Documentation of Peer Query v2(Proof of Concept)

After publishing the source code of the Proof of Concept version of Peer Query, I did add a little documentation in the README.md on to make it work.
I did explain a few things on how it works, however a comment from the moderators of Utopian reminded me that perhaps I should explain further how the site actually works.
In this report I will try to do so in the most concise way possible. To begin with, we need to understand a few things about the Proof of Concept version of Peer Query:
- It runs on Node.js.
- It is rendered client side.
- It is not built on any UI framework.
- It is not built on Build tools
- Both front end and back end are purely Javascript
- Frontend is ES5 and ES6 Javascript and around 1% JQuery
- Backend is Node.js and Express
Again, In this report I am only trying to explain the concepts on which the codes in www.peerquery.com works - for this reason some of the codes I use as examples are not the actual codes - though there are very similar to the actual codes.
Once you understand them, the concept, you will be able to read/tweak the code of Peer Query with ease.
To be able to follow and understand the scripts here, you will need to:
- understand HTML
- Understand CSS
- Understand Javascript
- Have the source code - get it on Github
What works
- Writing a post/query
- Voting with sliderbar on post
- Voting with slidebar on comments
- Viewing a post with comments, votes counts, response count, time, ...
- Browsing posts by tag: proposal, question, quiz, contest and gigs(whatever you set)
- Browsing posts by trending, new, hot, most voted, most responses
- Viewing any Steem account: www.peerquery.com/@any_account
- Viewing any Steem post using the permlink: www.peerquery.com/@author/permlink
Some features are missing
- No threaded comments
- No ability to respond to comments - only to the main post
- No parsing of content via MarkDown parser
- No auto linking of username mentions, links, images, youtube link
Plain but not sweet code
- Code is NOT minified - sweet
- Most elements are named in a semantic way - sweet
- Code is not dressed or well documented
- Code is dirty: version 2 was trimmed down from version 1 which was a platform and far sophisticated. For this reason you may find snippets of unrelated code remaining from the version 1.
No external page scripts
All scripts related to running a page are located within it, under HTML content - before the closing </body> tag.
This means you can save each page in the browser and run it offline - except that you need connection to be able to fetch data from Steem API.
Also, the JQuery meant to load the navbar and footer will cause error if you run it in the browser instead of a server on local host - since it cannot fetch the navbar and footer due to Cross site policy.
Libraries used include:
- JQuery - mainly for Bootstrap as it is used less than 1% of the actual code
- TimeAgo.js - none JQuery version
- Fonts Awesome for icons
- Steem JS
The secret sauce
Lazy loading
Only the raw code is served by the server. The page will then use Javascript/ Steem API to fetch the data and then create the associated divs, cards and containers for it.
Images are fetched from Busy Images using the format:
var pImg = document.createElement("img");
pImg.className = "rounded-circle in-line";
pImg.onerror = function() {this.src='/images/avatar.png'};
pImg.style.height = "30px";
pImg.src = "https://img.busy.org/@" + response.author;
pImg.alt = response.author;
Page theme
On the page, there are actually only 13 pages in total:
- index.html(homepage)
- query.html(theme for post page)
- me.html(redirect for users who login on the on a page we cannot set as call_back page in Steem Connect v2 app. Such pages include search page and dynamic post page)
- user.html(theme for user page)
- contests.html(contest)
- questions.html(questions)
- proposals.html(proposals)
- quizzes.html(quizzes)
- gigs.html(gigs)
- about.html(about)
- 404.html
- privacy-policy.html
- faqs.html
As you can see, the pages: user.html/me.html are themes for all user pages. This means when a user visits www.peerquery.com/@username - they will see the page at user.html.
The page will then use Javascript to fetch use username from the page's URL and then do a simple
steem.api.getAccounts([username], function(err, response){
console.log(err, response);
//use the response to populate the user fields in the Bootstrap tables
//after that then make the tables visible
});
The trick is that I have an intangible table(CSS "display:none") with labels, so once the values are set to their respective tables, then it will become tangible(CSS "display:block").
Component theming
The navbar, sidebar and the footer are saved as navbar.html, sidebar.html and footer.html respectively and loaded into the page via JQuery.
To do this we simply create an empty div at the positions where we want them to be put into:
<div id="navbar"></div>
<div id="sidebar"></div>
<div id="footer"></div>
Then, to call the navbar.html, sidebar.html and footer.html into it, we do the following Javascript at the bottom of the page, before the closing </body> tag.
//first of all load the navbar, sidebar and footer
$("#navbar").load("/navbar.html");
$("#sidebar").load("/sidebar.html");
$("#footer").load("/footer.html");
Lazy loading for navbar and footer?
It may not be recommended for a production site - I don't know. However since the files are on the same server/domain there will be no issue loading them.
The site contains external scripts and CSS that it cannot run without, so loading part of your page externally is just the same.
Now, main catch is that since it is loaded by JQuery, it might not run if Javascript runs into an error or is disabled or looses connection.
Why lazy loading?
The entire site will run on the very same navbar, sidebar and footer. However if you include them directly, it means in the case of update to the navbar, sidebar or footer, you will have to edit the navbar, sidebar or footer on all pages.
By loading the same navbar, sidebar and footer into all pages instead, it means you only edit them once and it will be reflected on all pages!
This way too, you can include scripts and function that you want to run on all sites in just one of them and it will run everywhere. In the case of peer Query:
- navbar contains the Steem Connect v2 system and it is used on all pages
- sidebar contains the "post a query" function to post on all pages
- footer contains credits and Google analytics - not the best place for analytics though
Storing of voting states
In React, Vue and other frameworks, the states of UI component are stored centrally in a virtual system managed by the UI library.
Since Peer Query is not written in any UI library, the vote states of each button on a comment is stored the element itself using dataset attributes:
data-voted="true/false"
Also, all other important details needed to process a vote are stored in the element itself including:
data-permlink="testing-a-tes....."
They are generated dynamically for the comments and post during the rendering function. Two other values: user and author are declared dynamically once a page is loaded. The author is extracted from the post permalink - the full URL in the browser page. The user is declared once the user logs in - hence you cannot vote without login.
The components of a vote system are: the vote area toggle button, the slider and the vote button. By default, the slider bar is hidden and will only show if you click on the vote area toggle button.
Consider the following naming conventions:
- weight slider element ID is the post/comment ID on Steem: example "123";
- vote area toggle button with of Steem post/comment ID plus "-area": example: "123-area"
- vote button ID is the slider element ID plus the string: "-vote": example: "123-vote"
The Steem post/comment ID is the post ID you get for each post/comment on Steem API.
Once the user click any vote button(example vote button with ID:"123") we can simple get the slider value or weight of the slider representing that particular component by doing:
User click button containing: onClick="vote(this)"
function vote(element) {
var raw_id = element.id; //which give us "123"
var current_sliderbar id = raw_id + "-vote";
var vote_weight = document.getElementById(current_sliderbar).value;
// now we have the vote weight
api.vote(//this is SC2 - steem connect's vote function
user,
author,
element.dataset.permlink,
vote_weight,
function (err, res) {
//console.log(err, res)
if(err) alert(err) { /*statements*/; return}; //"return" terminate execution if err
//whatever follows here will happen only if there no err
element.dataset.voted = "true";
//whatever else like:
element.innerText = "Unvote";
element.className = "...";
document.getElementById(element.id + "-area").innerText = "Voted at: " + weight * 10 + "%";
//more statements follow here if you like
});
}
We only need to create this voting function once, and it will be used for ALL elements that have a onClick="vote(this)". This function will work like magic on all voting buttons, even if there are a million!
The only disadvantage is that if you do it for a million elements, you would be creating a million event listeners - while in libraries such as React and Vue.js, the virtual DOM uses only one single event listener to listener for all such events.
Alternatively, you can do so in JQuery and assign only a single event listener to all vote buttons by giving them a special className such as "voting". The you can implement the voting function on all elements that contain the voting class through:
$( ".voting" ).click(function() {
alert( this );
//the universal voting function continues here
});
Peer Query uses a single of such code for the voting of post and comments - the same single code shared for all voting buttons on Peer Query.
It gets even easier when you realize the you need to implement this feature only on the post page - the page where a post is viewed. Users do not vote on any other page - they only vote on the page where they read the post and comment.
If you want your reader to be able to vote posts right on the homepage or browser page then implement this feature there.
Function theming
There are 6 main content pages on Peer Query:
- Homepage(index.html - www.peerquery.com/)
- Questions(questions.html - www.peerquery.com/questions)
- Proposal(proposals.html - www.peerquery.com/proposals)
- Contests(contests.html - www.peerquery.com/contests)
- Quizzes(quizzes.html - www.peerquery.com/quizzes)
- Gigs(gigs.html - www.peerquery.com/gigs)
However with the exception of the homepage(index.html - www.peerquery.com/) - you will notice that all the other five pages have the following areas in common:
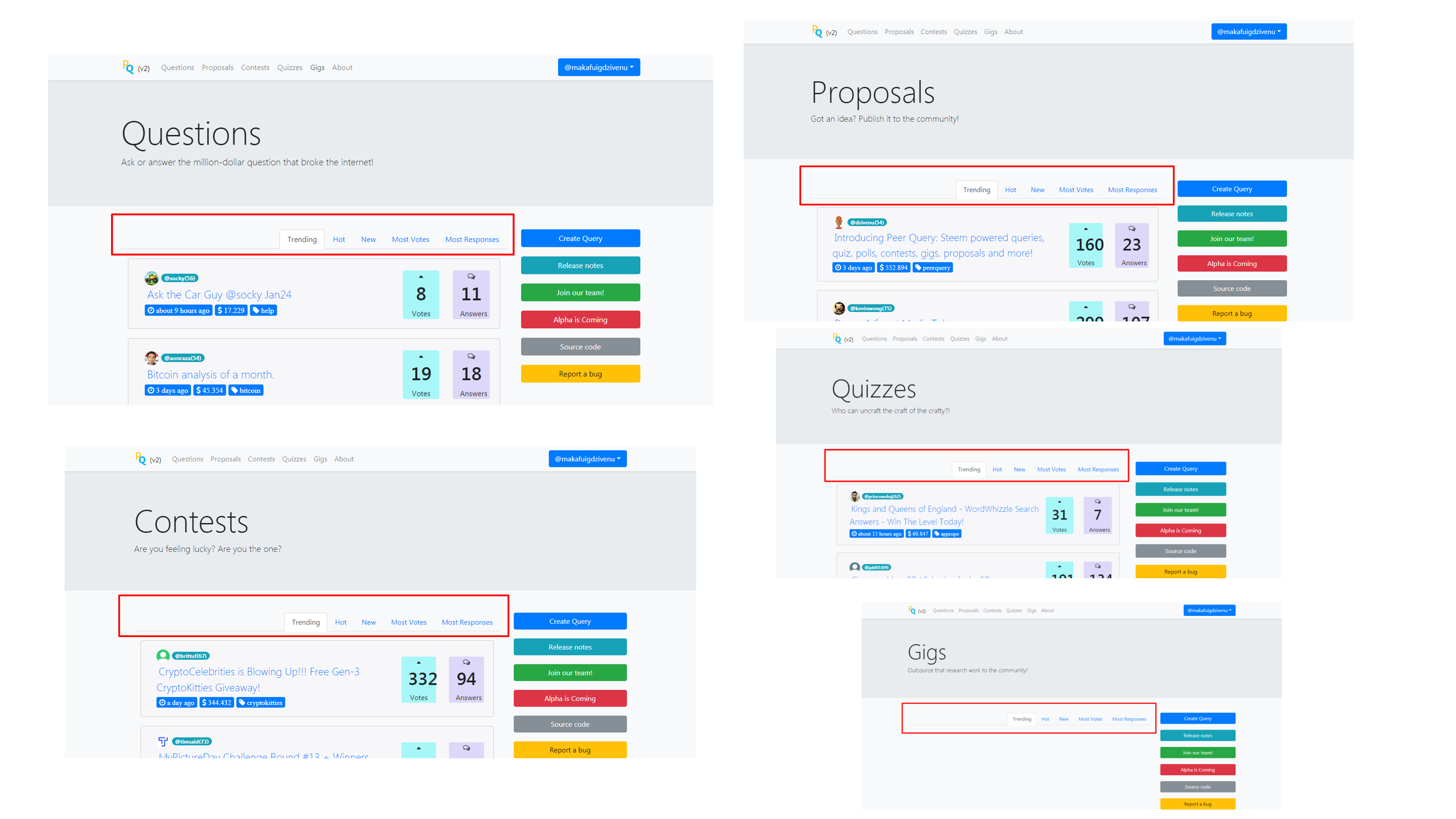
Good! This means that they will all run on the very same code! The only difference will be that they will call different tags!
So all the five content pages are the same in terms of code - except for the meta tags section!!! The only difference is that they will call different tags.
- Questions(questions.html - www.peerquery.com/questions) - will call the same code on the tag: "question"
- Proposal(proposals.html - www.peerquery.com/proposals) - will call the same code on the tag: "proposal"
- Contests(contests.html - www.peerquery.com/contests) - will call the same code on the tag: "contest"
- Quizzes(quizzes.html - www.peerquery.com/quizzes) - will call same code on the tag: "quiz"
- Gigs(gigs.html - www.peerquery.com/gigs) - will call the same code on the tag: "gig".
Each of the tabs Trending, Hot, New, Most Voted, Most Responses contain: onClick="display(this)"
The main code that powers them is
function display(element) {
document.getElementById(element.id + "TabContainer").innerHTML = "";
document.getElementById(element.id + "Tabspinner").style.display = "block";
document.getElementById("more-" + element.id).dataset.href = "";
loadMore(document.getElementById("more-" + element.id));
}
display(document.getElementById("trending")); //this is called on page load
function loadMore(element) {
document.getElementById(element.name + "Tabspinner").style.display = "block";
var limt = 11; var last_permlink = element.dataset.href;
var last_author = element.dataset.author;
if (element.dataset.href == "") {
query = { tag: element.dataset.tag, limit: limt };
} else {
query = { tag: element.dataset.tag, limit: limt, start_author : last_author, start_permlink : last_permlink };
}
if (element.name == "trending") getByTrending(query, element);
if (element.name == "hot") getByHot(query, element);
if (element.name == "new") getByCreated(query, element);
if (element.name == "byvotes") getByVotes(query, element);
if (element.name == "byresponses") getByChildren(query, element); }
And here is the getByHot() function:
function getByHot(query, element) {
steem.api.getDiscussionsByHot(query, function(err, result) { console.log(err, result);
document.getElementById(element.name + "Tabspinner").style.display = "none";
if (result.length <= 1) return;
document.getElementById("more-" + element.name).style.display = "block"; var n = result.length -1;
console.log(n);
element.dataset.href = result[n].permlink;
element.dataset.author = result[n].author;
for (x in result) {
if (x == result.length - 1) { timeAgo(); return }; //ignore the last result
show_post(result[x], element.name);
}
});
}
The function show_post() is quite too long to post here, so I will skip. For the other functions can view them on the www.peerquery.com in the browser console of the page or using the "view page source" right-click feature of browser. The full code is also on Github.
The main difference in the codes is the type of API called for each getByHot, getByTrending, ... function:
_ steem.api.getDiscussionsByHot(query, function(err, result) { ..._
_ steem.api.getDiscussionsByTrending(query, function(err, result) { ..._
_ steem.api.getDiscussionsByCreated(query, function(err, result) { ..._
_ steem.api.getDiscussionsByVotes(query, function(err, result) { ..._
_ steem.api.getDiscussionsByChildren(query, function(err, result) { ..._
The query remains the same and so are the statements that follows the ...
I believe the code is self explanatory in most areas. The alpha version will be even simpler than this version and will contain good documentation.
Notice that the tags are singular - not plural. You can call the plural forms if you want, but most people will tag their post as "proposal" than as "proposals".
Actually, your can change the tags to "life", "dev", "story", "news", "nsfw" or whatever - you will get content from the tag you set.
The server
The server is also pretty simply and straight forward, no module exports. Its all just a single file with simple code. Here are some of the functions in the server.js
app.get('/@:username', function (req, res) {
res.sendFile(path.join(__dirname + '/user.html'))
})
app.get('/@:username/:permLink', function (req, res) {
res.sendFile(path.join(__dirname + '/query.html'))
})
app.get('/:category/@:username/:permLink', function (req, res) {
res.sendFile(path.join(__dirname + '/query.html'))
})
app.get('/questions', function (req, res) {
res.sendFile(path.join(__dirname + '/questions.html'))
})
app.use(function (req, res) {
res.status(404).sendFile(path.join(__dirname + '/404.html'))
})
Visit Github to see the full server code.
What's cooking next
I am depreciating the Proof of Concept version of Peer Query. I am working on a neater one built on the awesome Semantic UI. It will a beauty and still be open source, I will be releasing it soon in days, as the alpha, stay tuned.
The current Peer Query proof of Concept version will be retired the moment the alpha is released. As at now, I am will continue my work only on the alpha, and no longer develop the proof of concept version.
The full code is on Github and you can do whatever you want with it. Hopefully this will be my last post on the Proof of Concept version, its time for the alpha!
Thank you all
Since I released the proof of concept version, I have received a huge amount of response and support form the community. I am very grateful for that and has been challenged to improved the site. That is why I am re-building the entire UI from scratch in Semantic UI.
While the current Proof of Concept site does work, the UI is not very presentable. Bootstrap is beautiful; Semantic UI is better. The alpha will be more professional and yet open source and will be released in days.
Thank you all for your support.
Project links
Proof of Concept of Peer Query
Source code on Github
Posted on Utopian.io - Rewarding Open Source Contributors
Oh boy, I don't understand a single thing (except the non-coded part) 😂
@dzivenu, I always try to support who contribute to open source project, upvote you.
Thank you for the contribution. It has been approved.
I would only like to recommend to use ``` markdown syntax for multi-line code blocks.
You can contact us on Discord.
[utopian-moderator]
Hey @dzivenu I am @utopian-io. I have just upvoted you!
Achievements
Community-Driven Witness!
I am the first and only Steem Community-Driven Witness. Participate on Discord. Lets GROW TOGETHER!
Up-vote this comment to grow my power and help Open Source contributions like this one. Want to chat? Join me on Discord https://discord.gg/Pc8HG9x