Diving deep in deep learning
This is an introductory post for my planned series in which I want to go through lectures from the Deep learning summer school 2016 and summarize the explained topics from each of those videos, there are a very good explanation for the today machine learning state-of-the-art algorithms.
In this post the basic algorithms that underlie neural networks are explained.
This is a part of my thesis which I finished this spring on the topic of recurrent neural networks (used for reading text in natural image scenes). I’m “reposting” it here on steemit because I found that it was a pity that no one actually gets to read it even though the neural network algorithms are very well explained in there.
As a thesis it had to be written very rigorously - with a lot of math and exact definitions, but I think that this is a very good starting point. The problem with neural networks is that there are very little things in the models that can actually be mathematically proven, and if you start of working on neural networks even without having the basics of neural networks grounded in mathematics, you can make mistakes very easily. But still in the next posts the topics that are described below will be touched again and explained in a little bit less mathematical way, so don’t panic if you find this explanation too complex.
Artificial Neural Networks
Artificial neural networks (ANNs) are a class of machine learning models which are inspired by biological neural systems and are used for classification, clustering, function approximation and other tasks.
The NN model can be seen as a interconnected system of neurons that exchange information. The connections in the system have numeric weights on them, that influence the strength of the information exchanged between two neurons. The weights are updated based on the experience from the provided training data.
The basic computational unit of neural networks is the neuron (see figure). The neuron receives weighted inputs and sums them into its inner activation. The output of the neuron is then calculated by passing its inner activation through a non-linear transfer function called activation function.
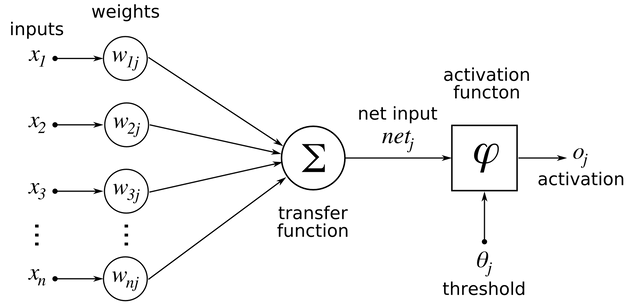
The basic computational unit of neural networks, the neuron.
Courtesy of https://en.wikibooks.org/wiki/artificial_neural_networks/activation_functions
The inner activation a of j-th neuron is calculated by
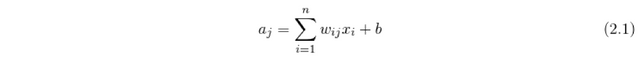
where w_ij is the weight between the i-th input and the j-th neuron, the x_i is the i-th input, and b is the bias. The inner activation is then used to calculate the output from the neuron by applying the activation function y_j = f(a_j).
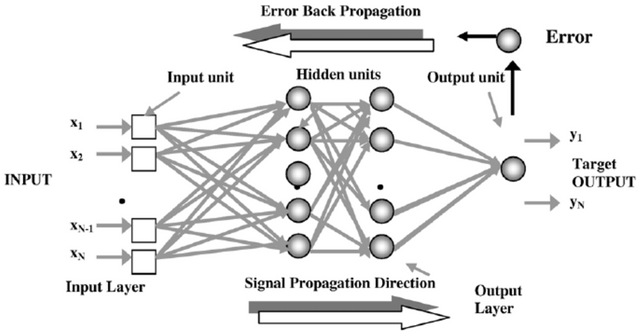
One simple model of neural network, that can well illustrate the principles of neural networks, can be seen in figure bellow (see figure: NNmodel). It consists of three layers of neurons, the input, hidden and output layer. Only neurons in neighboring layers are connected and they form a fully connected directed graph. The output of the network is then calculated in the forward pass by following the direction of the edges, from the input layer to the output layer. In the training phase the error of the generated prediction is passed through the layer in the opposite direction.
The basic NN model is the feedforward model where the connections between units cannot form a directed cycle~ (see figure: NNmodel).
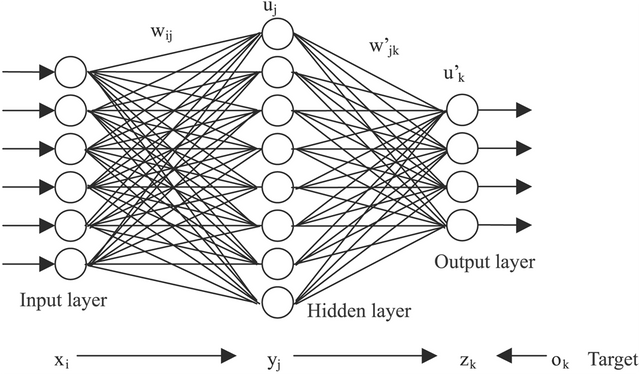
Example of a 3-layer neural network.
Courtesy of http://www.extremetech.com/extreme/215170-artificial-neural-networks-are-changing-the-world-what-are-they.
The main advantage of the neural networks lies in the universal approximation property which states that a neural network with at least one hidden layer and finite number of neurons can approximate any function. Other positive characteristic is that it can be trained incrementally from the provided data, which assures that it can find patterns in the data and discriminate them from outliers and noise. Finally the neural network model can be evaluated in parallel, which enables the acceleration of the computation on GPU (Graphics Processing Units).
There are several issues concerning training of neural networks and using them for predictions. One of the main cons is the complexity of the structure of the network created during the training process, which is hard to analyse. We are mostly left with the observation of the outcomes and statistical analysis of the provided results. Other problem is the need for long training time with low learning rate, without which there is a risk of divergence of the optimization process. Other issue comes from the fact, that the learning process is a gradient based method, which searches for local optima and thus the quality of the result depends on the initial conditions. There is a vivid research that is concerned with the overcoming of those poor local optima through regularization, good initialization etc.
The training of neural networks consists of three main phases: the network evaluation phase, the loss calculation and the backpropagation of the error towards the weights. During the evaluation the neural network's output is calculated. The received output is then compared with the required target and the error of the output is calculated by the loss function. The error is then backpropagated through the network to update weights, so as the error of the network would be minimized.
A trained model can then be used in the testing phase, during which the forward pass calculates the output - prediction - of the model.
Network evaluation
During evaluation the network calculates the output layer by layer. All neurons in the following layer receive the outputs from all neurons in the previous layer.
The output vector of the j-th neuron is calculated by
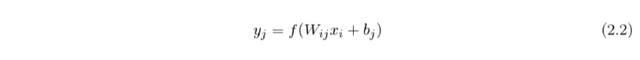
where f is the activation function, W_ij is the weight matrix between the i-th and the j-th layer, x_i is the output vector from the i-th layer, and b_j is the bias vector for the j-th layer. The output vector y_j then used as input vector for the next layer.
The output of the NN model is acquired by continuing this process through all layers and the model's prediction can be read from the last - output - layer.
Activation functions
Activation function is bringing non-linearity into the model, without which the network would be just a regular linear classifier. There are three frequently used activation functions: sigmoid, hyperbolic tangent (tanh) and rectified linear unit (ReLU). Sigmoid has the form
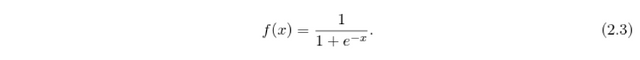
It's outputs range from 0 to 1, which is convenient for estimation of probabilities. If we need also the negative outputs, the tanh activation function can be used
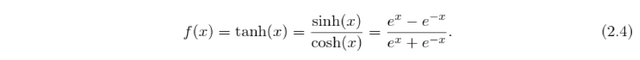
The problem with both tanh and sigmoid functions is in their shape, which influences directly the update of the weights. The gradient of the sigmoid and tanh function vanishes if we increase or decrease x far from zero. This does not happen with the rectified linear unit ReLU
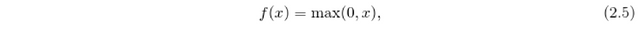
a non-saturating activation function, that was introduced by Krizhevsky in Imagenet classification.
Thanks to the shape of the function the value of the gradient does not decrease as the x increases, on the contrary it stays 1, and for negative x it is always 0. The use of the hard max function induces the sparsity of the network. The deep networks with ReLU activation functions can be trained efficiently even without pretraining.
Loss function
Loss function compares the prediction from the neural network with the desired output and returns the error of the prediction. The objective of the neural network training is the minimization of the loss on the training data. The basic loss function is the L_2 (Euclidean) norm
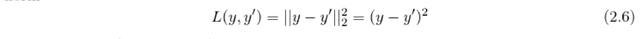
or the L_1 norm (absolute loss)
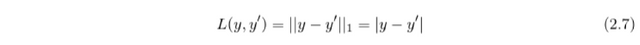
The error given by the loss function is then used for updating the weights in the network in the backward pass of the training.
Backpropagation
Backpropagation as learning algorithm for neural networks was first introduced by P. Werbos in 1982, and to this day it is the most notable algorithm used for training neural networks via minimization of the loss function. The general idea of backpropagation comes from its name - backpropagation of error. The final loss of the network is sent back to all weights in the network.
The loss/error of the network is optimized using the gradient method. The gradient is computed in the output layer and backpropagated through the network in order to calculate the change of the weights - delta W_ij. The delta W_ij should lead towards the minimization of the loss E, which is achieved by calculating its partial derivative with respect to the weights W_ij (W_ij is a weight matrix between layer i and j):
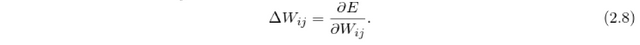
The weight deltas are then used to update the original weights:
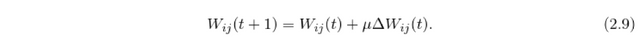
The weight deltas delta W_ij (updates) are calculated by means of the chain rule
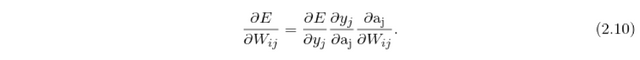
The y_j is the output vector from j-th layer and the a_j are the inner activation of the neurons in the layer. The E stands for the error of the prediction which in the case of L_2 norm is E=(t-y_o)^2, where t is the target and y_o is the output of the whole network.
To backpropagate the error the error vector delta_j of the neurons in j-th layer is needed. Those errors are again calculated layer by layer and describe how the error changes with the activation of the specific neuron in layer j
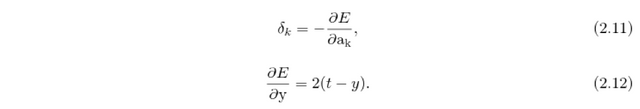
In the case of sigmoid activation function the derivative of the unit's output output w.r.t. the activation is
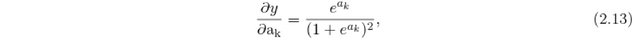
and the activation of the neuron is
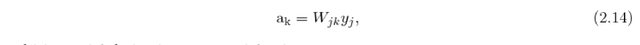
and it’s partial derivative w.r.t. weights is
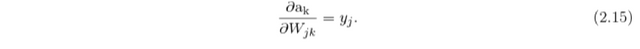
The gradients for hidden-to-output weights are then
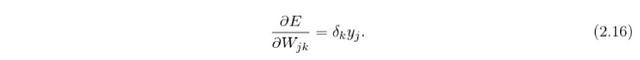
For the input-to-hidden weights the gradients are calculated equivalently to the hidden-to-output weight gradients. First the contribution E_j of the neurons in hidden layer j to the total error are calculated
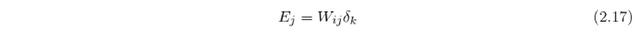
and then those contributions are used to obtain the error vector delta_j equally to [2.10],
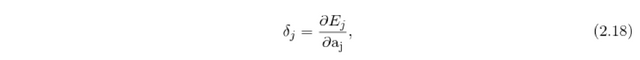
which is then used to calculate the error gradients w.r.t. the input-to-hidden weights by applying the same equation as [2.16] to the input weight matrix W_ij.
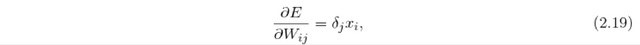
where x_i is the input vector.
Summary
So, the general idea is really that simple. In forward pass you calculate the outputs for each layer in a layer by layer manner - output from the preceding layer is the input for the next layer. And in backward pass (backpropagation) you just do the opposite to it. You first calculate the error on the output - by comparing it with the target/reality (also called the ground truth) and than you use this error to update the weights that are directly influencing the output. Than you use the backward pass to send the error to the before last layer and calculates the error on the outputs from this layer, and than again you use this error to update the weight that directly influence this layer. This is then repeated through the whole network until all weights are updated.
Very simple explanation of backpropagation is that each weight is updated relatively to how much it contributes to the final error.
And that's it! In theory it's that simple, but unfortunately tuning and setting all parameters for training neural networks isn't that simple, therefore it requires a lot of practice and some automatic feeling to be able to work with that.
Do I have to implement it myself?
No, if you don't want. There are plenty of platforms based on python (caffe, tensorflow, ...) or lua (torch) that have all the algorithms already implemented. But of course you have to understand the underlying principle to be able to potentially debug your model if it doesn't do what you want - and most probably on the first try it won't work properly.
If I am allowed to comment, maybe would it be valuable to finish your post with a "take-home message" section. The end sounds a bit abrupt, especially for readers not used to neutral nets.
If interested, do not hesitate to come and say hi on #steemSTEM!
Good remark, I meant it only as mathematical introduction to the topic, but you're right there should be some simplifying summary at the end.
Followed and resteemed!
Thanks! This is a great opportunity and also motivation for myself to go through the lectures and to really make some meaningful notes about them. That's why I made this "public promise" to write the posts about it.
Hi
A comment on very general theoretical level. I notice that the algorithms are written in the form of prevailing mainstream pure mathematics, containing trigonometric etc transcendental functions. The problem, and I think it is a deep one and even paradigmatic, is that computers don't do "actual infinities" of real numbers etc., but just finite notations for rational numbers such as 'floating points', p-adic 'quote notation' etc. This disparity between used mathematical language and its presuppositions, and what computers actually do, can easily lead to confusion e.g. when studying connections between neural networks and more general theories of cognition.
Rational and finitist theory of math, e.g. such as being developed by Norman J Wildberger, would be more consistent foundation for at least all computer oriented approaches, as well as more easy to communicate. Theoretical implications of such approach cannot be predicted, but they could be far reaching and radical. But in any case it seems very plausible that algorithms based on theory of math that is inherently purely computable - rational and finitist - could greatly enhance the machine computation efficiency and transparency.
My answer will probably not be as profound as your comment would deserve as I'm really not a mathematician. To the first part of your comment. You're right that the floating point numbers and non transcedent function are only approximated in the computer language, but I don't think it poses a problem for the nowadays programs/algorithms, because for instance in the case of neural networks there is much more unprecision inserted by the learning process itself (incorrect labels, noisy inputs). The whole process is local optima searching, and there are "only" statistical proves that it should lead to a good outcome (under many circumstances that in practice can't be assured). There is a problem with underflowing or overflowing numbers which in practice is solved by using the logarithm variants of the calculations.
And to the second part.. I don't know much (or actually anything) about Norman J. Wildberger - actually you introduced him to me, so I can't answer to the second part of your question. I'll try to follow him a bit more, from what I've just seen I like his view on mathematics where the next step in maths is chained on the last one.
I'm not mathematician either. Just seems that the disrepancy between mathematical theory and mathematical practice in AI self-learning systems could be interesting and promising avenue of research.
Also, on more practical level, I don't know if there's been attempts use of Quote Notation in addition to or instead of the floating point technique. Further links to QN here:
https://steemit.com/programming/@id-entity/quote-notation-blockchain-and-cryptocurrencies
Thank you for this post. It makes neural networks seem so simple, assuming you have some college-level math.
It seems there is important work here involving looking inside neural networks, understanding the shapes of their weights, and both simplifying these weights to functions and mapping the sets of weights to meaning that is inherent in the data being processed. It seems the concept of 'meaning' and 'how' are what is missing from neural networks, but it must be right there, in the distributions of weights.
I suppose a complex neural network is kind of like an activation function for some larger process.
I'm glad you liked it.. I agree that there is still quite a long way to better understanding (and subsequently also working) with the neural networks and the "functions from weights" that are created inside the models. I personally have still long way in front of me to be able to claim that I understand and know how to build and train a good model.