[EN/DE] Meltdown & Spectre - The inner workings (Part 3: Spectre)

[EN] Spectre
Introduction
In the last post, we learned that Meltdown only works on Intel CPUs. Spectre on the other hand works on nearly all modern CPUs, but the attack requires knowledge about the targeted application. This means you can't just attack all applications one the machine at once like with Meltdown.
But how does Spectre work? Before we talk about that, we'll need to introduce a few more terms.
Branch Prediction & Speculative Execution
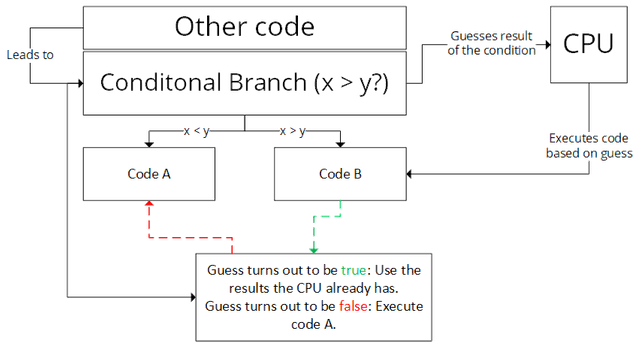
We already know about out-of-order execution, but what happens, when the program reaches a branch? It would be too costly to execute all variants. The answer is: The CPU guesses which path the program might take. There are two types of branches, which are used by Spectre.
First, we have the conditional branch. As an example, some code (A) is executed when a value is greater than another one, and some other code (B) when it's lower. Due to past executions and other factors the CPU might guess that the value is probably lower, so it will speculatively execute B out-of-order. That way, when the program actually reaches the branch, and the CPU was right (which it is most of the time), the code was already executed and time is saved. Otherwise the executed instructions are abandoned, and the other branch is executed.
The second variant attacks indirect branches. To keep it simple, indirect branches appear when you need to jump to another point in code, but first need to get the address where you want to jump from somewhere. This happens when you have a switch-Statement for example. Since the process of getting that address takes some time, the CPU will guess which address the program might jump to and execute the code located there, using the branch target buffer (which basically stores previous branch targets).
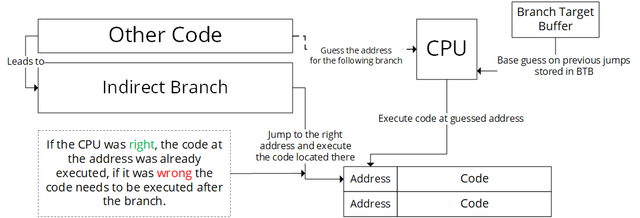
These types of code execution based on speculation are called speculative execution.
Variant 1: Conditonal Branch
Spectre comes in two variants, the first attacks conditional branches. Let's say we have a parameter x, that we can define while using the attacked application. At some point in the program, there is an if clause that checks if x is below an array size value. Now we'll run this part of the application several times, to mistrain the CPU. Each time, we'll choose a value that will result in a true statement (so the code in the if statement is executed).
if(x < array1_size) {
y = array2[array1[x] * 256];
Now we'll run our application again, but this time we'll choose a value that is outside of the array1 bounds, so the if clause would not execute the code. The processor thinks "Ha! I already know the outcome of this" before actually reaching the branch. It will execute the code in the if clause speculatively. All the results of this operation are reverted once the branch is reached and the CPU realizes that it was wrong, however things like the cache state stay.
That means we can use a side channel attack to create a covert channel to gain secret information. In our example, we can use Flush+Reload to see which part of array2 was accessed, which means we know the value of array1[x]. So we can read all values located in that array and all values in our applications memory if there are no bounds checks.
The paper also describes another attack, known as Evict+Load where a lot of data is loaded into the cache, which will remove array2 from the cache because of the limited cache size, instead of flushing it. That allows JavaScript programs to run the attack as well, since they can't use flush operations.
Variant 2: Indirect Branch
The second variant follows a similar concept. The attacker will mistrain the processor with a memory address in a shared library where it wants the program to jump to and execute the code located there.
When the application actually runs, the CPU will assume the jump target that was used before and execute the code at that location speculatively. Now we can create a covert channel like last time and use Flush+Reload or other side channel attacks to gain data.
Conclusion
As you can see, both of these variants require some knowledge about the targeted application, and are also harder to implement than Meltdown. However, they pose a higher risk since they are not that easy to fix and do not only affect Intel CPUs.
References
- Kocher, K., Genkin, D., Gruss, D., Haas, W., Hamburg, M., Lipp, M., Mangard, S., Prescher, T., Schwarz, M., Yarom, Y. Spectre Attacks: Exploiting Speculative Execution (2018)
[DE] Spectre
Einleitung
Im letzten Post haben wir herausgefunden, dass Spectre nur mit Intel CPUs funktioniert. Spectre funktioniert hingegen auf fast allen modernen CPUs, allerdings benötigt der Angriff Wissen über das Programm, welches man angreifen möchte. Das heißt, dass man nicht wie bei Meltdown alle Programme auf dem Computer angreifen kann.
Doch wie funktioniert Spectre? Bevor wir darüber sprechen, müssen wir noch ein paar neue Begriffe einführen.
Branch Prediction & Spekulative Ausführung
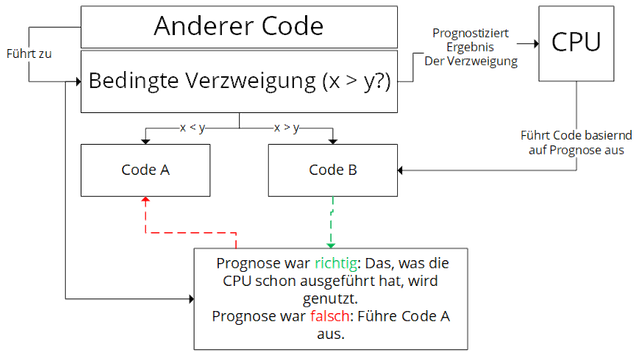
Wir wissen bereits, wie out-of-order execution funktioniert. Doch was passiert, wenn das Programm eine Verzweigung erreicht? Es wäre viel zu kostenintensiv alle Möglichkeiten auszuführen. Die Antwort: Die CPU prognostiziert, welchen Weg das Programm nehmen wird. Es gibt zwei Arten von Verzweigungen, die von Spectre genutzt werden.
Zum einen gibt es die bedingte Verzweigung. Als Beispiel: Code A wird ausgeführt, wenn ein Wert größer als ein anderer ist und Code B, wenn er niedriger ist. Durch Betrachtung vorheriger Ausführungen und anderen Faktoren, prognostiziert die CPU, (z. B.), dass der Wert niedriger sein wird. Das bedeutet, B wird spekulativ out-of-order ausgeführt. Dadurch hat die CPU, wenn die Verzweigung erreicht wird, den betreffenden Code je nachdem schon ausgeführt. Lag die CPU falsch, so wird der ausgeführte Code verworfen und der richtige ausgeführt.
Die zweite Variante sind indirekte Verzweigungen. Diese treten (einfach betrachtet) auf, wenn ich zu einem anderen Ort springen möchte, die Adresse dieses Ortes aber erst herausfinden muss. Da der Prozess des Herausfindens etwas dauert, wird die CPU prognostizieren, wohin das Programm vermutlich springen wird und den Code an dieser Adresse bereits ausführen. Dabei wird der sogenannte branch target buffer genutzt (dieser speichert im Prinzip die vorherigen Ziele dieses Sprungs).
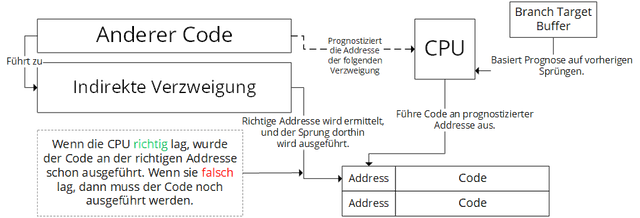
Diese Art von Ausführung basierend auf Spekulation wird spekulative Ausführung genannt.
Variant 1: Conditonal Branch
Spectre kommt in zwei Varianten, die erste greift bedingte Verzweigungen an. Nehmen wir an, dass wir einen Parameter x haben, den wir kontrollieren können, während wir das anzugreifende Programm nutzen. An irgendeinem Punkt in diesem Programm befindet sich eine if-Verzweigung, welche prüft, ob x kleiner als die Länge eines bestimmten Arrays ist. Wir führen diesen Teil der Anwendung nun mehrere Male aus, um die CPU falsch zu trainieren. Jedes Mal wählen wir einen Wert, welcher dazu führt, dass die Anweisung innerhalb des if-Statements ausgeführt wird.
if(x < array1_size) {
y = array2[array1[x] * 256];
Jetzt werden wir die Anwendung ein weiteres Mal ausführen, dieses Mal werden wir allerdings einen Wert wählen, welcher außerhalb der Grenzen von array1 liegt. Der Prozessor denkt "Haha! Das Ergebnis kenne ich bereits", bevor die Verzweigung überhaupt erreicht ist. Der Code innerhalb des Statements wird spekulativ ausgeführt. Alle Ergebnisse dieser Ausführung werden zurückgesetzt, sobald diese Verzweigung tatsächlich erreicht wird, allerdings bleiben Dinge wie die Anordnung des Caches erhalten.
Das bedeutet, dass wir eine side channel Attacke ausführen können, um einen covert channel zu erschaffen, welcher uns dabei hilft, an Daten zu kommen. In unserem Beispiel können wir Flush+Reload dazu einsetzen zu sehen, auf welchen Teil von array2 zugegriffen wurde. Das bedeutet auch, dass wir nun den Wert von array1[x] kennen. Daher können wir alle Werte in diesem Array auslesen, und auch alle Werte im Speicher der Anwendung, wenn es keine bounds checks gibt.
Der Artikel zu Spectre beschreibt auch eine weitere Attacke, welche den Namen Evict+Load trägt. Eine große Menge an Daten wird in den Cache geladen, anstatt einen flush-Befehl zu nutzen. Auch dadurch wird, wegen der limitierten Cache-Größe, array2 aus dem Cache entfernt. Dies erlaubt es auch JavaScript-Programmen, diesen Angriff auszuführen.
Variant 2: Indirekte Verzweigung
Die zweite Variante folgt einem ähnlichen Konzept. Der Angreifer trainiert die CPU mit einer Adresse, an welcher er das Programm springen lassen möchte.
Wenn die Anwendung jetzt ausgeführt wird, wird die CPU spekulieren, dass das Ziel der Verzweigung das gleiche wie die vorherigen Male ist, und den Code an dieser Stelle spekulativ ausführen. Jetzt können wir wieder Flush+Reload nutzen um einen covert channel zu erstellen.
Fazit
Wie man sehen kann, benötigen beide Varianten von Spectre etwas Wissen über die angegriffene Anwendung und sind auch schwieriger zu entwickeln als Meltdown. Allerdings stellen sie ein höheres Risiko da, da sie nicht so einfach zu beheben sind und beinahe alle modernen CPUs betreffen.
Referenzen
- Kocher, K., Genkin, D., Gruss, D., Haas, W., Hamburg, M., Lipp, M., Mangard, S., Prescher, T., Schwarz, M., Yarom, Y. Spectre Attacks: Exploiting Speculative Execution (2018)