차원 축소 기법을 통한 빅데이터 시각화

기술의 발전으로 빅데이터를 묶고 있던 차원의 저주가 풀리고 있긴 하지만 아직 완전하게 풀린 건 아니다. 현 수준의 하드웨어나 소프트웨어 속도로는 차원의 저주로 발생된 엄청난 양의 데이터를 처리하지 못할 가능성이 높기 떄문에 차원의 저주로 인해 늘어나는 케이스의 수를 가급적 줄여야 한다.
케이스의 수를 줄이려면 분석변수나 각 분석변수의 해상도를 결정하는 구간의 수를 줄여야 한다.
대부분의 기업은 분석변수나 구간의 수를 정하기 위해 회귀분석처럼 분석에 시간이 적게 걸리고 분석된 결과의 의미를 알려주는 알고리즘에 의존하는 경향이 높다. 하지만 모든 문제를 해결할 수 있는 한 가지 알고리즘은 아직까지 존재하지 않기 때문에 회귀분석은 적합한 경우에만 사용해야 제대로 된 결과를 얻을 수 있다.
딥러닝의 학습 속도가 빨라졌다고 해도 데이터의 양이 많아지면 속도가 느려질 수밖에 없다.
그렇다면 머신러닝이나 인공지능 알고리즘을 사용하지 않고 분석변수나 구간의 수를 결정할 수 있게 고차원의 빅데이터를 인간이 이해할 수 있는 2~3차원으로 시각화하는 방법이 필요하다. 차원의 저주를 해결할 수 있게 도와주는 데이터의 시각화, 바로 '차원 축소 기법'이 그것이다.
인간은 데이터가 3차원이나 2차원으로 표현될 때 효과적으로 인식할 수 있다. 기업 내 빅데이터가 지구본 모양의 3차원 형태 혹은 지도 형태의 2차원 형태처럼 분석가 눈앞에 펼쳐져 있다고 상상해보자. 해당 업무를 수행해보지 않은 분석가도 어떤 데이터들을 분석변수로 할 것인지, 구간은 몇 개로 나누는 것이 좋은지 등에 대한 아이디어를 금방 얻을 수 있을 것이다. 물론 데이터 시각화는 기존에 알려진 것처럼 분석 결과를 그래프로 그리거나 지도 위에 분석 결과를 겹쳐 보이게 하는 등의 결과 데이터 시각화도 의미하지만, 빅데이터 분석 과정에서 말하는 데이터 시각화는 업무에 전문적인 지식이 없는 분석가라도 고차원의 빅데이터를 2~3차원으로 펼쳐서 머신러닝 알고리즘 학습에 중요한 분석 변수들을 찾을 수 있게 해주는 분석 데이터 시각화를 의미한다.
머신러닝 등 데이터 분석을 전문으로 하는 연구자들 사이에서는 데이터 시각화를 통해 선정된 중요한 변수를 특징변수Feature 라고 부른다. 특징변수는 하나의 인물, 단어, 사실, 혹은 사물 등을 다른 것과 구별할 수 있는 공통적인 방법이다.
쉽게 설명하면 사람의 지문 같은 것이다. 지문을 들여다보면 지문의 선을 구성하는 융선이있다. 이 융선은 연속적으로 이어져 있는 것이 아니라 시작점, 끝점, 분기점이 있고 선이 세 방향으로 나뉘는 삼각주가 있다. 이것들의 위치가 사람마다 다르기 때문에 지문은 특정인을 인지하는 특징이 될 수 있다. 지문을 여러 블록으로 구분하여 삼각주나 융선의 시작점 등의 위치를 찾아내면 보다 빨리 지문을 인식할 수 있는 것처럼 특징변수를 분석에 사용하면 분석 속도와 정확성을 높일 수 있다.
특징변수를 선정하는 방식에 따라 특징 변수 선택과 추출, 두 가 기법이 있다. 특징변수 선택 Feature Selection은 기존 분석변수 중에서 학습에 중요한 정보를 포함하고 있는 분석변수를 찾아내는 것이다.

반면에 특징변수 추출Feature Extraction은 기존 분석변수들을 결합하여 완전히 새로운 변수를 만드는 것이다.
두 가지 기법 모두 분석변수들을 평가하여 우수한 분석 변수를 찾아낼 수 있 있는 평가 기준과 분석 변수의 모든 조합을 조사할 수 있지만, 속도가 매우 느린 '완전 탐색Exhaustive Search'을 대신할 수 있는 효율적인 최적화 알고리즘을 필요로 한다.
먼저, 특징 변수 선택기법은 두 가지로 분류된다. 특징변수 평가기준에 머신러닝 알고리즘을 사용하지 않으면 개루프Open-loop 기법,
사용하면 폐루프 Closed-loop 기법으로 구분하다. 여기서 루프란, 일련의 연산 과정을 의미한다.
폐루프는 제대로 된 결과가 나올 때까지 연산을 반복한다는 의미고, 개루프는 연산을 처음부터 끝까지 한번만 수행하면 끝난다는 의미다.
당연히 폐루프 기법이 분석에 유의미한 특징변수를 찾아낼 가능성이 높지만 속도가 느리다. 개루프 기법은 반대다. 결국 두 기법은 서로 상충 관계에 있게 된다. 분산, 병렬 처리를 통해 폐루프 기법의 속도를 개선할 수는 있지만 분산, 병렬 처리에 맞게 수정된 알고리즘은 오픈소스 소프트웨어에 공개되어 있지 않아 자체적으로 개발해야 하는 부담이 있다.
개루프에도 많은 기법이 존재한다. 기법 간 차이점이 있어 분석 변수를 평가하는 기법에 따라 결과에 많은 차이가 발생할 수 있기 때문에 한 가지보다는 여러 개의 기법을 함께 사용하는 게 좋다. 또 특징변수 선택기법으로 특징변수를 선정하기 전에 데이터 시각화를 사용하여 변별력이 높은 변수들이 선택되었는지 반드시 확인해야 한다.
특징 변수 추출기법도 상당히 많은 연구가 이뤄져 다양한 알고리즘이 존재한다.
심지어 인공신경망을 특징변수 추출 알고리즘으로 변형해서 사용할 수 있다. 여러 가지 알고리즘 중에서 많이 사용되는 주성분분석PCA, 선형판별분석LDA, 서포트 벡터 머신SVM, 세 가지만 간략히 살며본다.

주성분분석은 분석변수들을 선형적으로 결합하여 데이터를 가장 잘 표현할 수 있는 축을 찾아내고, 그 축을 중심으로 데이터를 차원 축소해서 표현해주는 기법이다. 서로 목표값이 다른 군집으로 분류해야 하는 경우에도 전체 데이터를 하나로 보고 차원을 축소하기 때문에 데이터를 분류하거나 패턴을 찾으려면 주성분분석을 활용하면 안 된다.
선형판별분석은 주성분분석의 단점을 개선하여 분석 데이터가 서로 다른 군집으로 구성되어 있을 때 군집을 최대한 잘 구분할 수 있는 축을 찾는다. 그 축을 중심으로 데이터를 2차원이나 3차원으로 축소해서 서로 다른 군집을 얼마나 분류할 수 있는지 사람이 알아볼 수 있게 표현해준다. 하지만 분류될 군집의 수가 적은데 분석 데이터 세트의 가로축인 분석차원이 너무 많거나 세로축인 수집한케이스 데이터의 양이 많은 경우 오류가 발생한 위험이 높으므로 주의해야 한다.
딥러닝 알고리즘이 소개되기 전까지는 서포트 벡터 머신이 분류 알고리즘으로 많이 활용되었다.
기업 내 분석가들도 데이터 차원 축소 기법과 이를 시각화 할 수 있는 알고리즘이 내장되어 분석 결과를 인간이 이해할 수 있는 형태로 제공해줄 수 있는 서포트 벡터 머신에 많은 관심을가졌다.

서포트 벡터 머신은 가로축의 분석차원이 30개라도 내부에 있는 차원 축소 기법을 활용하여 2차원이나 3차원으로 축소시킨 후 분석 결과를 그래프로 제공한다.
분석가는 결과 그래프를 보고 분류가 잘 되었는지의 여부를 직관적으로 파악할 수 있다. 이런 장점 때문에 서포트 벡터 머신은 특징변수 추출 알고리즘으로도 많이 활용된다. 서포트 벡터 머신에 내장된 차원축소 기법은 앞에서 설명한 두 가지 기법 대비 변수 간 비선형 관계가 있는 경우에도 사용할 수 있다는 장점이 있다.
고차원의 분석 변수 간에 선형 관계가 있는지 , 비선형 관계가 있는지는 데이터 시각화로도 찾아내기 어렵다. 데이터 시각화에 익숙지 않은 경우 주성분분석이나 선형판별분석 중 하나와 서포트 벡터 머신의 결과를 비교하면서, 두 결과를 데이터 시각화와 비교하며 경험을 축적한다면 분석 변수 간의 관계를 찾아낼 수 있는 실력을 기를 수 있다.
특징변수 추출 알고리즘을 사용하기 전에 반드시 체크해야 할 사항이 있다. 각 분석변수들의 독립성이다. 예를 들면 제조업에서 사용하는 무게, 길이 같은 분석변수는 대부분 독립적인 분석변수들이다. 하지만 마케팅에서는 기존에 축적된 분석변수 간에 독립성 여부를 판단하는 것이 쉽지 않다. 두 변수의 상관성이 높다고 단순히 구 변수가 독립적이이지 않다고 판단할 수 없기 때문이다. 몸무게와 키는 서로 독립적인 변수지만 키가 큰 사람은 몸무게도 많이 나갈 수 있기 때문에 두 변수의 상관성은 매우 높게 나온다. 분석변수 간의 독립성을 정확하게 판단하는 알고리즘은 아직 오픈소스로 공개되지 않았기 때문에 자체 개발할 필요가 있다.
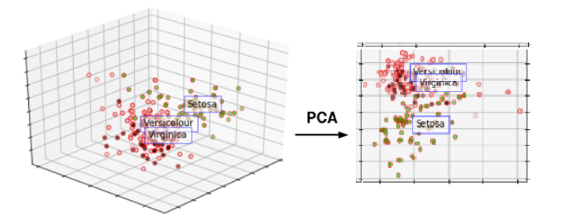
데이터 시각화, 곧 차원 축소 기법을 특징변수 추출기법과 선택기법에서 어떻게 활용할 수 있는 아이리스 꽃 분류를 예로 들어 설명해본다. 아이리스 플라워 데이터 Iris flower data 혹은 피셔의 아이리스 데이터 Fisher's Iris data 라고 불리는 붓꽃 데이터는 1936년 로널드 피셔 Ronald Fisher가 데이터를 활용한 식물 분류 가능성을 연구하기 위해 수집한 데이터다. 로널드 피셔는 데이터 품질로 인한 오차를 줄이기 위해 캐나다 동남부의 가스페 반도에 있는 동일한 목초지에서 붓꽃의 세 가지 종인 세토사Setosa, 버지니카Virginica, 버시컬러Versicokor를 하루 동안 50개씩 수집했다. 이렇게 수집한 총 150개의 붓꽃을 동일한 사람이 동일한 측정 기구로 꽃잎과 꽃받침의 길이와 너비를 측정했다.
특징변수 선택기법은, 꽃잎과 꽃받침 각각의 너비와 길이, 이렇게 4개의 분석변수가 있으므로 분석변수의 가능한 모든 조합인 16개 조합에 대해 세 종류 꽃이 어떻게 분포되는지를 그림처럼 시각화한다. 이 중 동일 분석변수끼리 비교한 대각선의 4개 그래프를 제외하고 총 12개의 그래프를 분석하게 된다.

12개의 분포도를 보면 세토사를 제외한 나머지 2개 종 데이터가 중첩된다는 것을 알 수 있다. 실제 업무에서 발생하는 대부분의 데이터를 비즈니스적 의미가 있는 방식으로 시각화하면 이처럼 데티어가 중첩되어 보이는 경우가 종종 발생한다. 분석가들은 버시컬러와 버지니카를 정확하게 분류할 수 없다는 결론을 내릴 것이다. 붓꽃 분류 문제는 다행히 분석차원이 4개라 시각화로 어느 정도 분석낼 수 있지만 분석변수의 수가 100개라면 100*100=10,000이 되므로 총 1만 개의 그래프에서 동일 분석 변수끼리 비교한 대각선 100개를 뺀 9,900개의 그래프가 생긴다. 전체적인 공간 지각 능력을 가진 사람이라도 한계에 봉착할 것이다.
특징변수 선택기법은 위 4개의 분석변수 중 가장 변별력이 뛰어난 분석변수를 선택하는 것이다. 만약 그림 우측처럼 3차원 그래프로 시각화하고자 한다면 4개의 변수 중에서 변별력이 높은 3개의 변수를 선택하면 된다. 특징변수 추출기법으로 군집분석 알고리즘인 K 군집K-means Clustering 알고리즘을 활용해서 데이터를 4차원에서 3차원으로 축소한 후 분포도를 그리면 그림 좌측과 같은 그래프가 된다.
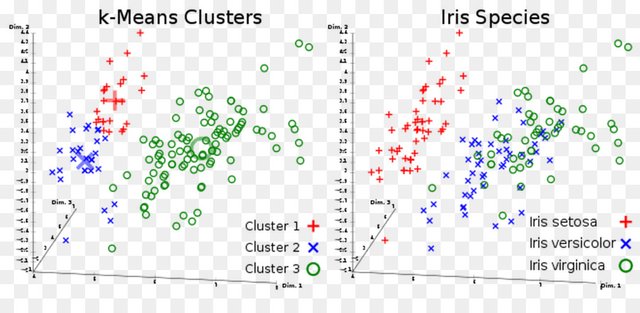
좌측의 특징변수 추출기법과 우측의 특징변수 선택기법을 비교해 보면 우측 그래프에서는 여전히 버시컬러와 버시니카의 데이터가 많이 중첩되어 있지만 좌측 그래프에서는 세 종류의 데이터가 상당 부분 정확하게 분류된 것을 볼 수 있다.
그림에서처럼 특징변수 추출기법이 특징변수 선택기법보다 정확한 분석 결과를 제공한다. 그렇기 때문에 속도가 빠른 고성능의 컴퓨팅 자원을 요구하는 단점에도 불구하고 특징변수 추축기법이 많이 활용될 것 같지만, 현실은 그렇지 않다. 특징 변수 추출기법은 세 종류의 꽃을 제대로 분류하긴 했지만 각 분석변수가 결합되며 그 의미가 흐려지기 떄문에 물리적으로 뭘 의미하는지 모르게되기 때문이다.
다행히도 특징변수 추출기법의 이런 단점을 극복하기 위한 많은 시도가 이뤄지며 실제 업무에서 의미를 가지면서도 선명한 특징변수를 추출하는 알고리즘들이 다양하게 개발되고 있다. 앞에서 예로든 디젤엔진의 흡기와 배기밸브의 압력을 각각 입구 압력 핀Pin과 출구 압력 파우크Pout라고 하면, 2개의 분석 변수를 Z=(Pout-Pin)/Pin과 같이 결합하여 Z라는 기존 2개의 변수와는 비선형 관계를 갖는 새로운 특징변수를 만들 수 있고, 그 의미는 압력 증가율이 된다. 비즈니스의 의미를 잃지 않는 특징변수 추출과 관련된 많은 연구들이 이미 이뤄진 만큼 조금 관심을 가지고 찾아보길 바란다.
실제로 비즈니스 의미를 갖는 특징변수를 찾은 사례를 보면 어렵지 않다는 것을 알수 있따. 대부분의 카드사는 현금서비스나 카드론과 같은 신용대출상품을 판매하는데 각 고객별로 이자, 대출한도 등을 차별화하여 제공한다. 고객별 차등 적용이 가능한 이유는 일정 기간 카드를 사용한 이력이 있는 고객에게만 신용대출상품을 제공하기 때문이다. 신용카드 사용 이력 분석을 통해 발굴한 고객들의 소비성향 등 추가적인 정보와 신용정보사에서 제공하는 신용 등급을 결합하면 신용대출에 따른 리스크를 고객별로 보다 정교하게 산정할 수 있다. 따라서 금융회사의 신용대출 서비스를 이용하려면 적어도 2~3개월 정도는 카드사의 상품을 이용해야 한다. 물론 이용을 하지 않아도 신용대출상품을 제공하는 카드사도 있지만, 이런 경우 신용정보사에서 제공하는 신용등급에 따른 최고 이자와 최소한도를 적용받을 가능성이 높다.
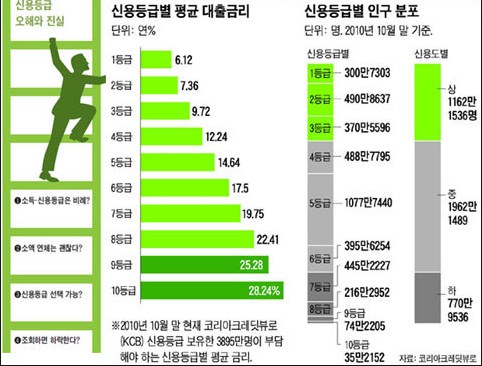
대출상품은 카드사 외에 은행, 보험사, 증권사, 저축은행 등도 취급이 가능하다. 이런 곳은 대출상품을 이용하는 고객이 매우 한정적이기 때문에 낮은 신용등급이 부여된 고객들 중 우량고객을 확보하고 싶어한다. 그래서 많은 금융기업들이 중간 정도의 신용등급을 가진 고객들을 대상으로 하는 중금리대출 시장에 진입해 치열하게 경쟁하고 있다. 카드사들도 동일한 신용등급을 가진 수많은 고객들 중에서 우량고객을 선별할 수 있다면 자사 상품을 이용한 적이 없는 고객에게도 대출상품 판매가 가능하다.
하지만 카드 이용 실적이 없는 고객의 신용 리스크를 분석할 수 있는 데이터는 기업 내에 없기 때문에 기업 외부에서 찾아야 한다.
모든 고객을 평가할 수 있는 데이터를 찾기는 어렵지만 개인 사업을 하느 고객의 경우 이미 글로벌에서 화제가 되어 국내에도 유명한 핀테크 생겨날 정도로 언론을 통해 많이 소개되었던 P2P 대출 서비스의 신용 리스크 평가와 아주 유사하기 때문에 신용 리스크 산출에 필요한 분석 변수를 찾을 수 있다.
P2P 대출은 금융기관을 거치지 않고 온라인 플랫폼에서 개인 간에 필요한 자금을 지원하고 대출하는 서비스다. 미국 최대 P2P대출 기업인 렌딩클럽Lending Club은 2014년 뉴욕증시 상장 당시 약 10조 5,700억 원의 시가총액을 달성한 적도 있다. 미국 내 P2P 대출 기업들의 부도율 증가로 평균 수익률이 낮아지면서 지금은 투자자들의 관심도 줄었지만, P2P 대출 기업들은 한 번도 거래를 하지 않았던 개인 사업자들의 신용 리스크를 간접적으로 평가할 수 있는 여러지표를 만들어 실제 업무에서 사용하고 있다.
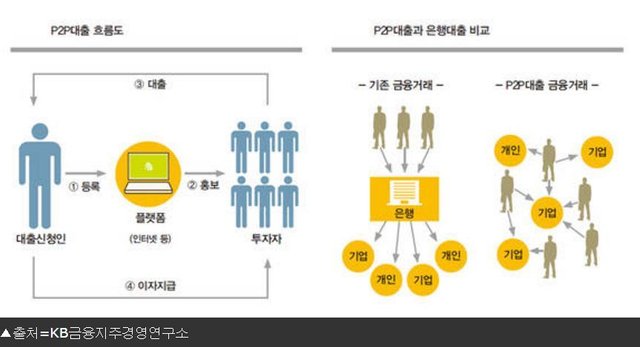
글로벌 P2P 대출 업체들이 자신들의 신용평가 역량을 과시하기 위해 언론에 홍보했던 내용 중 기억에 남는 지표는 상권밀집도이다.
상권밀집도 평가는 신용평가를 해야 되는 개인사업장 주변 특정 거리 안에 개인 사업장들이 얼마나 있는지를 보는 것이다.
물론 특정 거리가 몇 미터인지 몇 킬로미터인지 정확한 설명도 없고 개인 사업장이 동일 업종인지 혹은 유사 업종인지 아니면 전체 업종인지 알 수 없다. 결국 실제 업무에 적용할 때는 사업장 주변 거리와 업종의 유사성에 대한 다양한 조합을 만들어 실제 적용해볼 수 밖에 없다.
카드 사용 이력이 존재하고 기존 신용대출상품을 이용한 개인 사업자를 대상으로 테스트해본 결과 상당히 영향력 있는 조합을 찾을 수 있었다.
상권밀집도를 평가하기 위해서는 외부에서 판매하는 사업장 간에 거리를 측정할 수 있는 주소 좌표 데이터가 필요하다.

구매한 주소 좌표 데이터를 기업 내에 있던 개인 사업자의 매장 주소에 결합하면 상권밀집도 산출이 가능하다.
실제 사례에서처럼 비즈니스에서 의미가 있는 특징변수를 창의적으로 만들어내기 어렵다면 외부 사례를 찾아보는 것도 하나의 방법이다.
그러다 보면 특징변수를 만들어내기 위해 필요한 외부 데이터가 무엇인지 알 수 있다.
글로벌P2P 기업들이 얼마나 창의력을 가지고 지표들을 발굴했는지, 그 지표들이 얼마나 많은 시행착오를 겪어 얻어낸 결과인지도 알 수 있다.
데이터 시각화, 측 차원 축소 기법을 활용하여 기업 내부에 있는 데이터 중 중요한 특징변수들을 선정하거나 추출하는 것도 중요하지만, 확보 가능한 외부데이터가 있는지 찾아보는 것도 중요하다.
외부 데이터를 찾으려면 글로벌 기업들, 특히 스타트업 기업들이 어떤 변수들을 찾아내어 활용하는지 동향을 살펴보는 것이 중요하다.
그런 변수들을 찾아내어 활용하는지 동향을 살펴보는 것이 중요하다. 그런 변수들은 의외로 비즈니스 의미를 갖고 있는 경우가 많기 때문에 변수들을 자체적으로 개발하는 것보다 벤치마킹을 통해 카피를 해보는 것도 좋은 전략이 될 수 있다.
새로운 기회와 수익을 만드는 빅데이터 사용법
-돈이 보이는 빅데이터, 이종석-
Posted from my blog with SteemPress : http://internetplus.co.kr/wp/?p=516