A: What is clustering in Data Science?
In a data-science context, clustering refers to organizing data into categories by using some sort of distance metric. "K-means clustering" is a common technique for doing so, but other clustering algorithms exist. An example of applying K-means clustering to a two-dimensional data set is shown below. The points have been grouped into three different clusters, and each cluster represented by a color:
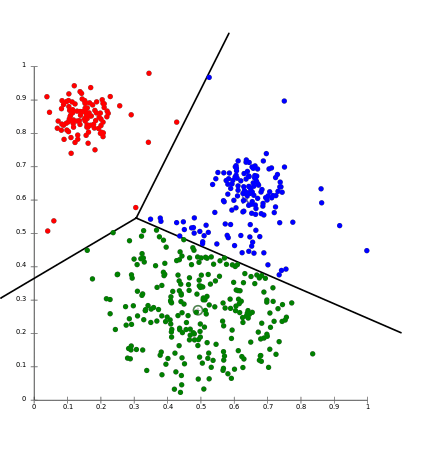
(Source: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/)
Abstractly, clustering takes a large set of data points and a distance function between each pair of points. It assigns each data point a label, called a "cluster".
The goal in clustering is to find data points that "belong together" in some way. This can be used purely as a descriptive/explanatory model, but also as a predictive model. In the latter case, new data points are assigned to a category based on their distance from the clusters discovered during training. You would typically use a clustering technique when the data points you have aren't already labelled with a "correct" answer.
For example, suppose you have a large set of Steemit posts, represented by word vectors or tag vectors. A word vector is just a count of how often each word appears in the post. One analysis you might run is to find posts that are similar to each other, in terms of which words or tags they use. Similar posts can be labelled as a "cluster" which could correspond to a particular topic (or language, or even author.) I did an example of this sort of analysis here, using tags: https://steemit.com/steemstem/@markgritter/topic-extraction-from-steem-tags
The "distance" between data points can be very abstract. For word vectors, it is typical to use the standard Euclidean distance definition, treating the articles as points in a multi-dimensional space, with one dimension per word. "Distance" could also mean the number of edits required to change one string to another; this definition is often used in genomics. Or, the distance could be very concrete; it is possible to do clustering based on geographical location.
StemQ Notice: This post was originally submitted on StemQ.io, a Q&A application for STEM subjects powered by the Steem blockchain.
This post has been voted on by the SteemSTEM curation team and voting trail in collaboration with @curie.
If you appreciate the work we are doing then consider voting both projects for witness by selecting stem.witness and curie!
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
Just to give an extra example, jet clustering techniques are used on a daily basis in particle physics. At colliders, the production of a single quark or gluon leads to hundreds of particles that must be clustered into what we call a jet. The clustering algorithm is based on a specific distance taking into account the momenta and energies of the hundreds of out-going particles.
Hi Mark,
Thank you for your excellent answer.
It's clear that I got confused by the question and did not answer it in the right context.
I will withdraw my answer so as not to confuse others.
Cheers,
-irelandscape