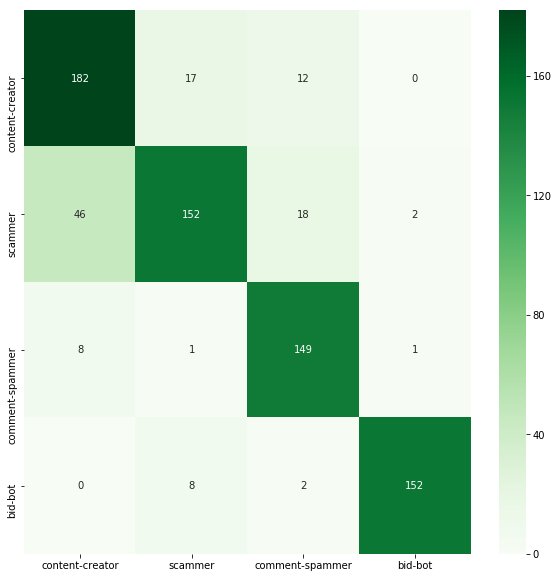
A short glossary:
| Name | Description |
|---|---|
| model.add | adds new layer |
| Dense | fully connected layer |
| relu | ReLU activation function |
| sigmoid | sigmoid activation function |
| categorical_crossentropy | loss used for multiclass classification problem |
| nadam | Adaptive Moment Estimation optimizer, basically RMSProp with Nesterov momentum |
| accuracy | percentage of correctly classified inputs |
Let's add more layers and neurons and increase number of iterations.
model = Sequential()
model.add(Dense(85, input_dim=17, activation='relu'))
model.add(Dense(40, activation='relu'))
model.add(Dense(20, activation='relu'))
model.add(Dense(4, activation='softmax'))
accuracy: 0.851
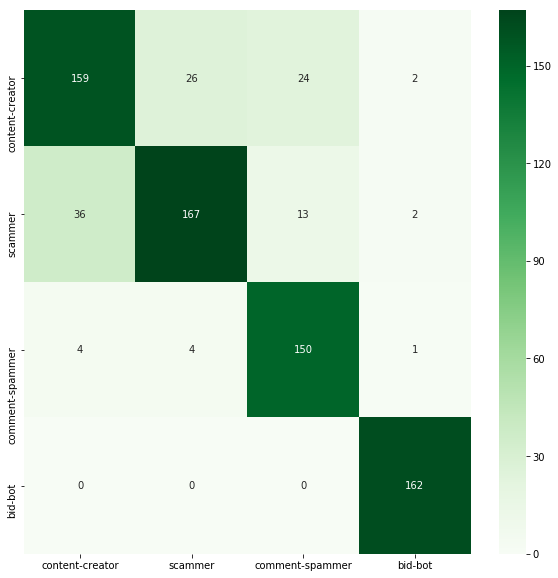
We see some improvement over the model from the previous part of the tutorial, but it is not yet too significant.
Building decision tree
Let's try to use a different model - a decision tree. It is a decision support tool that uses a tree-like graph of decisions and their consequences.
X_cols = columns
y_cols = ['class']
X = df[X_cols]
y = df[y_cols]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
input_dim = len(X_cols)
model = tree.DecisionTreeClassifier(max_depth=8)
model.fit(X_train, y_train)
score = model.fit(X_test, y_test)
y_pred = model.predict(X_test)
print('accuracy: %.3f' % accuracy_score(y_pred, y_test))
cm = confusion_matrix(y_test, y_pred)
accuracy: 0.951
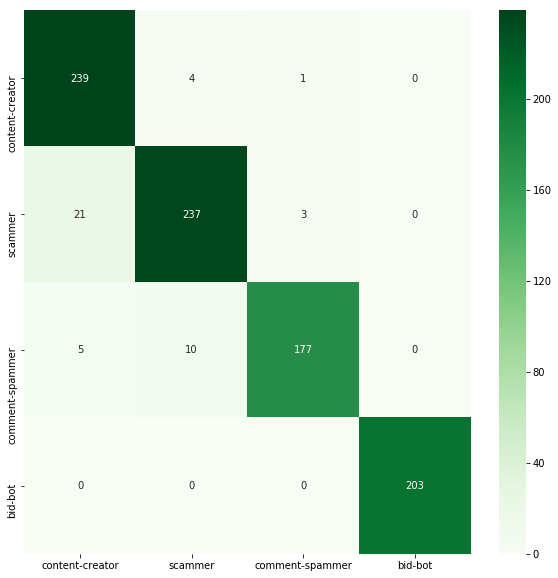
The accuracy of the model has increased significantly up to 95%!
Visualization of the decision tree
We will use a graphviz library for visualization.
import graphviz
from sklearn.tree import export_graphviz
dot_data = tree.export_graphviz(
model,
out_file=None,
feature_names=X_cols,
class_names=class_names,
filled=True,
rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph = graphviz.Source(dot_data)
graph.format = 'png'
graph.render('dtree_render', view=True)
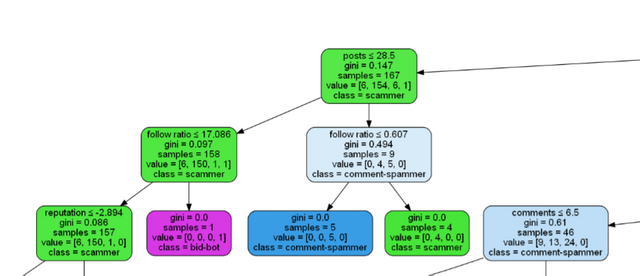
As we can see, the decision tree is very large (to see the details just open the image in the new tab).

Let's look at a fragment of this tree. The color of nodes is related to the class. The value gini (Gini impurity) measures how often a randomly chosen element from the set would be incorrectly labeled if it was randomly labeled according to the distribution of labels in the subset.
Curriculum
- Machine learning (Keras) and Steem #1: User vs bid-bot binary classification
- Machine learning and Steem #2: Multiclass classification (content creator vs scammer vs comment spammer vs bid-bot)
Conclusions
- the bigger the dataset, the better we can train our model
- it's worth trying different algorithms instead of sticking to one
- the decision tree turned out to be a better choice, both in terms of efficiency and execution time
Thank you for your contribution.
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Write a ticket on https://support.utopian.io/.
Chat with us on Discord.
[utopian-moderator]
Hey @jacekw.dev
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!
Congratulations @jacekw.dev! You have completed the following achievement on Steemit and have been rewarded with new badge(s) :
Click on the badge to view your Board of Honor.
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
this is really awesome. Well done. I am thinking I would love to work with you on something. You have fantastic skills and your posts are a breath of fresh air.
Hope you don't mind me asking, but did you sign up to steemit via utopian?
Thanks. I came to steemit about a year ago, but I only wrote in the #polish community using the @jacekw account. Recently I have some ideas for using Machine Learning (eg account classification), so I decided to start creating contributions for #utopian-io.
With pleasure!
wow just looking at some of your posts on your other account too. I had never come across this account before, this is such a pity. but I am glad I have discovered you now. Steem on