News Summarizer powered by AI Read the news less often
News about Artificial Intelligence A totally automated newspaper called Summarizer. Summarizer uses artificial knowledge to help your daily news shorter. Its bots scour the internet for news, summarise it, and then categorize it. It's a completely computerized newspaper.
Summarizer uses artificial intelligence to make one daily news shorter. Its bots scour the internet for news, summarise it, and then categorize it. Summarizer is only available to $SMR owners. You won't have to spend anything to read Summarizer's contents; all you have to do is hold $SMR. You may sell your $SMR back to the market at any moment if you decide to stop reading Summarizer.

Run, but beware of bots.
The human Summarizer, on the other hand, is operated by a family of bots.
Crawler-bot, summa-bot, editor-bot, delivery-bot, optimizing-bot, repairing-bot, and more bots are available.
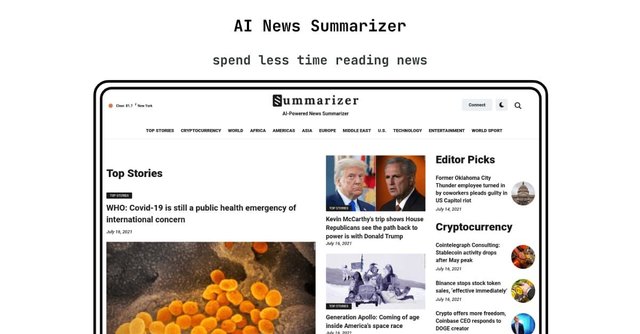
AI-Powered
Using AI to make your daily news shorter
For text summarising, we utilize TextRank with similarity function optimizations.
Elegant and quick
UX and UI have been improved.
There are dark and bright settings, as well as a stripped-down version that is geared for speed. Summarizer articles often load in less than one second.
Telegram
You're a big fan of Telegram, right?
There's good news! There is a bot that is part of the Summarizer bots family that is dedicated to delivering Summarizer material to Telegram channels. There is no need to worry about payments. Due to the fact, there's no payment There is just no subscription cost; you only need to have $SMR in your possession to read Summarizer. If you decide that you no longer want to read Summarizer, you may sell your $SMR back into circulation at any moment.
Privacy
Summarizer does not have a tracker.
Summarizer, in contrast to nearly every other news website, does not contain any code that may be used to monitor your identity or activity.
Algorithm
TextRank is an unsupervised method for the automatic summarization of texts that may also be used to extract the most significant keywords from a document. TextRank was developed by the University of California at Berkeley. Rada Mihalcea and Paul Tarau were the ones who first proposed the idea. When running the method over a graph that was created particularly for the job of summarization, it employs a version of PageRank. In the process, a ranking of the components in the graph is produced: the most significant elements are those that best describe the text in the text. Using this method, the TextRank algorithm can generate summaries without the requirement for a training corpus or labeling, and it can be used for summaries written in a variety of languages.
TextRank models every document as a network, with sentences acting as nodes, in order to perform the task of automatic summarization. It is necessary to have a function that computes the similarity of phrases in order to create edges between them. On this function, the edges of the graph are given a weight based on their resemblance to each other. The greater the similarity between words, the more significant the edge between them will be in the graph. According to the concept of a Random Walker, which is widely employed in PageRank, we are more likely to go from one phrase to another if they are highly similar in content and structure.

TextRank is a method of determining the degree of similarity between two sentences solely on the basis that both sentences include. This overlap is determined by dividing the number of similar lexical tokens between them by the length of each phrase in order to prevent encouraging the use of lengthy sentences. The following is the definition of the similarity function for Si and Sj: The end result of this procedure is a dense graph that represents the document in question. The significance of each vertex in this graph is calculated using the PageRank algorithm based on this graph. As part of the summary, the most significant sentences are chosen and given in the same order as they occur in the text as an example. These suggestions are based on altering the method in which distances between phrases are calculated in order to weigh the edges of the graph that is used to calculate PageRank. Due to the fact that these similarity metrics are orthogonal to the TextRank model, they may be readily included in the overall algorithm. In our research, we discovered that several of these changes produced statistically significant gains over the original method. The Substring with the Longest Common Length We extract the longest common substring from two phrases and provide the similarity as the length of the longest common substring
Cosine Distance is a measure of distance between two points. The cosine similarity meter is a text comparison measure that is commonly used to compare texts that are represented as vectors. We utilized a standard TF-IDF model to represent the texts as vectors, and we computed the cosine between the vectors to determine how similar the documents were.
A term will have a negative value, according to this function definition, if it is used more than half of the time in the collection of documents. The following correction formula was employed to account for this because it might cause issues in the next step of the algorithm: where can take any value between 0.5 and 0.30 and avgIDF represents the average IDF for all words. Other correction techniques, such as setting = 0 and employing simpler versions of the standard IDF formula, were also investigated. BM25+ was also utilized in this study, which is a variant of BM25 that alters the way lengthy documents are punished.
Evaluation
We experimented with several methods of weighting the edges of the TextRank graph, including LCS, Cosine Sim, BM25, and BM25+. Best results were achieved when BM25 and BM25+ were combined with the correction formula indicated in equation 3 to get the best outcomes. When we used BM25 and an of 0.25, we were able to obtain an improvement of 2.92 percent over the initial TextRank result. The results achieved for the various variations that we offered are depicted in the following chart (in red).

Additionally, the results of Cosine Similarity were good, representing a 2.54 percent improvement over the previous approach. The LCS version also outperformed the original TextRank system, with a total improvement of 1.40 percent over the original method.
The ability to complete tasks on schedule has also been increased. We were able to process the 567 documents from the DUC2002 database in 84 percent of the time it would have taken in the previous version of the software.
For more update , visit us
Website: https://summarizer.co
Facebook : https://www.facebook.com/Summarizer-100158469034381
Twitter: https://twitter.com/SummarizerC
Telegram : https://t.me/SummarizerOfficial
Medium : https://medium.com/@summarizer
Reddit : https://www.reddit.com/user/Summarizer_Official
IDO: https://token.summarizer.co/#whitelist
Author By:
Proof Of Registration Link : https://bitcointalk.org/index.php?topic=5350182.msg57629388#msg57629388
BitcoinTalk username : ameliyaketty
My Bitcointalk Profile Link : https://bitcointalk.org/index.php?action=profile;u=2334838
BEP20 (BSC) Wallet Address: 0xDBd77AC33A16d4d7590FCFdA9493eC2555DF4c8F