System Design: Design scalable typeahead component

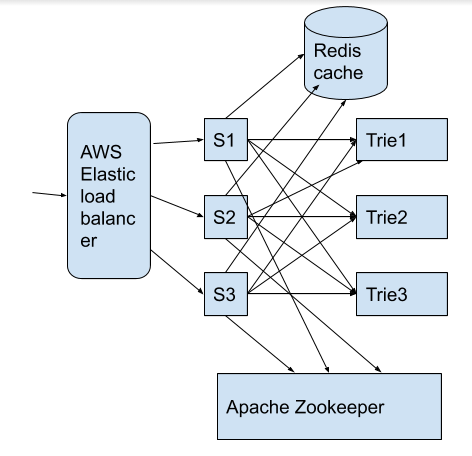
Explanation
- Since , our data is massively large, we will keep it distributed on multiple servers named S1, S2, S3, and so on (which can be AWS EC2 instances) as seen above. Behind these servers we will be using an AWS elastic load balancer to handle and bifurcate client request loads to different servers based on their availability which the elastic load balancer is adept at doing.
- The data structure used for returning matching words by key is called Trie. There are multiple instances of Trie info retrieval system and their config will be stored by apache zookeeper.
- Apache zookeeper which will store configuration info and will return will return different instances of the Trie data structure based on the queries from the server instances S1, S2, S3.
- Redis caching system will be used and the servers will first query the caching engine. If there is a cache miss, the request is redirected to zookeeper which has all the info on who stores the trie data structure. It will return that info to the server instance querying the data.
- This info returned by the zookeeper will be stored in the redis cache and the next subsequent queries to redis will result in cache hit thereby improving the performance.
Data structure and data storage/retrieval explanation.
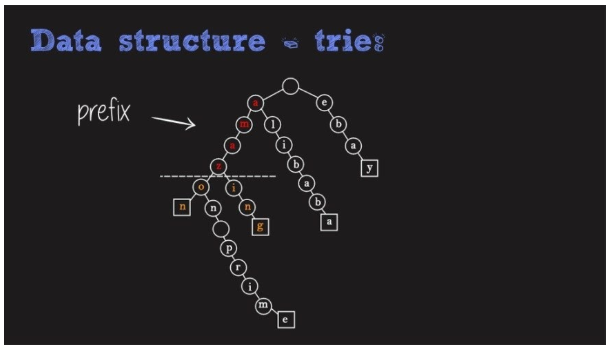
As seen in the above diagram, a Trie is a tree like data structure where different characters are stored in the tree node. Multiple words starting with the same character will all be the children of that particular node. Thus this tree will be an N-ary tree.
Algorithm:-
A trie tree node will look like below:
Source taken from wikipedia. It will have a maximum of 26 children and isEndOfWord acts like a pointer to the next children and will be False or NULL for the last child of the node.
For the sake of simplicity as this is a standard algorithm, I am taking this info from wikipedia for insert and find a node in the trie tree.
Note that children is a dictionary of characters to a node’s children; and it is said that a “terminal” node is one which represents a complete string.
A trie’s value can be looked up as follows:
def find(node: Node, key: str) -> Any:
for char in key:
if char in node.children:
node = node.children[char]
else:
return None
return node.value
Insertion proceeds by walking the trie according to the string to be inserted, then appending new nodes for the suffix of the string that is not contained in the trie:
Performance:- Insert and search in this tree costs O(key_length), however the memory requirements of Trie is O(ALPHABET_SIZE * key_length * N) where N is the number of keys in Trie.
Infrastructure:- Apache Zookeeper, AWS EC2 instances, Redis open source in memory data and caching software.
Scaling:- Let’s say with time our data grows and it can’t be fit in one trie node. So we will split the data into multiple nodes and Zookeeper entry will look like:
- Character 1 – character k – Trie1, Trie2, Trie3
- Character k+1 – character t – Trie4, Trie5, Trie6
- Character t+1 – character n – Trie7, Trie8, Trie9 and so on…
We can also replicate this data across multiple EC2 instances spanned across the same or different availability zones for improving the data availability, and up time. We can employ AWS Route 53 for serving data based on edge locations as the data keeps growing. This will ensure a high degree of scalability, availability and durability.
Based on search trends, we will keep updating the database and assign weights to different search queries like google and will flash the most highly searched queries on top in the suggestions followed by those with lower weights. A background job will keep running every hour and flush data in the DB based on these top search trends.
Posted from my blog with SteemPress : https://www.golibrary.co/system-design-design-scalable-typeahead-component/