♨️ SteemSQL: User guide accessible to everyone

SteemSQL is the database that gathers all the information related to Steemit: the characteristics of the accounts, the content of the articles posted, the different information related to the good functioning of steemit (upvote, reblog, ...) etc…
A database is a computerized tool that stores and organizes data in a structured way. Like an excel file, different tables are created and linked using unique identifiers, which allows you to obtain various data related to a particular element.
Many of the tools developed for the Steemit platform rely on the SteemSQL database.
A few examples of indispensable tools for understanding the steemit ecosystem :
How to use SteemSQL
In order to access the database, we need a software called (DataBase Management System - DBMS). There are many DBMS that offer the possibility of connecting to a database, I suggest you use SQL Server Management Studio (SSMS), edited by Microsoft, it is free and relatively easy to use.
Once the DBMS is launched, we will create a new connection to the SteemSQL database.
Click on the "New Connection" tab and enter the following information:
- Server name : sql.steemsql.com
- Login : steemit
- Password : steemit
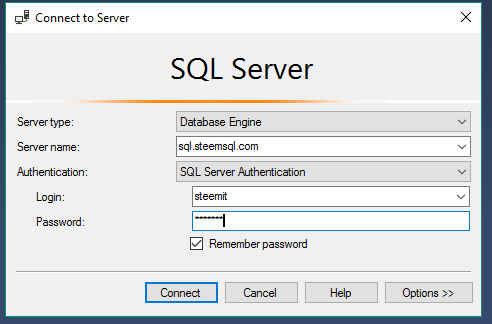
Then log in.
Tip ! If you don't see the SteemSQL database appear, open a new query and type "USE DBSteem" then' F5' or' Execute'.
We are now connected to the database.
How to retrieve SteemSQL information
Now we will launch requests on the server to retrieve different information, the language used is Transact SQL, a language developed by the company Sybase, it has become over time the main programming language for Microsoft tools.
IMPORTANT : If you want to do your tests, never forget to mention (NOLOCK) after the name of the tables, it is a question of performance, it is useless to block transactions to perform simple tests.
Query : Give me information about a user

Query : Give me the characteristics of the 20 most reputable accounts
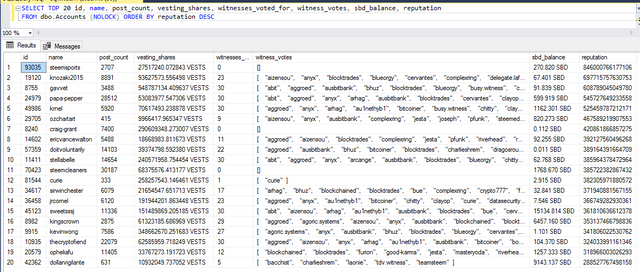
Analysis : I still don't have enough distance to analyze the results finely. But I notice that @curie and @ozchart is in the top 20 of reputations with very few articles, probably a question of quality. I also notice that @abit, @aggroed and @anyx are very popular witness, the reason must be justified.
If you wish to participate in a contest, it may be interesting to look for the contests that have the most visibility.
Query: Query: Show me the 20 articles that contain the word "contest" in their title, which were published less than 4 days ago and sort the results by number of votes.
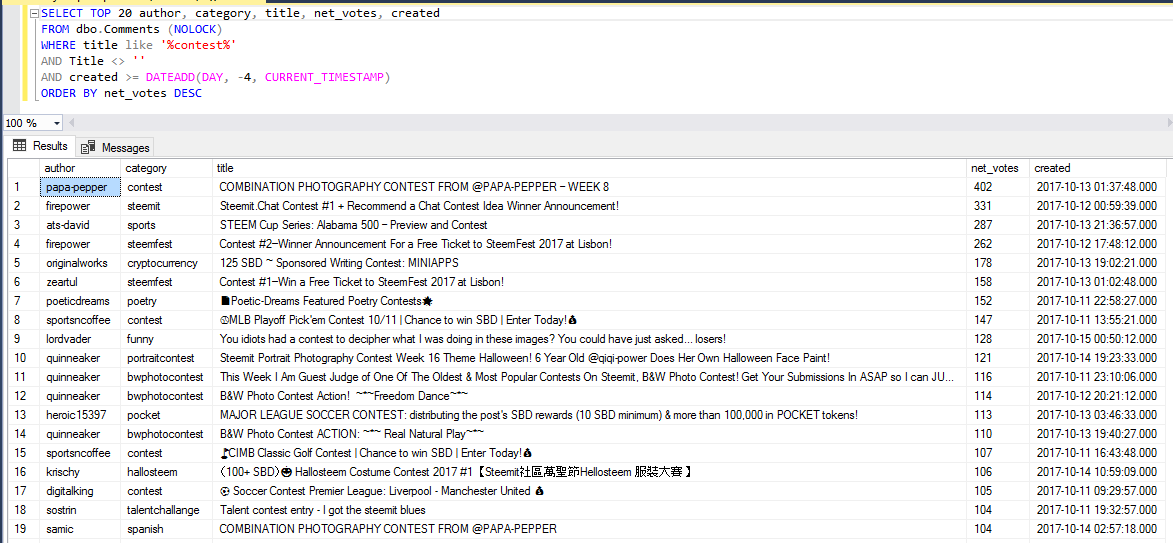
Analysis : The result is interesting, @originalworks organizes a contest at 125 SBD, @quinneaker and @papa-pepper are used to photo contests :) To follow.
These first examples are simple queries, all the power of relational databases lies in the possibility to make joins between several tables. Linked by unique identifiers, it is possible to retrieve a large amount of information using these links.
To talk about a subject that we are passionate about, there is nothing better than turning to quality authors who regularly address the subject.
Query : Show me the author's name, reputation, article title and url of articles with the word 'crypto-currency' in their title, which were published less than 7 days ago and sort the results by reputation.
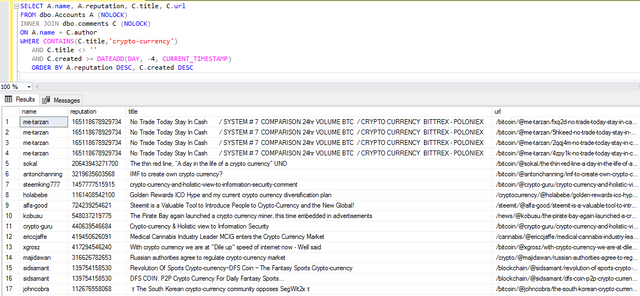
Analysis : I must confess that I am not very strong in crypto currency, in view of the results, I tell myself that if I want to exchange on the subject, I might as well talk about it with @me-tarzan or @sidsamant , they are probably aware of the latest news.
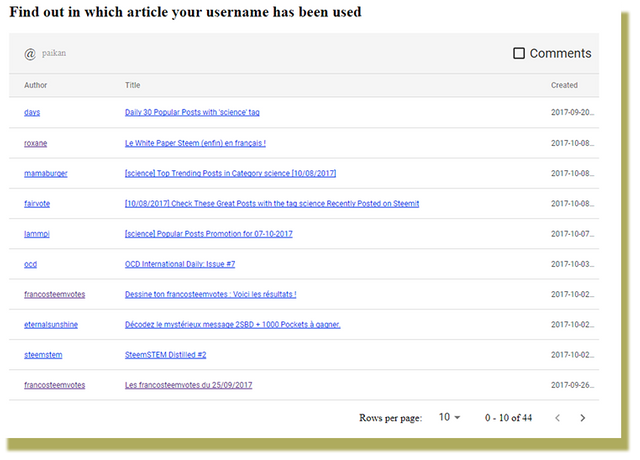
As I told you, everything is stored in the database, not only articles and users but comments as well. If your wish is to keep a visibility on your presence, you can ask the base to display all comments or your nickname appears.
Query : Show me, the author of the commentary, the title of the parent article and the body of the message of all comments that contain my nickname.
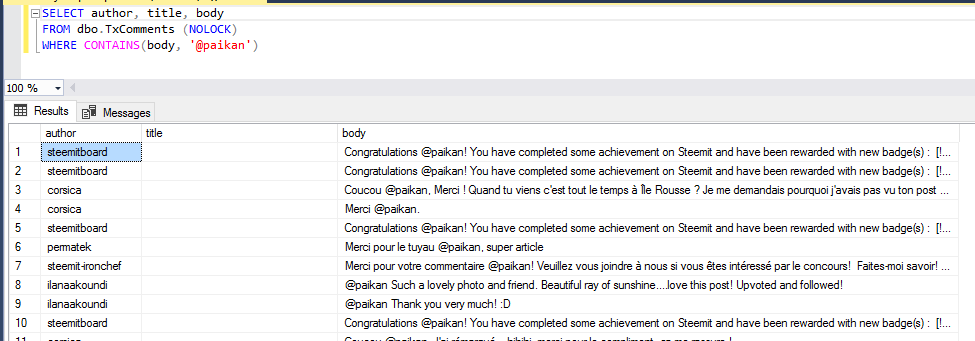
Database tables
I didn't take the time to search and browse all the tables. To realize this article I relied on an existing schema, realized by @arcange and present in his article :
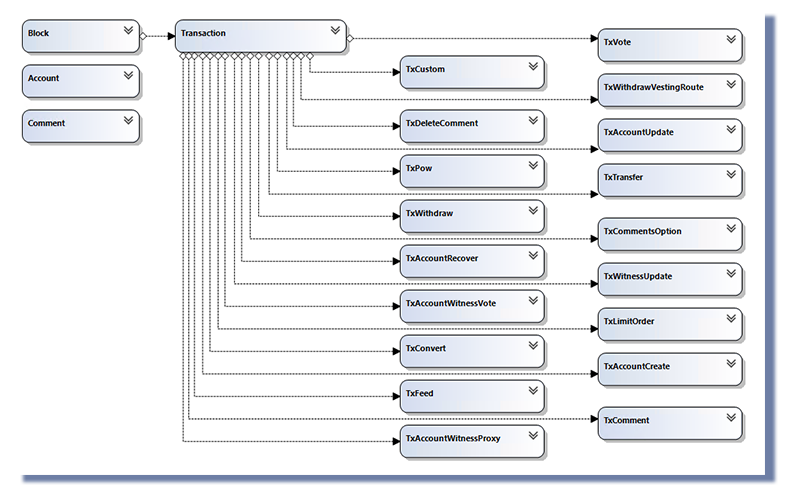
The purpose of this article is to present the principles of database access. My queries are extremely simple but it is possible to make queries and procedures extremely powerful. Don't forget that a very large part of Steemit's operation is based on the database that stores the data.
I also take this opportunity to thank @arcange for the work it does on the SteemSQL base, for its optimizations or its development that allows us all to access Steemit with very acceptable response times :)
I remind you that you can vote for him as Witness and do not hesitate to join the chat steemsql for any technical questions.
I love sql i will try in the future
Thank you best regard @galberto
Thank you for your comment, you will see, the sql is very interesting:)
Thx ! I'll check steemsql soon.
Upvoted and resteemed !
Merci beaucoup pour ton soutien ;)
Thanks for information
Found this article by luck about #steemsql
thank You, upvoted
hey, this is still working?