THE CHEMICALS OF LIFE: Analyzing Proteins, Collagen, and Nucleic Acid.
Greetings to my dear readers and the entire
steemstem community. Thanks for the constant support, I really do appreciate.
This post is a continuation from where I stopped in my last post on THE CHEMICALS OF LIFE: Steroids in Athletics and the Importance of Protein to Living Organisms and THE CHEMICALS OF LIFE: Reducing Sugars, Polysaccharides and Lipids.
We can find out if a sample contains protein using the Biuret test. More complex biochemical techniques can be used to tell us more about proteins in living systems. We can:
- find out which proteins are present in a mixture, such as plasma,
- work out the exact three-dimensional shape of a protein using techniques such as X-ray diffraction and nuclear magnetic resonance,
- find out which amino acids are present in a particular protein,
- analyze the exact amino acid sequence of a protein,
- use computers to predict the three-dimensional shape of a protein, using only its amino acid sequence.
Identifying individual proteins
The proteins present in a body fluid such as blood plasma can be separated from each other by electrophoresis. Each protein carries a particular overall electrical charge. Electrophoresis uses this fact to separate individual proteins.
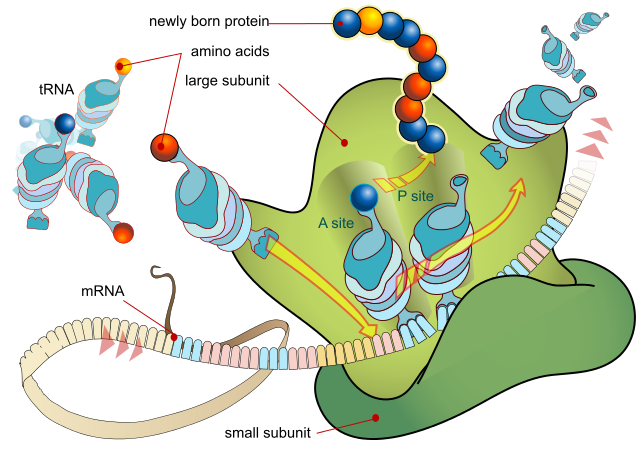
A ribosome produces a protein using mRNA as template. LadyofHats, Public Domain
{kind=link}
Working out the three-dimensional shape of a protein
X-ray diffraction is useful here. When a beam of X-rays is fired at a crystal of purified protein, the atoms in that protein diffract (bend) the X-rays, producing a specific pattern on a photographic plate. The shape of a protein is not immediately obvious from the information produced, but a trained scientist with a computer can produce an accurate three-dimensional model of the molecule.
Identifying which amino acids are present
Protease (protein-degrading) enzymes break up the protein and then the constituent amino acids are identified using chromatography or electrophoresis. These techniques do not reveal the sequence of amino acids.
Determining the amino acid sequence
The protein is digested into manageable chain lengths of amino acids and each length is analysed in turn. The polypeptide is treated with a chemical that binds to the N-terminal (N-end) amino acid but not to any of the others. The ‘tagged’ terminal amino acid is removed from the rest of the chain and identified by chromatography. Frederick Sanger, who won a Nobel Prize in the 1950s, was the first scientist to sequence a complete protein (insulin). Today, the process is fully automated and has become a standard technique.
Computer modelling
As biochemists accumulate knowledge about the structure of many individual proteins, they produce computer software to help work out the shape of other complete proteins using their amino acid sequences. This is incredibly useful in genetics. Sometimes a new gene is sequenced and no one knows its function. The DNA sequence can be given to a computer which then works out the sequence of amino acids that would be produced if the gene were expressed in a cell. It can then ‘build’ the final protein and compare it to other proteins with known functions.

{kind=link}
Collagen
Collagen is probably the most widespread structural protein in the human body. It is a fibrous protein that gives strength to tissues such as tendons, ligaments, bone and skin. The figure below shows the structure of collagen. A single collagen molecule contains three polypeptides – each of about 1000 amino acids – intertwined to form a triple helix. This arrangement has great strength, mainly due to the large number of hydrogen bonds that occur along the length of the polypeptides.
Collagen is secreted in an unassembled form because the instant formation of large fibres would damage the cell that made it. Complete collagen is produced as enzymes act on the individual polypeptides, causing them to twist together to form very long fibres (sometimes several millimetres long). These have the tensile strength of steel and are used to strengthen bone in much the same way as metal rods reinforce concrete. Brittle bone disease is a genetic disorder which results in a fault in the bonding between collagen and the mineral component of bone.
The primary structure of collagen is very regular. It consists of a repeating sequence of glycine and two other amino acids, often proline and hydroxyproline. These amino acids do not cause the chain to gain the normal α-helix or β-sheet structure. Instead, they form long, separate chains that allow the collagen triple helix to form. This is a good example of how the primary structure is ultimately responsible for the shape and properties of the whole protein.
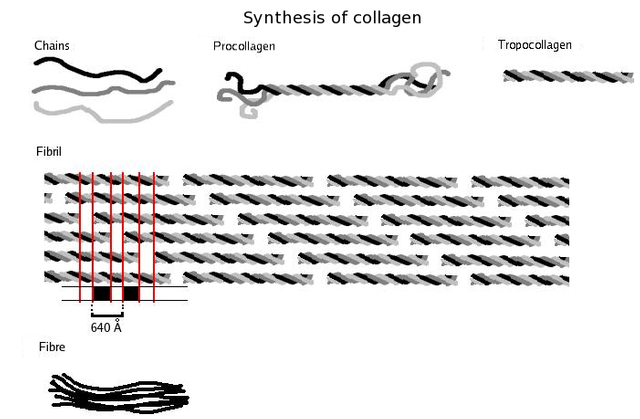
.png){kind=link}
NUCLEIC ACIDS
Nucleic acids are so called because they are slightly acidic molecules, and because it was originally thought that they occurred only in the nucleus. The two types of nucleic acid, DNA and RNA, both contain carbon, hydrogen, oxygen, nitrogen and phosphorus.
THE STRUCTURE OF NUCLEIC ACIDS
Nucleotides are the building blocks of nucleic acids. A nucleotide consists of three units: a sugar (ribose or deoxyribose), a phosphate group, a nitrogen-containing base.
As the names imply, deoxyribonucleic acid has nucleotides in which the sugar is deoxyribose, while ribonucleic acid contains the sugar ribose.
DEOXYRIBONUCLEIC ACID
Deoxyribonucleic acid (DNA) is the macromolecule that carries the genetic code, the information for making the cell’s proteins. Most of the DNA in a eukaryotic cell is in the nucleus. The nucleotides in DNA can contain any one of four nitrogenous (nitrogen-containing) bases: adenine, guanine, cytosine or thymine. When DNA replicates (copies itself), it makes new strands by adding nucleotides. These are available as free molecules in the cytoplasm. Generally, cells can synthesise their own nucleotides.
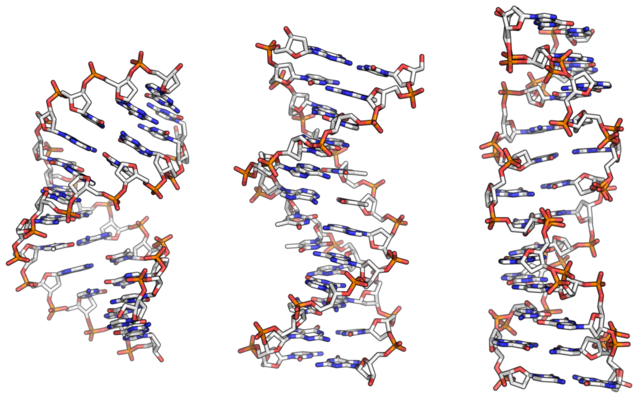
From left to right, the structures of A, B and Z DNA. Richard Wheeler (Zephyris), Public Domain
How DNA carries the genetic code
DNA has two remarkable characteristics: It is a store of genetic information and It can copy itself exactly, time after time. Looking at the structure of DNA helps us to understand how it does this.
How the bases pair
Adenine and guanine belong to a group of chemicals called purines while thymine and cytosine are pyrimidines. Because of the shape of the two types of molecule, each purine always bonds with only one pyrimidine. So, in DNA, adenine always bonds with thymine, and cytosine with guanine. In RNA, cytosine bonds with guanine and adenine bonds with a fifth base, uracil:
DNA: A=T RNA: A=U
G≡C G≡C
The base pairs are held together by hydrogen bonds. There are two H-bonds between A and T (or U) and three between C and G.
Hint: to remember which bases are pyrimidines and which are purines, concentrate on the letter Y: thymine and cytosine are pyrimidines while adenine and guanine are purines.
The figure below shows how the base pairs within DNA fit together to form a double-stranded helix. The sides are formed by alternating sugar-phosphate units, while the base pairs form the cross-bridges, like the rungs of a ladder. Each base pairing causes a twist in the helix and there is a complete 360° turn every 10 base pairs.
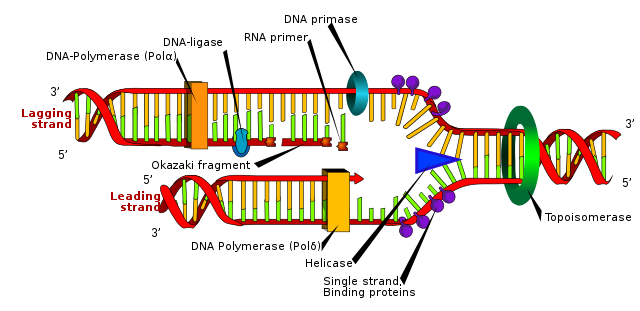
{kind=link}
RIBONUCLEIC ACID
Three of the bases in ribonucleic (RNA) – adenine, guanine and cytosine – the same as those in DNA. The fourth is different: RNA contains uracil instead of thymine. RNA molecules are much smaller than DNA molecules. DNA can consist of over 300 000 000 nucleotides; RNA usually consists of a few hundred. RNA is also less stable. DNA molecules are the permanent store for genetic information and last for many years. In contrast. RNA molecules have a short-term function and are easily replaced. There are three forms of ribonueleic acid (RNA) in the cell:
- Messenger RNA (mRNA) can be thought of as a mobile copy of a gene. Small lengths of mRNA are assembled in the nucleus using a single gene within the DNA as a template. When a complete copy of the gene has been produced, the mRNA moves out of the nucleus to the ribosome, where the protein is synthesised according to the code taken from the DNA.
- Transfer RNA is found in the cytoplasm and is a carrier molecule, bringing amino acids to the ribosomes for assembly into a new amino acid chain, according to the order specified on the mRNA code.
- Ribosomal RNA makes up part of the ribosome, a small organelle that brings together all the chemicals associated with protein synthesis.
{kind=link}
CONCLUSION
When you have finished all these chapters on the chemicals of life as I have highlighted at the beginning of this post, you should have known and understood the following:
CARBOHYDRATES: Carbohydrates contain the elements carbon, hydrogen and oxygen. They are the first products made by plants in photosynthesis. The term sugars describes monosaccharides and disaccharides. Their names end in the suffix -ose. Monosaccharides include glucose, fructose and galactose. These sugars are isomers: they have the same formula but their atoms are arranged in different ways. Monosaccharides are linked by glycosidic bonds. These are formed by condensation reactions.
Also, disaccharides, such as maltose, sucrose (cane sugar) and lactose (milk sugar), consist of two monosaccharides linked together. Most polysaccharides are polymers of glucose. Starch is used for storage in plants, glycogen is used for storage in animals, and cellulose gives strength to plant cell walls.
LIPIDS: Lipids contain carbon, hydrogen, oxygen, often phosphorus and occasionally nitrogen. Most are non-polar chemicals and therefore insoluble in water. Lipids are used for energy storage, protection and insulation. In living things there are two main types of lipids: triglycerides and phospholipids. Triglycerides are the familiar fats and oils. Phospholipids form cell membranes.
Fatty acids vary in chain length, and may be saturated (with hydrogen) or unsaturated. These factors determine the properties of the triglyceride, such as its melting point and viscosity. Phospholipids are similar to triglycerides, but phosphoric acid replaces one of the fatty acids. They have a polar head, allowing them to form bilayers (membranes) in water. Cholesterol is a normal constituent of cell membranes.
PROTEINS: Proteins consist of chains of amino acids linked by peptide bonds. There are 20 different amino acids in living things. All have a carboxylic acid group and an amino group but differ in their R group. Fibrous proteins often join to form large fibrils whose function is to provide strength or produce movement. Globular proteins – including enzymes, antibodies and some hormones – are usually individual molecules with a chemical function.
The primary structure of a protein is the sequence of its amino acids. The secondary structure refers to the patterns and shapes formed within the polypeptide chain, for example, an α-helix. The tertiary structure refers to the three-dimensional shape of a polypeptide chain, which results from the interactions as the chain folds back on itself. If the protein consists of one polypeptide chain, the tertiary structure refers to the overall shape of the molecule. The quaternary structure refers to the overall three-dimensional shape of a protein that consists of more than one polypeptide chain.
NUCLEIC ACIDS: There are two types of nucleic acid, deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). RNA itself has three forms, messenger RNA, transfer RNA and ribosomal RNA. DNA carries the genetic code. Its structure allows it to store information, pass information on to RNA so that proteins can be made, and to copy itself, allowing the genetic code to pass to new cells.
Messenger RNA copies the genes, to allow them to be used as templates for protein synthesis. Transfer RNA brings amino acids to the ribosome during synthesis. Ribosomal RNA is a major structural component of the ribosome. DNA and RNA are composed of nucleotides, which themselves contain a sugar, a phosphate group and a nitrogen-containing base. DNA contains the bases A, C, T and G. RNA contains the bases A, C, U and G. A always pairs with T (or U) and C always pairs with G.
REFERENCES
https://en.wikipedia.org/wiki/Protein_methods
https://www.biocompare.com/Lab-Equipment/7608-Protein-Analysis-Protein-Characterization/
https://www.ncbi.nlm.nih.gov/books/NBK26820/
https://www.atascientific.com.au/3-protein-analysis-techniques/
https://www.ncbi.nlm.nih.gov/books/NBK22571/
https://study.com/academy/lesson/using-dna-to-identify-an-amino-acid-sequence.html
https://www.genetics.org/content/162/2/527
https://en.wikipedia.org/wiki/Frederick_Sanger
https://www.nature.com/subjects/computer-modelling
https://en.wikipedia.org/wiki/Collagen
https://www.healthline.com/nutrition/collagen
https://www.medicalnewstoday.com/articles/262881.php
https://en.wikipedia.org/wiki/Nucleic_acid
https://www.britannica.com/science/nucleic-acid
https://www.thoughtco.com/nucleic-acids-373552
This post has been voted on by the SteemSTEM curation team and voting trail. It is elligible for support from @curie and @minnowbooster.
If you appreciate the work we are doing, then consider supporting our witness @stem.witness. Additional witness support to the curie witness would be appreciated as well.
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
Thanks for having used the steemstem.io app and included @steemstem in the list of beneficiaries of this post. This granted you a stronger support from SteemSTEM.