Estadística multivariada II: Análisis e interpretación de datos electrofisiológicos y morfométricos de Periplaneta americana mediante tres herramientas estadísticas confirmatorias
Vengo a presentarles la continuación de mi trabajo ( pueden revisar la primera parte aquí .) sobre el análisis e interpretación de datos mediante estadística multivariada usando uno de mis proyectos sobre el efecto sobre la electrofisiología de la cucaracha común (Periplaneta americana) al aplicarle veneno de ciempiés gigante (Scolopendra gigantea). Las herramientas estadísticas (Análisis discriminante múltiple, de agrupamiento y regresión múltiple lineal) y los programas utilizados (IBM SPSS Statistics v. 20 y Minitab v. 16) en los que profundizaremos para el estudio de los fenómenos biológicos y la confirmación de las hipótesis alrededor de estos fenómenos están explicados paso a paso con la finalidad de hacerlos accesibles y de fácil entendimiento a un público más amplio.
Análisis discriminante múltiple
(Programa utilizado: IBM SPSS Statistics v. 20) (Variable que agrupa: Longitud total de la cucaracha)
Introducción
Garnica y colaboradores en su trabajo del 1991 escribieron:
El análisis discriminante múltiple (AFD), cuyo término (discriminación) fue introducido por R. A. Fisher, en 1936, en el primer tratamiento moderno de problemas separatorios, es una técnica multivariante orientada fundamentalmente a lograr dos objetivos básicos:• Explorar y analizar las posibles diferencias que pueden existir entre g poblaciones excluyentes, previamente definidas por el investigador, en base las diferencias que puedan presentar en las p variables medidas. Se trata de hallar funciones que dependan de esas p variables originales que separen los g grupos tanto como sea posible. Por ejemplo, se desea clasificar a las familias de una ciudad en tres (g = 3) niveles socioculturales: bajo, medio y alto, en base a cuatro (p = 4) variables: grado de instrucción del padre, grado de instrucción de la madre, número de libros en el hogar y número de suscripciones a publicaciones periódicas.• A partir del criterio de discriminación obtenido se puede proceder a incluir un nuevo elemento en algunos de los grupos formados. Este es el caso de los individuos que no se les conoce a priori el grupo al cual pertenece, entonces el AFD permite clasificarlos sobre la base de ecuaciones matemáticas, derivadas del análisis de los casos con pertinencia conocida. En el ejemplo anterior, una vez conocidas las funciones discriminantes, se tiene la posibilidad de saber en qué grupo o nivel sociocultural se puede ubicar una familia que no fue seleccionada en el estudio inicial.Análisis discriminante: estudio del rendimiento estudiantil (Garnica y colaboradores).
Resultados y discusión
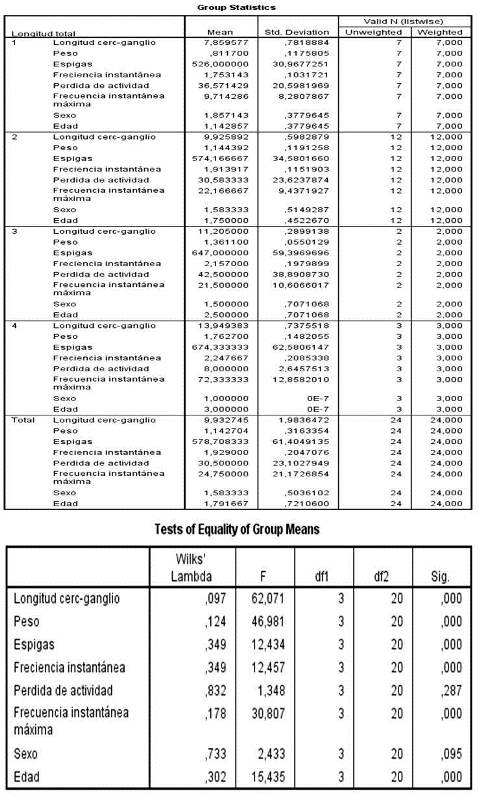
Figura 1. (De arr. a aba.) Estadística descriptiva de los 4 grupos propuestos. Prueba de igualdad de las medias de los grupos.
El primer grupo constó de 7 individuos, el segundo de 12, el tercero de 2 y el cuarto de 3 individuos para dar un total de 24 individuos, es decir, en este análisis se procesaron todos los casos como válidos, como puede observarse en la figura 1. Por otra parte, en la matriz de igualdad de medias se utilizó la prueba Lambda de Wilks para evidenciar la significación estadística de las medias de todas las variables, llegando a la conclusión que solo dos de las medias observadas (Pérdida de actividad y Sexo) no cumplen con ser estadísticamente significativas, aun así, la mayor parte de las variables estudiadas muestran medias que provienen de distribuciones diferentes, esto a modo de prueba pre aplicación del análisis, es decir, antes de la creación del modelo.
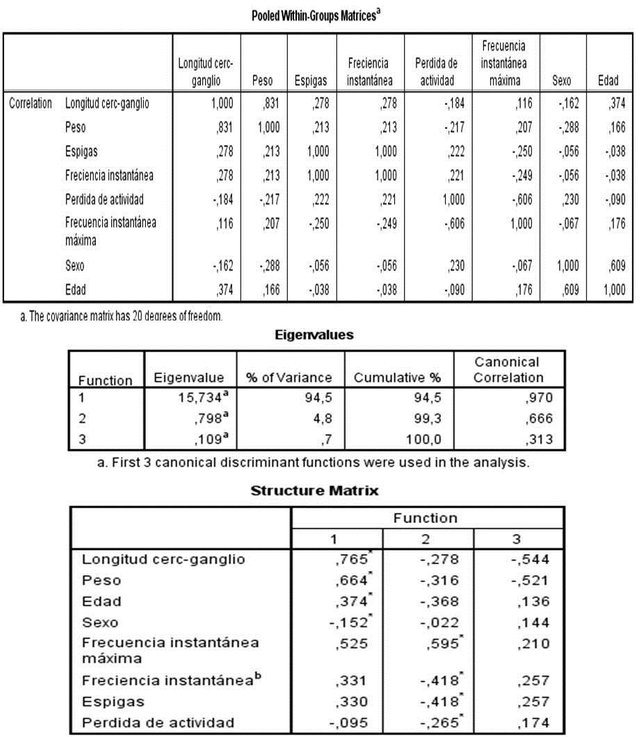
Figura 2. (De arr. a aba.) Matriz de covarianza intragrupos. Valores propios para las distintas funciones canónicas. Matriz de estructura.
La matriz de covarianza intragrupos (figura 2) muestra índices bajos entre las variables, es decir, se observan los valores que indican el grado de variación conjunta de dos variables aleatorias, al ser un valor cercano a cero, se interpreta como poca dependencia entre ambas variables, se corrobora luego, la dirección de la relación reflejado en valores positivos o negativos de la covarianza. Por ejemplo: hay una alta dependencia entre la cantidad de espigas y la frecuencia instantánea, desde el punto de vista físico resulta que la frecuencia instantánea de una señal modulada es proporcional al valor instantáneo de la señal moduladora, en este caso la señal moduladora es el conjunto de espigas de un registro. Asimismo, hay una alta dependencia positiva entre el peso y la longitud entre el ganglio y los cercos, debido entonces al aumento de masa necesario para incrementar la longitud del cuerpo del insecto.
La tabla de valores propios revela la correlación canónica para la función discriminante. Cuanto mayor es el valor propio, más cantidad de varianza compartida resulta de la combinación lineal de variables. La segunda columna de la tabla, porcentaje de varianza pone de manifiesto la importancia de la función discriminante y la tercera columna proporciona el porcentaje acumulado de la varianza. La cuarta columna, correlación canónica proporciona el coeficiente de correlación canónica para cada función. Puede ser utilizado para comparar la importancia de cada función discriminante y siempre va en orden decreciente.
Por otro lado, se representan las correlaciones entre las variables observadas y las funciones discriminantes o dimensiones en la parte inferior de la figura 2, en este caso, los mayores valores de esta tabla se encuentran distribuidos entre las primeras dos funciones discriminantes, puede ser usada para determinar que tanta información de una variable se encuentra en una función en específico entre los grupos que se han propuesto.
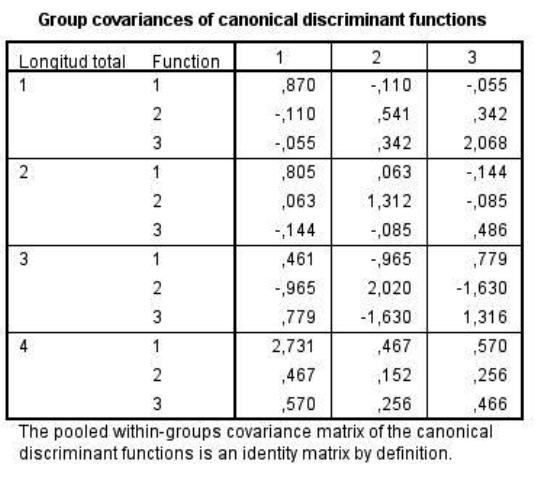
Figura 3. Covarianzas de los grupos con respecto a las funciones canónicas discriminantes.
En la figura 3 se observa el grado de relación entre cada grupo propuesto y la función canónica discriminante, observando en líneas generales los mayores valores en la primera función canónica, lo cual significa que la mayor parte de los grupos observados estarían bien caracterizados por dicha función. Se aplicó también la prueba M de Box para homogeneidad de la covarianza en las matrices y se puede concluir que ninguno de los cuatro grupos es mucho más variable que el resto.
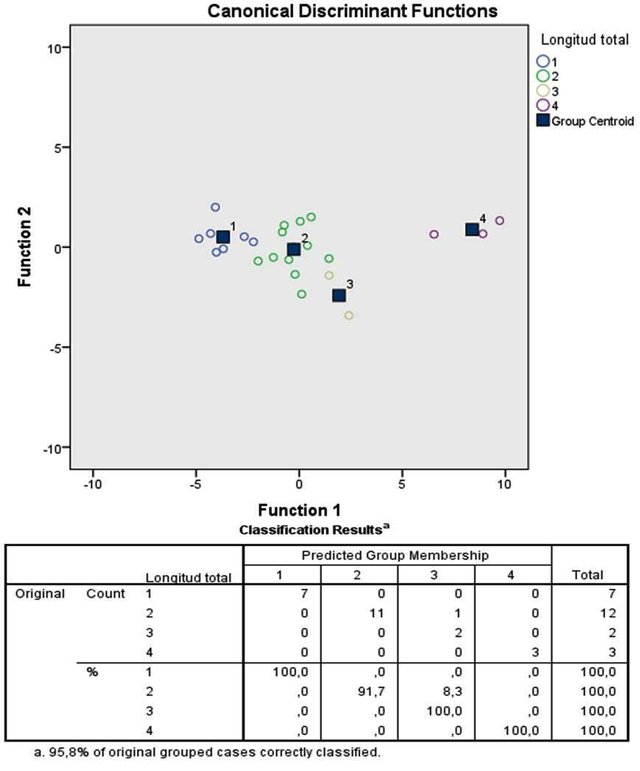
Figura 4. (De arr. a aba.) Gráfica de las funciones canónicas discriminantes con los casos. Resultados de la clasificación.
Se puede observar en la figura 4 los 4 grupos de longitud total diferenciados por color, los individuos del grupo 1 son machos jóvenes, los del grupo 2 y 3 son machos adultos y hembras jóvenes y finalmente, los del 4to grupo son hembras adultas, de las cuales 2 poseían ooteca. Finalmente se logró agrupar el 95,8% de los casos correctamente, esto quiere decir que, dentro de la muestra estudiada más del 95% se corresponde con el grupo original de la matriz de datos inicial una vez que el programa extrae cada individuo del total y lo reintroduce para estudiar las habilidades predictivas del modelo generado, se asume entonces que gracias a dicho modelo cualquier individuo de Periplaneta americana que cumpla con las variables de interés medidas en la población tiene una probabilidad de 0,95 de ser introducido en el grupo correcto según el modelo global aquí estudiado.
Análisis de conglomerados
(Minitab v 16)
Introducción
El análisis de conglomerados (cluster) es una técnica multivariante que busca agrupar elementos (o variables) tratando de lograr la máxima homogeneidad en cada grupo y la mayor diferencias entre los grupos. Nos basaremos en los algoritmos jerárquicos acumulativos (forman grupos haciendo conglomerados cada vez más grandes), aunque no son los únicos posibles. El dendograma es la representación gráfica que mejor ayuda a interpretar el resultado de un análisis cluster (Terrádez, 2005).
Resultados y Discusión
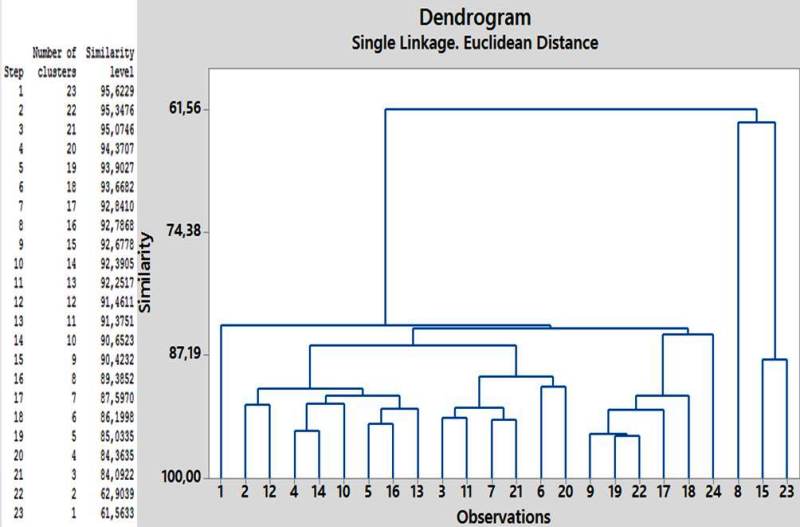
Figura 5. Dendrograma para las observaciones/casos.
Se observan en la figura 5 los conglomerados de casos según su porcentaje de similitud, dado un conjunto de individuos (n=24) caracterizados por la información de las nueve variables medidas, se logró clasificarlos de manera que los individuos pertenecientes a un grupo (cluster) sean tan similares entre sí como sea posible, siendo los distintos grupos entre ellos tan disimilares como sea posible. En este caso, hay dos grupos separados por aproximadamente un 26% de similitud, correspondientes a los grupo 4 y el conjunto de 3, 2 y 1 de la prueba análisis discriminante múltiple.
Regresión lineal múltiple
(IBM SPSS v 20) (Variable dependiente: Frecuencia instantánea)
Introducción
El Análisis de Regresión Lineal Múltiple nos permite establecer la relación que se produce entre una variable dependiente Y y un conjunto de variables independientes (X1, X2, ... , XK). El análisis de regresión lineal múltiple, a diferencia del simple, se aproxima más a situaciones de análisis real puesto que los fenómenos, hechos y procesos sociales, por definición, son complejos y, en consecuencia, deben ser explicados en la medida de lo posible por la serie de variables que, directa e indirectamente, participan en su concreción. Al aplicar el análisis de regresión múltiple lo más frecuente es que tanto la variable dependiente como las independientes sean variables continuas medidas en escala de intervalo o razón. No obstante, caben otras posibilidades: (1) también se puede aplicar este análisis cuando se relacionen una variable dependiente continua con un conjunto de variables categóricas; (2) o bien, en el caso de variable dependiente nominal con un conjunto de variables continuas (Rodríguez & Morar, 2001).
El modelo de regresión lineal múltiple, como lo indica el investigador José Rojo (2007) es idéntico al modelo de regresión lineal simple, con la única diferencia de que aparecen más variables explicativas:
Modelo de regresión simple: y = b + b1 ⋅ x + u
Modelo de regresión múltiple: y = b0 + b1 ⋅ x1 + b2 ⋅ x2 + b3 ⋅ x3 + b4 ⋅ x4 + ... + bk ⋅ xk + u
Entonces, el modelo resultante en este caso en particular donde la frecuencia instantánea es la variable dependiente y el resto como posibles variables explicativas sería:
Frecuencia instantánea= b0 + b1 ⋅ Long. total + b2 ⋅ Long. Cerc-ganglio + b3 ⋅ Peso + b4 ⋅ Núm. espigas + b5 ⋅ Sexo + b6 ⋅ Edad + b7 ⋅ Perd. Actividad + b8 ⋅ Frec. inst. máxima
Al igual que en regresión lineal simple, los coeficientes b indican el incremento en la frecuencia instantánea por el incremento unitario de la correspondiente variable explicativa.
Resultados y Discusión
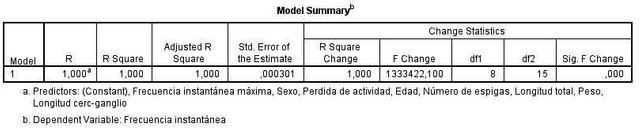
Figura 6. Resumen del modelo. ANOVA.
Hay una alta correlación (figura 6) entre la mayor parte de las variables, siendo en su mayoría estadísticamente significativas (observado en la parte inferior de Correlaciones). Por otro lado, se rechaza la hipótesis nula de que la variabilidad observada en la variable respuesta sea explicable por el azar, y se admite entonces que hay algún tipo de asociación entre la variable dependiente (frecuencia instantánea) y las independientes mediante la prueba ANOVA con un p-valor de 0. Para medir la bondad del ajuste tenemos en el resumen del modelo el término R cuadrado y R cuadrado corregido, ambos iguales a 1, siendo estadísticamente significativos, lo cual significa que las fluctuaciones en la frecuencia instantánea en los registros pueden explicarse por el resto de las variables medidas.
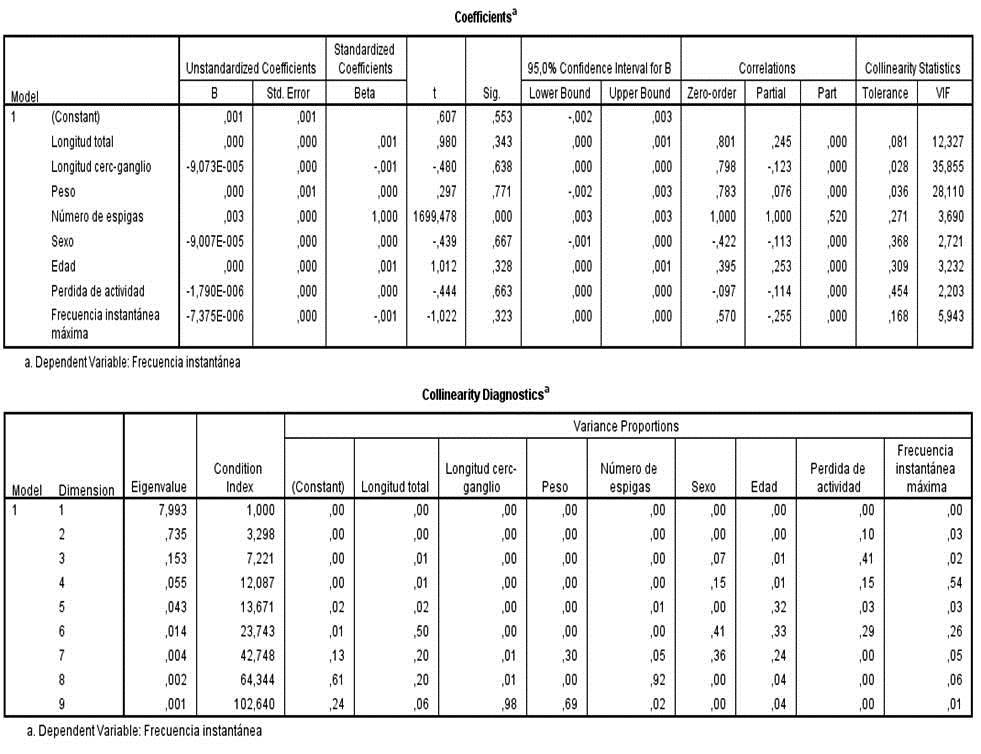
Figura 7. (De arr. a aba.) Coeficientes y diagnósticos de colinealidad.
Los coeficientes denotan la magnitud del efecto de las variables explicativas (exógenas o independientes), esto es, representan los pesos de la regresión o de la combinación lineal de las predictoras sobre la variable explicada (endógena o dependiente) Y. El coeficiente b0 se denomina término constante (o independiente) del modelo. Se define el coeficiente de correlación múltiple R como la raíz cuadrada del coeficiente de determinación y mide la correlación entre la variable dependiente y las independientes.
El Coeficiente de correlación parcial entre Xi e Y mide la correlación entre estas variables cuando se han eliminado los efectos lineales de las otras variables en Xi e Y.
El Coeficiente de correlación semiparcial entre Xi e Y es la correlación entre estas variables cuando se han eliminado los efectos lineales de las otras variables en Y.
En regresión múltiple, los coeficientes de regresión estandarizados permiten valorar la importancia relativa de cada variable independiente dentro de la ecuación/sistema.
Se observa en la figura 7 que para las variables estudiadas hay una fuerte correlación, además de una baja tolerancia y alta inflación, todos estos parámetros señalan la existencia de multicolinealidad en el sistema. Se dice que existe multicolinealidad entre las variables explicativas cuando existe algún tipo de dependencia lineal entre ellas. La correlación no solamente se refiere a las distintas variables dos a dos, sino a cualquier de ellas con cualquier grupo de las restantes. El principal inconveniente de la multicolinealidad consiste en que se incrementan la varianza de los coeficientes de regresión estimados hasta el punto que resulta prácticamente imposible establecer su significación estadística.
En este sistema regido por la multicolinealidad no vale la pena realmente interpretar las gráficas respectivas o generar un análisis de rutas, ya que carecerían de significado estadístico y o biológico. Esto resulta lógico, ya que la complejidad del sistema nervioso es bien conocida tanto en la medicina como en la biología, aun siendo un insecto, hay muchas variables que podrían predecir algunas variables electrofisiológicas que no fueron medidas por falta de recursos, de tiempo o simplemente porque no formaban parte del objetivo de la investigación original. Se espera entonces que futuras investigaciones logren encontrar y proponer algún modelo de regresión y análisis de rutas que relacione variables morfométricas y electrofisiológicas exitosamente.
REFERENCIAS BIBLIOGRÁFICAS
1. Garnica E., González, P., Díaz, A. & Torres, E. 1991. Análisis discriminante: Estudio del rendimiento estudiantil. Departamento de Química. Ediciones de la Facultad de Ciencias de la Universidad de los Andes. 1:63-95PP. Mérida. Venezuela.
2. Terrádez, M. 2005. Análisis de conglomerados. Proyecto e-Math. Ediciones de la Universidad Abierta de Cataluña. España.
3. Rodríguez, M. & Morar, R. 2001. Estadística informática: casos y ejemplos con SPSS. Capítulo 4. 3-17pp. España.
4. Rojo, J. 2007. Regresión lineal múltiple. Laboratorio de estadística. Ediciones del Instituto de Economía y Geografía. Capítulo 2. 1-31pp. España.
Hola @khrisaeroth El equipo de curación de Proyecto Witness Cervantes encargado de curar contenido técnico y científico considera que tu post es de gran calidad, original y útil. Hemos notado que aunque has colocado el post en nuestros canales para ser votado, no has colocado nuestra etiqueta. Te invitamos a usarlas para continuar apoyándote, creemos que debe ser mútuo. Tags: Cervantes Cervantes-Ciencia Saludos!
Vale, de ahora en adelante así haré. ¡Muchísimas gracias por el apoyo!