【JVM】04. 编译运行(二):JIT编译优化
在上一篇博文中,我们深入探讨了JVM的后端编译过程,包括编译执行方式、即时编译器以及分层编译策略。本文作为编译运行专题的第二篇,将详细介绍JIT编译中的一些关键优化技术,包括代码预热、方法内联、逃逸分析、锁消除、栈上分配和标量替换等。
1 代码预热
JIT 编译运用了一些编译优化技术来提高程序的执行效率,减少资源消耗,并提升整体性能,这些优化的前提往往都需要进行热点代码探测。
HotSpot 虚拟机采用的是一种基于计数器的热点探测方法。HotSpot 为每个方法准备了两类计数器: 方法调用计数器和回边计数器。当虚拟机运行参数确定的前提下,这两个计数器都有一个明确的阈值,计数器阈值一旦溢出,就会触发即时编译。
1.1 方法调用计数器
每次调用一个方法时,就记录一次这个方法的执行次数,当执行次数超过某一个阈值,那么这个方法就可以认为是热点方法。
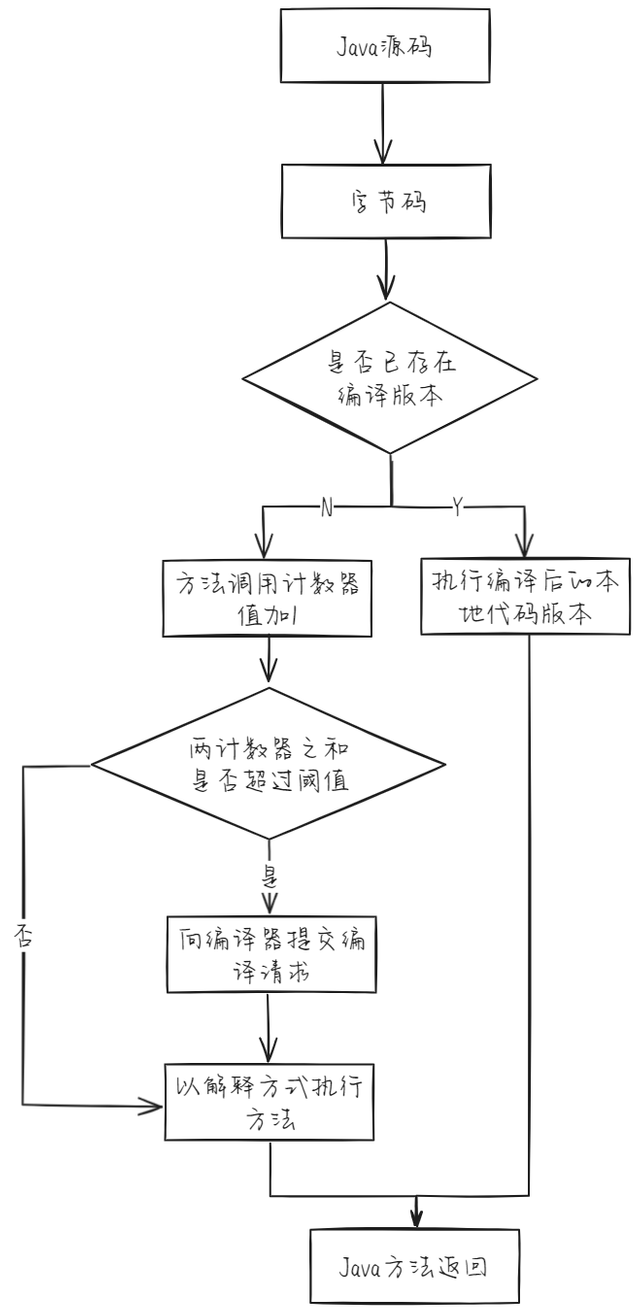
- 当一个方法被调用时,虚拟机会先检查该方法是否存在被即时编译过的版本,如果存在,则优先使用编译后的本地代码来执行
- 如果不存在已被编译过的版本,则将该方法的调用计数器值加一
- 判断方法调用计数器与回边计数器值之和是否超过方法调用计数器的阈值,如果没有超过就继续用解释方式执行
- 如果超过阈值,将会向即时编译器提交一个该方法的代码编译请求
方法计数器的默认阈值是10000次,可以用 java -XX:+PrintFlagsInitial -version 查询,通过虚拟机参数-XX:CompileThreshold来设定。

1.2 回边计数器
统计一个方法中循环体代码执行的次数。在字节码中遇到控制流向后跳转的指令就称为“回边”,很显然建立回边计数器统计的目的是为了发现一个方法内部频繁的循环调用。回边计数器在服务端模式下默认的阈值是 10700。

- 当解释器遇到一条回边指令时,会先查找将要执行的代码片段是否有已经编译好的版本,如果有的话,会优先执行已编译的代码
- 如果不存在已被编译过的版本,则就把回边计数器的值加一
- 判断方法调用计数器与回边计数器值之和是否超过回边计数器的阈值,如果没有超过就继续用解释方式执行
- 当超过阈值的时候,将会向即时编译器提交一个该方法的代码编译请求
- 把回边计数器的值稍微降低一些,以便继续在解释器中执行循环,等待编译器输出编译结果
2 方法内联
- 方法内联的前提:是热点代码->启用方法内联
- 方法内联的优化行为就是把目标方法的代码复制到发起调用的方法之中,避免发生真实的方法调用
// 优化前
private int add1(int s1, int s2, int s3, int s4) {
return add2(s1+s2)+add2(s3+s4);
}
private int add2(int s1, int s2) {
return s1+s2;
}
// 优化后
private int add(int s1, int s2, int s3, int s4) {
return s1+s2+s3+s4;
}
在JDK8中,提供的方法内联相关的参数
-XX:+Inline:启用方法内联。默认开启。-XX:InlineSmallCode=size:用来判断是否需要对方法进行内联优化。如果一个方法编译后的字节码大小大于这个值,就无法进行内联。默认值是1000bytes。-XX:MaxInlineSize=size:设定内联方法的最大字节数。如果一个方法编译后的字节码大于这个值,则无法进行内联。默认值是35byt-XX:FreqInlineSize=size:设定热点方法进行内联的最大字节数。如果一个热点方法编译后的字节码大于这个值,则无法进行内联。默认值是325bytes。-XX:MaxTrivialSize=size:设定要进行内联的方法的最大字节数(Trivial Method:通常指那些只包含一两行语句,并且逻辑非常简单的方法)-XX:+PrintInlining:打印内联决策,通过这个指令可以看到哪些方法进行了内联。默认是关闭的。另外,这个参数需要配合-XX:+UnlockDiagnosticVMOptions 参数使用。
提高内联发生的概率的方式
- 在编程中,尽量多写小方法,避免写大方法。方法太大不光会导致方法无法内联,另外,成为热点方法后,还会占用更多的CodeCache。
- 在内存不紧张的情况下,可以通过调整JVM参数,减少热点阈值或增加方法体阈值,让更多的方法可以进行内联。
- 尽量使用final, private,static关键字修饰方法。方法如果是继承的(也就是需要使用invokevirtual指令调用),那么具体调用的方法,就只能在运行这一行代码时才能确定,编译器很难在编译时得出绝对正确的结论,也就加大了编译执行的难度。
3 逃逸分析
就是分析对象动态作用域,当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中。
public User test1() {
User user = new User();
user.setId(1);
user.setName("haha");
//TODO 保存到数据库
return user;
}
public void test2() {
User user = new User();
user.setId(1);
user.setName("haha");
//TODO 保存到数据库
}
很显然test1方法中的user对象被返回了,这个对象的作用域范围不确定,test2方法中的user对象我们可以确定当方法结束这个对象就可以认为是无效对象了,对于这样的对象其实可以将其分配在栈内存里,让其在方法结束时跟随栈内存一起被回收掉。
JVM对于这种情况可以通过开启逃逸分析参数(-XX:+DoEscapeAnalysis)来优化对象内存分配位置,使其通过标量替换优先分配在栈上(栈上分配),JDK7之后默认开启逃逸分析,如果要关闭使用参数(-XX:-DoEscapeAnalysis)
3.1 锁消除
- 锁消除的前提:是热点代码->启用逃逸分析—>启用锁消除
- 在动态编译同步块的时候,JIT编译器可以借助逃逸分析来判断,如果锁对象只能被一个线程访问,那么就会取消对这部分代码的同步
- JVM参数
-XX:-EliminateLocks可以主动关闭锁消除
// 优化前
public void f() {
Object hollis = new Object();
synchronized(hollis) {
System.out.println(hollis);
}
}
// 优化后
public void f() {
Object hollis = new Object();
System.out.println(hollis);
}
3.2 栈上分配+标量替换
- 栈上分配的前提:是热点代码->启用逃逸分析—>启用标量替换
- 通过逃逸分析确定该对象不会被外部访问,并且对象可以被进一步分解时,JVM不会创建该对象,而是将该对象成员变量分解若干个被这个方法使用的成员变量所代替。这些代替的成员变量在栈帧或寄存器上分配空间,这样就不会因为没有一大块连续空间导致对象内存不够分配。
- 开启标量替换参数(
-XX:+EliminateAllocations),JDK7之后默认开启
3.3 栈上分配示例
/**
* 栈上分配,标量替换
* 代码调用了1亿次alloc(),如果是分配到堆上,大概需要1GB以上堆空间,如果堆空间小于该值,必然会触发GC。
*
* 使用如下参数,开启逃逸分析和标量替换不会发生GC
* -Xmx15m -Xms15m -XX:+DoEscapeAnalysis -XX:+PrintGC -XX:+EliminateAllocations
* 使用如下参数,关闭逃逸分析或者标量替换都会发生大量GC
* -Xmx15m -Xms15m -XX:-DoEscapeAnalysis -XX:+PrintGC -XX:+EliminateAllocations
* -Xmx15m -Xms15m -XX:+DoEscapeAnalysis -XX:+PrintGC -XX:-EliminateAllocations
*/
public class AllotOnStack {
public static void main(String[] args) {
long start = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
alloc();
}
long end = System.currentTimeMillis();
System.out.println(end - start);
}
private static void alloc() {
User user = new User();
user.setId(1);
user.setName("haha");
}
}
4 结语
本文主要介绍了 Java 虚拟机中的 JIT 编译技术,包括热点代码探测、方法内联、逃逸分析、锁消除、栈上分配和标量替换等优化技术。这些技术共同作用,可以显著提高程序的执行效率,减少资源消耗,并提升整体性能。
- 热点代码探测是 JIT 编译的基础,通过方法调用计数器和回边计数器来确定哪些代码是热点代码,即频繁执行的代码。当热点代码被识别后,JIT 编译器会将这些代码编译为本地代码,以提高执行效率。
- 方法内联是将目标方法的代码复制到发起调用的方法中,避免真实的方法调用,从而减少调用开销。
- 逃逸分析用于确定对象的动态作用域,如果对象的作用域仅在方法内部,那么可以将其分配在栈上,而不是堆上,从而减少内存消耗。
- 锁消除和标量替换是逃逸分析的两个重要应用。锁消除可以取消对只被一个线程访问的锁的同步,标量替换则是将对象分解为成员变量,以减少内存消耗。
通过调整 JVM 参数,可以控制这些优化技术的开启和关闭,以及调整它们的阈值,以适应不同的应用场景。
总的来说,JIT 编译技术是 Java 虚拟机中一项重要的性能优化技术,通过热点代码探测、方法内联、逃逸分析等技术,可以显著提高程序的执行效率,减少资源消耗,并提升整体性能。