Wherein I ramble along, trying to think about putting genomes on blockchains
In @valth's recent article about the Earth BioGenome Project, one of the comment threads became a discussion about storing genome data on a blockchain. I popped my head in and mentioned without justification that that's probably a bad idea. I was invited to elaborate a little and in the process of writing my response, realized it was going to be long enough (yikes, ~2.5k words!) to become an article.
A little preamble
This is going to be a little different from my usual articles. First, it's not a gee-whiz-golly article about some cool microbial thing, don't worry there's going to be lots more of those. More importantly, I'm writing this as an essay in the earlier sense of the word where I'm using the writing process to organize and (maybe) reevaluate my own thoughts. The upshot of this is that I might be totally wrong here and that's ok. I'd like to hear lots of comments, agreement is always nice, but useful contradictory insights and views are even more welcome. Particularly if they reveal aspects I am unaware of or didn't consider properly. As such, I'm using my author's prerogative and specifically calling out to @simoxenham and @lemouth, both of whom have done a lot of thinking on the intersection of blockchains and science and whose opinions I would be very curious to read. Also, I intend to tag this with #steemstem because I'm pretty sure it's relevant, but if it's not, let me know and I can drop the tag.
Maslow's hammer and blockchains
Blockchains are cool, exciting, and useful tools. They are also very new, and we don't fully know what they can enable or what all their drawbacks are. Such a combination usually leads to the mindset described as Maslow's hammer: "I suppose it is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail." One way of avoiding that mindset is asking if applying the new shiny thing is a fundamental improvement. I intend to ask that question by describing what's involved in storing genomic data, looking at if it's even possible to store this data on a blockchain, determining if there's any value added, considering possible what the potential drawbacks are, and, hopefully, coming to some sort of conclusion.
Genomic datasets and you
I deal with genomic data a lot in my day job. Although I mainly work with a flavor a data that's got some important differences from the eukaryotic genomes in the Earth BioGenome Project (mainly bacterial and archaeal 16S surveys with a smattering of metagenomics and transcriptomics, for those interested) a lot of the issues in the context of data management are the same. Foremost, they are large - my latest dataset was in the dozens of gigabytes, and that's fairly unremarkable. Most of the data are text based (albeit often compressed) and have a lot of associated metadata.
Imagine thousands and thousands of lines, possible spread among hundreds of files, looking like this:
@SRR001666.1 071112_SLXA-EAS1_s_7:5:1:817:345 length=72
GGGTGATGGCCGCTGCCGATGGCGTCAAATCCCACCAAGTTACCCTTAACAACTTAAGGGTTTTCAAATAGA
+SRR001666.1 071112_SLXA-EAS1_s_7:5:1:817:345 length=72
IIIIIIIIIIIIIIIIIIIIIIIIIIIIII9IG9ICIIIIIIIIIIIIIIIIIIIIDIIIIIII>IIIIII/
@SRR001666.2 071112_SLXA-EAS1_s_7:5:1:801:338 length=72
GTTCAGGGATACGACGTTTGTATTTTAAGAATCTGAAGCAGAAGTCGATGATAATACGCGTCGTTTTATCAT
+SRR001666.2 071112_SLXA-EAS1_s_7:5:1:801:338 length=72
IIIIIIIIIIIIIIIIIIIIIIIIIIIIIIII6IBIIIIIIIIIIIIIIIIIIIIIIIGII>IIIII-I)8I
For researchers, it's important that the data are easily accessible, shareable, and uniquely identified. It's also a huge (and often unspoken) advantage if the data are in a standard format that's compatible with existing tools, especially the fragile BASH script that glued together a bunch of tools into a pipeline, which is kinda (not at all) documented and was written by a grad student who left 3 years ago and who nobody has any contact info for. It also helps if computers can easily talk to the data service so that people can do stuff related to multiple projects (metaresearch).
Let's take a little tour of how this is currently accessed online, be aware that a lot of this can be done over the command line and using local storage, too.
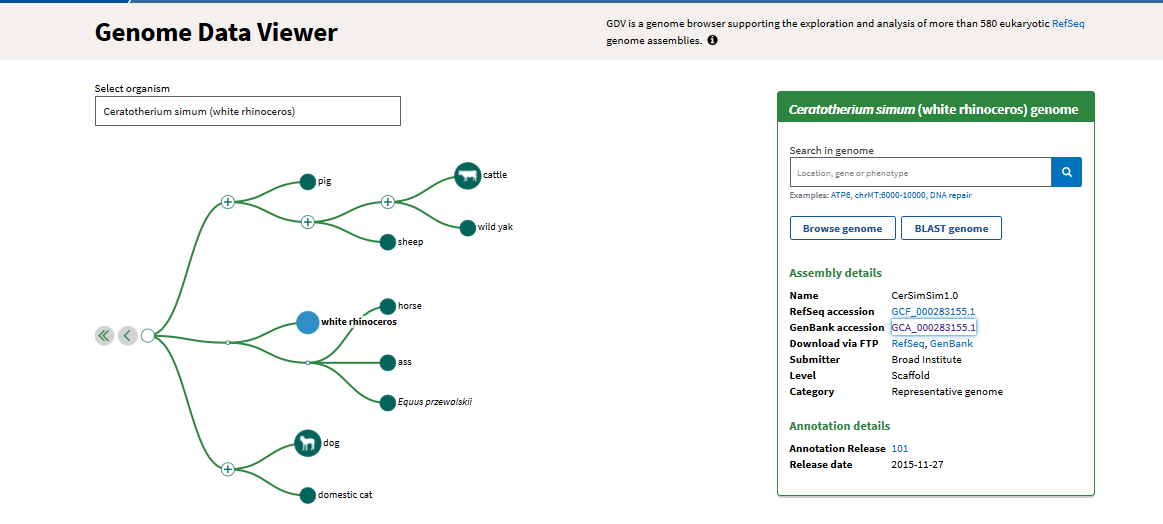

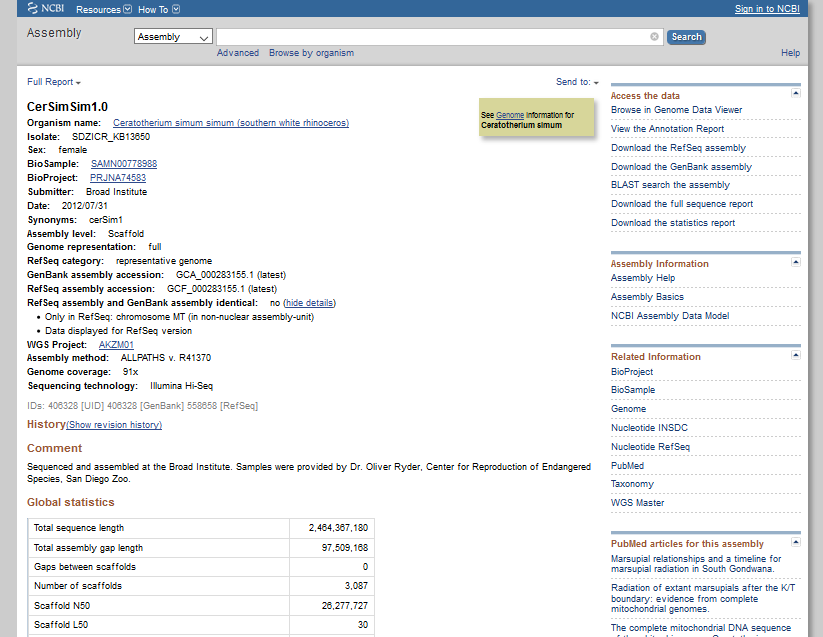
All of that is just one way to view one type of data. There's lots of other stuff, like epigenetic data, SNP frequencies, transcription, etc. Within bioinformatics there's a huge diversity of data, but the general flavor of the approach is more or less the same. I'm sure that astronomers, particle physicists, and many others have similar big data issues that are the same in essence, even if not in exact form.
Feasibility
The big issue for using a blockchain to store genomic data is its size. Blockchains, as initially developed, were designed to record information about transactions. To make an analogy, if you had a blockchain keeping track of automobile sales, it would probably record some very short pieces of data: identifiers of who bought and sold it, the vehicle's id, a price, date, and maybe some additional information about the car like mileage, previous major repairs, etc. There's no need to include the car itself (even if you could digitize it) in the blockchain. To extend this analogy to a digital object, imagine if someone decides that they miss the ability to buy and sell used games. You could write a very similar blockchain to transfer licenses but not have the game itself as part of the data.
When you do try to store large amounts of data on a traditional blockchain, stuff slows down to a crawl. We're actually pretty spoiled here with steem - the text content of our posts and comments are actually fairly large things to store on a block. How do you get around this limitation? There's two (and a half) approaches: reference based data storage (offchain), and true decentralized storage (onchain). Hybrid systems of these two are also an option. For example, the videos viewable on DTube are actually part of IPFS and referenced through the steem blockchain.
Reference based data storage
Reference based data storage is nice because it's simple to understand and you don't have to retrofit your blockchain technology to deal with it. Basically, one part of the transaction data points to (references) a (usually centralized) location for the data. These can be hard references, like a URL, or they can be even softer. A great example of really soft references is how (I think) Utopian.io deals with things. They reward work on open source projects, but the project repository itself is not (nor should it be) part of the blockchain. Basically, the soft reference is someone in text just mentioning where the github project is.
True decentralized storage
Storage through a distributed filesystem is more difficult. Basically, it incorporates a fundamentally changed blockchain (or sometimes peer to peer service, but not technically a blockchain) where peers share slices of their storage for rewards. There's a lot involved with this, including security, privacy, reliability, and, for many, concerns that they are unwittingly storing stuff they'd rather not support. You also generally don't want every member of the blockchain storing every file - it's hard enough to sync and host a basic wallet - it'd be pretty impossible to do it with large data. SO, there's an aspect of fine tuning how many peers host a file. None of these obstacles are insurmountable, in fact I know of a number of technologies (Sia, Storj, Filecoin, Maidsafe, Swarm, Phantasma , and IPFS) which are already doing just this or are planning to do so. I haven't gone into how these imnplementations work, because that's besides the point, but Smith and Crown has a decent overview. The one caveat to this is that it's important to know that distributed filesystems which do not use blockchain technology might not benefit from the advantages I list below.
Potentially added value
Just because something's possible, doesn't mean you should do it. Jurassic park and deep frying your shirt.
What would we gain by putting genome data on the blockchain?
Decentralization
Probably the biggest benefit that occurs to most people is decentralization. As you may have noticed, all of the genome links I posted earlier are hosted through major academic and government institutions. These are centralized data stores and thus a potential point of failure. While I feel it is highly unlikely that the NIH is just going to up and stop the NCBI server, it could happen. While it would be much more difficult, there is some precedent, as when the EPA started removing all climate change stuff from its servers. Although the academic community worked together to give the data a save haven, we shouldn't have to do that. And, though true, I don't mean 'shouldn't have to' as in 'it's shame we have a terrible electorate'. I mean 'our data should be safe regardless of the policies of whoever happens to be in charge'. A decentralized framework would prevent just such an occurrence.
Immutability & transparency
For these two, there's both a pragmatic and a (maybe) paranoid benefit. Pragmatically, immutability really helps researchers work on a specific, easily identified dataset. This makes your life as a local researcher better, but it's also very useful for comparing between projects and for creating reproducible research. Note that this doesn't mean you can't ever update the data, new versions would just be saved on the blockchain with a new identfier. In fact, I think blockchain based solutions might make versioning even easier than with current technologies. Similar mechanisms are used when we edit posts here. I've made many typos in my original articles, and if you dig through the blockchain you can still find them, fortunately the default blockchain viewers show the most recent version, kindly hiding my embarassing [sic] mistakes.
That is an example of transparency; everyone participating in the chain can see every addition to it and knows what user (or address, at least) is associated with every transaction. From a pragmatic standpoint, this really helps in tracking down errors, reproducing research, and even tracking the development of the research itself. While these are benefits we essentially get with the NIH databases, it's not guaranteed as part of the technology.
Now, for those of us who are a bit paranoid... immutability and transparency means that a centralized authority can't produce bogus data without us knowing who did it or remove all data in a coverup if they discover, as a totally random example, that a combination of genes associated with small hands and bad hair are also a sign of diminished mental capacity.
Cost?
Decentralized storage shines here, at least right now, it's much cheaper to store stuff on Storj vs centralized servers like S3 or dropbox. However, this may not be a huge benefit. The storage costs for projects like NCBI are just only one part of the budget. There's also the cost for the computing power to do things like BLAST searches and such. In our specific case, considering the overall cost of samples, sequencing, etc, storage is also probably not a huge percent of the budget.
Credit
One nice thing about blockchains is that they can distribute rewards. I personally think that it's a very bad idea to pay scientists directly for research output, having seen the quality of papers coming out from some institutions which give 'per paper' monetary rewards . However, credits don't have to be monetary - a trusted system for giving 'kudos' to research output might be a nice addition to the (already flawed) idea of H-indices and such. Regardless, it certainly doesn't hinder distributing genomic data and might be a bonus.
Better data interaction and roll your own blockchain?
I've found that established blockchains tend to be more extendable by their users than similar systems using a centralized counterpart. For an example, look at how the founders of Busy were unhappy with vanilla steem, so created a website which uses the exact same blockchain to try to enhance the user experience. There's also stuff like steemd, steemnow, and steemreports, which benefit from the inherent openness of a blockchain architecture.
From a science standpoint, a huge part of some researchers lives is just digging through literally 1000's of projects, and selecting those which meet certain criteria to do metaresearch. Imagine if similar open, non-proprietary extensions to centralized datasets and publications existed to make their lives easier. Beyonod all this, I have to imagine that the development of a blockchain technology which allows us to store all of the eukaryotic genomes on earth would also lead to spinoffs which would make it easier to share lots of other research data.
Pitfalls
The biggest pitfalls are largely due the newness of the technology.Largely due to the newness of the technology. Large instituations tend to be conservative with the technology choices and stick with the devil they know. Honestly, I can understand this mindset. It's rooted in the fact that new tech is in a 'growing phase' where we don't even know what we don't know about the drawbacks. It may, in fact, be the smart choice to hang back and see what we find out about things like speed, reliability, security, and longevity before a blockchain goes bellyup or effectively undergoes an extended denial of service attack because people are breeding virtual cats.
Wherein the author takes a cop-out conclusion
I have to eat a little crow. With a better understanding of newer onchain storage technology, I have to qualify that putting genomic data on most blockchains is a terrible idea. However, it is technically feasible with an appropriate architecture. Beyond that, there are lots of potentially beneficial gains from either being on a blockchain or having the data referenced by a blockchain. There are some pitfalls, but most of them are probably unknown and require some pilot projects.
Personally, I'm particularly drawn to the ability to roll my own and extend datasets, but that's because I have trouble imagining scenarios where the benefits of decentralization, immutability, and versioning are significantly better than what we do with current non-blockchain solutions. In the end, I would not recommend that the Earth BioGenome Project uses a blockchains, particularly onchain storage, at this time because the technology is still too volatile. However, I think that other, smaller, projects would be awesome testsbeds to help the technology mature - for example, a database of microscopy of environmental samples would be awesome. I predict that we'll first see onchain storage of data like that and a co-evolution of offchain storage complementing centralized datastores.
What do you think?
I've always been impressed by the accessibility of genomic data on NCBI so I'm inclined to agree that while putting genomic data on blockchains is feasible, it may not be a great idea.
Also, rewarding scientists for submitting genomic data with blockchain could be a slippery slope because it might encourage scientists to submit billions of raw reads without proper analysis/validation thereby drowning out the better data.
Yeah, I worry about it encouraging the equivalent of 'Hi. Great job. Please vote and follow me!'
Thanks for an interesting read, @effofex! You certainly went above and beyond when I asked why you thought it was a bad idea to store genomic data on the blockchain.
The reason why I originally wanted this type of data on the blockchain is because I have become a big fan of decentralizing a lot of things, and I believe science is one of the things who would do well on a blockchain where we can record who uploads what, can see all changes etc. It's great that NCBI is doing a great job with hosting the data at this time, but the fact that they removed info about global warming is really worrisome.
But I completely see your point in how it's not a good fit right now. I think we need to wait 10 years or so before we start seeing these types of applications from a blockchain, and by that time we will hopefully have much faster and better blockchains that are capable of letting us store huge amounts of data in a decentralized way.
I think it'll be sooner than 10 year for offchain things - stuff like paper commentary, adding metadata, curation, etc.
Let's hope so ;)
Hey, I just heard about 16 year old Ananya Chadha, who built an IPFS-hosted Ethereum app to store DNA info for CRISPR research. Young people don't write essays about what's possible, they go and build stuff.
Really neat! I need to read a little deeper to see how it's implemented, but that's impressive.
A nice string of thoughts with a hilarious example.
I would refrain from the idea that everything has to be decentralized. For some applications, decentralization has too many disadvantages.
If you would "blockchain" scientific results, then I'd go the referencing pathway. Storing the full data onchain is just overkill. You would also need to create benefits for running such storage-consuming nodes, which is another pitfall. Without "payment", it's not possible. With payment, you impair the scientific quality, just as you said.
I'm resteeming your post, as I hink this is an important discussion to be held for all of us "onchain" scientists.
Yeah, I'm leaning towards the offchain style and I think it'd be more useful for sharing stuff like annotations than raw data. Thanks for the resteem, I'm glad to have people to talk with this about. In my real world lab, blockchains are still just 'those bitcoins that people waste energy on with their computers.'
Great analysis, kudus for the honest conclusion. Edit: kudos - I can't afford to donate African antelope.
I'd prefer to put SciHub on the blockchain (or a similar platform like IPFS), so that everybody can read scientific research papers. Censorship resistance is what blockchains and decentralized networks do best. And since they're inefficient storage systems, it makes sense to store results rather than data.
Thanks and I agree. Papers are a whole different thing than data and are probably a much better thing to put on a blockchain - especially when you get into stuff like accessibility and such. If you haven't read them, you may want to check out @simoxenham's series of articles, which touch on that.
You just planted 0.43 tree(s)!
Thanks to @effofex
We have planted already 7267.14 trees
out of 1,000,000
Let's save and restore Abongphen Highland Forest
in Cameroonian village Kedjom-Keku!
Plant trees with @treeplanter and get paid for it!
My Steem Power = 22158.65
Thanks a lot!
@martin.mikes coordinator of @kedjom-keku
You just planted 0.43 tree(s)!
Thanks to @effofex
We have planted already 7321.34 trees
out of 1,000,000
Let's save and restore Abongphen Highland Forest
in Cameroonian village Kedjom-Keku!
Plant trees with @treeplanter and get paid for it!
My Steem Power = 22158.83
Thanks a lot!
@martin.mikes coordinator of @kedjom-keku
Congratulations! Your post has been selected as a daily Steemit truffle! It is listed on rank 3 of all contributions awarded today. You can find the TOP DAILY TRUFFLE PICKS HERE.
I upvoted your contribution because to my mind your post is at least 45 SBD worth and should receive 146 votes. It's now up to the lovely Steemit community to make this come true.
I am
TrufflePig, an Artificial Intelligence Bot that helps minnows and content curators using Machine Learning. If you are curious how I select content, you can find an explanation here!Have a nice day and sincerely yours,

TrufflePigI don't have much to say, to be honest. Data preservation is an important topic in many field, and ideas are being discussed, rejected, improved, etc. One important thing is having the data public. But another important thing os to have a way to access and manipulate them easily. For a given field, this should be standardized first before even mentioning the word blockchain.
Now, using blockchain for science? Well, I don't know. There are non-blockchain ideas all around the place, and I would first like to be convinced of the added value in using a blockchain. For the moment, I cannot foresee it, at least in physics.
Just one extra comment: replace monetary rewards by a reputation system. Much better for science. :)
Sorry for the shitty comment. :/
I'd hardly call it a shitty comment, and I hope I didn't make you feel put on the spot.
I think this is an important point which I didn't do a really good job of making clear. It's also one of the reasons why I'm more favorable towards offchain references than onchain stuff.
I mentioned it was shitty because I had just written down what was going through my mind without taking the time to organize it clearly. It was late at night ;)
But to sum up, both of us agree, I guess, on this one ^^
I was thinking this while I was reading the article. I wonder what this implies about financial rewards in general. I mean, if giving money to scientists per paper is bad, and appreciating their work without paying them is good, that's tantamount to communism or something! haha! ... I guess steemit tries to equate appreciation with monetary reward using the concept of the vote. .... Anyways, long discussion.
Yeah, any money is always good. However, in the context of scientific work, money is never the first incentive (one definitely does not get rich by working in academia...). So... :)
Thanks for this "insider" view and very comprehensive analysis.
This is true. I'm speaking from my own experience. In Serbia, publication in some shitty journal was worth 3 points. Some solid journal like PlosOne, Analytical Chemistry was 8 points and... Nature, Science ware valued with...? Also 8 points.
So the tactics for many research groups was to publish the unrefined BS. As much as possible.