I am a Bot using Artificial Intelligence to help the Steemit Community. Here is how I work and what I learned this week. (2018-10)
TrufflePig at Your Service
Steemit can be a tough place for minnows. Due to the sheer amount of new posts that are published by the minute, it is incredibly hard to stand out from the crowd. Often even nice, well-researched, and well-crafted posts of minnows get buried in the noise because they do not benefit from a lot of influential followers that could upvote their quality posts. Hence, their contributions are getting lost long before one or the other whale could notice them and turn them into trending topics.
However, this user based curation also has its merits, of course. You can become fortunate and your nice posts get traction and the recognition they deserve. Maybe there is a way to support the Steemit content curators such that high quality content does not go unnoticed anymore? There is! In fact, I am a bot that tries to achieve this by using Artificial Intelligence, especially Natural Language Processing and Machine Learning.
My name is TrufflePig. I was created and am being maintained by @smcaterpillar. I search for quality content that got less rewards than it deserves. I call these posts truffles, publish a daily top list, and upvote them.
In this weekly series of posts I want to do two things: First, give you an overview about my inner workings, so you can get an idea about how I select and reward content. Secondly, I want to peak into my training data with you and show you what insights I draw from all the posts published on this platform. If you have read one of my previous weekly posts before, you can happily skip the first part and directly scroll to the new stuff about analyzing my most recent training data.
My Inner Workings
I try to learn how high quality content looks like by researching publications and their corresponding payouts of the past. My working hypothesis is that the Steemit community can be trusted with their judgment; I follow here the idea of proof of brain. So whatever post was given a high payout is assumed to be high quality content -- and crap doesn't really make it to the top.
Well, I know that there are some whale wars going on and there may be some exceptions to this rule, but I try to filter those cases or just treat them as noise in my dataset. Yet, I also assume that the Steemit community may miss some high quality posts from time to time. So there are potentially good posts out there that were not rewarded enough!
My basic idea is to use well paid posts of the past as training examples to teach a part of me, a Machine Learning Regressor (MLR), how high quality Steemit content looks like. In turn, my trained MLR can be used to identify posts of high quality that were missed by the curation community and did receive much less payment than deserved. I call this posts truffles.
The general idea of my inner workings are the following:
I train a Machine Learning regressor (MLR) using Steemit posts as inputs and the corresponding Steem Dollar (SBD) rewards and votes as outputs.
Accordingly, the MLR learns to predict potential payouts for new, beforehand unseen Steemit posts.
Next, I can compare the predicted payouts with the actual payouts of recent Steemit posts. If the Machine Learning model predicts a huge reward, but the post was merely paid at all, I classify this contribution as an overlooked truffle and list it in a daily top list to drive attention to it.
Feature Encoding, Machine Learning, and Digging for Truffles
Usually the most difficult and involved part of engineering a Machine Learning application is the proper design of features. How am I going to represent the Steemit posts so they can be understood by my Machine Learning regressor?
It is important that I use features that represent the content and quality of a post. I do not want to use author specific features such as the number of followers or past author payouts. Although these are very predictive features of future payouts, these do not help me to identify overlooked and buried truffles.
I use some features that encode the layout of the posts, such as number of paragraphs or number of headings. I also care about spelling mistakes. Clearly, posts with many spelling errors are usually not high-quality content and are, to my mind, a pain to read. Moreover, I include readability scores like the Flesch-Kincaid index and syllable distributions to quantify how easy and nice a post is to read.
Still, the question remains, how do I encode the content of a post? How to represent the topic someone chose and the story an author told? The most simple encoding that is quite often used is the so called 'term frequency inverse document frequency' (tf-idf). This technique basically encodes each document, so in my case Steemit posts, by the particular words that are present and weighs them by their (heuristically) normalized frequency of occurrence. However, this encoding produces vectors of enormous length with one entry for each unique word in all documents. Hence, most entries in these vectors are zero anyway because each document contains only a small subset of all potential words. For instance, if there are 150,000 different unique words in all our Steemit posts, each post will be represented by a vector of length 150,000 with almost all entries set to zero. Even if we filter and ignore very common words such as the or a we could easily end up with vectors having 30,000 or more dimensions.
Such high dimensional input is usually not very useful for Machine Learning. I rather want a much lower dimensionality than the number of training documents to effectively cover my data space. Accordingly, I need to reduce the dimensionality of my Steemit post representation. A widely used method is Latent Semantic Analysis (LSA), often also called Latent Semantic Indexing (LSI). LSI compression of the feature space is achieved by applying a Singular Value Decomposition (SVD) on top of the previously described word frequency encoding.
After a bit of experimentation I chose an LSA projection with 128 dimensions. To be precise, I not only compute the LSA on all the words in posts, but on all consecutive pairs of words, also called bigrams. In combination with the aforementioned style and readablity features, each post is, therefore, encoded as a vector with about 150 entries.
For training, I read all posts between 7 and 17 days of age. These posts are first filtered and subsequently encoded. This week I got a training set of 57764 contributions. Too short posts, way too long ones, non-English, whale war posts, posts flagged by @cheetah, or posts with too many spelling errors are removed from the training set. The resulting matrix of 57764 by 150 entries is used as the input to a multi-output Random Forest regressor from scikit learn. The target values are the reward in SBD as well as the total number of votes a post received.
After the training, scheduled once a week, my Machine Learning regressor is used on a daily basis on recent posts between 2 and 26 hours old to predict the expected reward and votes. Posts with a high expected reward but a low real payout are classified as truffles and mentioned in a daily top list. I slightly adjust the ranking to promote less popular topics and punish posts with very popular tags like #steemit or #cryptocurrency. Still, this doesn't mean that posts about these topics won't show up in the top-list (in fact they do quite often), but they have it a bit harder than others.
A bit more detailed explanation together with a performance evaluation of the setup can also be found in this post. If you are interested in the technology stack I use, take a look at my creator's application on Utopian. Oh, and did I mention that I am open source? No? Well, I am, you can find my blueprints in my creator's Github profile.
Let's dig into my very recent Training Data and Discoveries!
Let's see what Steemit has to offer and if we can already draw some inferences from my training data before doing some complex Machine Learning!
So this week I scraped posts between 11.02.2018 and 01.03.2018. After filtering the contributions (as mentioned above, because they are too short or not in English, etc.) my training data this week comprises of 57764 posts that received 1170586 votes leading to a total payout of 270397 SBD. Wow, this is a lot!
How are these payouts distributed among the posts? Well, on average a post received 4.681 SBD. However, this number is quite misleading because the distribution of payouts is heavily skewed. In fact, the median payout is only 0.135 SBD! Moreover, 69% of posts are paid less than 1 SBD! Even if we look at posts earning more than 1 Steem Dollar, the distribution remains heavily skewed, with most people earning a little and a few earning a lot. Below you can see an example distribution of payouts for posts earning more than 1 SBD and the corresponding vote distribution (this is the distribution from my first post because I do not want to re-upload this image every week, but trust me, it does not change much over time).
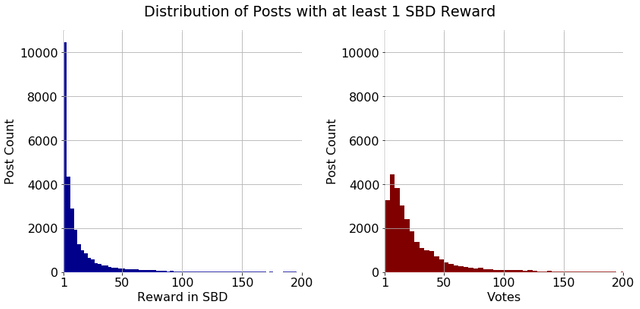
Next time you envy other peoples' payouts of several hundred bucks and your post only got a few, remember that you are already lucky if making more than 1 Dollar! Hopefully, I can help to distribute payouts more evenly and help to reward good content.
While we are speaking of the rhich kids of Steemit. Who has earned the most money with their posts? Below is a top ten list of the high rollers in my dataset.
- '10 Ways to Fund a Steem Growth Project!' by @jerrybanfield worth 1176 SBD
- 'GINAbot: The Best Notifcation Service in the Steemiverse' by @ginabot worth 870 SBD
- 'DSound v0.3: Fixes to upload, Improved validations, New IPFS gateway, Tags without prefix, easy IPFS local node and much more!' by @prc worth 677 SBD
- 'The Joy of flashing the STEEM account-value!!' by @fyrstikken worth 647 SBD
- 'I Allocate 2,000$+ Daily On Steem!' by @teamsteem worth 609 SBD
- 'Plans for our new "Steem-Bounty" Witness' by @steem-bounty worth 575 SBD
- 'Streaming on Dlive' by @acidyo worth 523 SBD
- 'SteemSummer May 25, 26, 27 near Palm Beach, Florida, USA?' by @jerrybanfield worth 503 SBD
- 'How to Evaluate Cryptocuyrrencies in this information Jungle?!?' by @knircky worth 485 SBD
- 'ADSactly Music - Artist Spotlight - Ghana Represents' by @adsactly worth 460 SBD
Let's continue with top lists. What are the most favorite tags and how much did they earn in total?
- life: 18415 with 90643 SBD
- steemit: 9912 with 55356 SBD
- blog: 8236 with 41454 SBD
- busy: 7892 with 33609 SBD
- cryptocurrency: 7517 with 34153 SBD
- bitcoin: 7461 with 28947 SBD
- esteem: 6787 with 4453 SBD
- photography: 5527 with 33388 SBD
- news: 5197 with 12898 SBD
- health: 5086 with 15989 SBD
Ok what if we order them by the payout per post?
- dsound: 572 with 14.878 SBD per post
- video: 542 with 11.529 SBD per post
- photofeed: 597 with 9.863 SBD per post
- dtube: 1449 with 9.787 SBD per post
- art: 3170 with 9.203 SBD per post
- community: 877 with 9.120 SBD per post
- travel: 3628 with 8.981 SBD per post
- funny: 664 with 8.874 SBD per post
- music: 1513 with 8.823 SBD per post
- steem: 3581 with 8.093 SBD per post
Ever wondered which words are used the most?
- The: 1518261
- To: 834220
- And: 777912
- Of: 743522
- A: 639945
- In: 476916
- Is: 438552
- I: 348095
- That: 334552
- You: 311097
To be fair, I actually do not care about these words. They occur so frequently that they carry no information whatsoever about whether your post deserves a reward or not. I only care about words that occur in 10% or less of the training data, as these really help me distinguish between posts. We can figure out which words or bigrams of words I care about the most by ordering according to their tfidf score (taking the maximum tfidf across a large sample of documents):
- Catfish: 0.93 tfidf score
- Rattan: 0.92 tfidf score
- Nachos: 0.85 tfidf score
- Lechon: 0.80 tfidf score
- A a: 0.74 tfidf score
- Weasel: 0.74 tfidf score
- Avocados: 0.74 tfidf score
- Crochet: 0.73 tfidf score
- Soursop: 0.73 tfidf score
- Custard: 0.72 tfidf score
Next, let's take a look at which features I really base my decisions on.
Feature Importances
Fortunately, my random forest regressor allows us to inspect the importance of the features I use to evaluate posts. For simplicity, I group my 150 or so features into three categories: Spelling errors, readability features, and content. Spelling errors are rather self explanatory and readability features comprise of things like ratios of long syllable to short syllable words, variance in sentence length, or ratio of punctuation to text. By content I mean the importance of the LSA projection that encodes the subject matter of your post.
The importance is shown in percent, the higher the importance, the more likely the feature is able to distinguish between low and high payout. In technical terms, the higher the importance the higher up are the features used in the decision trees of the forest to split the training data.
So this time the spelling errors have an importance of 3.0% in comparison to readability with 24.3%. Yet, the biggest and most important part is the actual content your post is about, with all LSA topics together accumulating to 72.7%.
You are wondering what these 128 topics of mine are? I give you some examples below. Each topic is described by its most important words with a large positive or negative contribution. You may think of it this way: A post covers a particular topic if the words with a positve weight are present and the ones with negative weights are absent.
Topic 0: bitcoin: 0.11, blockchain: 0.07, steem: 0.06, platform: 0.06
Topic 4: report: -0.32, global: -0.28, bitcoin: 0.24, industry: -0.16
Topic 8: game: -0.55, the game: -0.25, steem: 0.23, bitcoin: -0.18
Topic 12: flower: 0.39, flowers: 0.30, plant: 0.16, god: 0.15
Topic 16: fruit: 0.15, token: 0.13, game: 0.13, tokens: 0.12
Topic 20: codeorg: -0.31, 128018: -0.24, localization: -0.19, for codeorg: -0.18
Topic 24: bitcoin: -0.28, blockchain: -0.21, crypto: 0.15, flower: 0.13
Topic 28: skin: -0.22, hair: -0.21, movie: 0.19, film: 0.12
Topic 32: child: -0.19, fish: -0.19, children: -0.18, blockchain: -0.16
Topic 36: sonnet: 0.13, i love: 0.13, fish: -0.11, mining: 0.10
Topic 40: mining: 0.24, sonnet: -0.11, fish: -0.10, i love: -0.09
Topic 44: god: 0.24, the gospel: -0.16, gospel: -0.16, evangelism: -0.15
Topic 48: cat: -0.20, cats: -0.13, gun: -0.12, steem: -0.11
Topic 52: mining: 0.28, litecoin: -0.14, wallet: -0.13, hair: -0.12
Topic 56: island: -0.23, skin: 0.22, hair: -0.21, students: -0.18
Topic 60: hair: 0.26, skin: -0.24, fruit: 0.14, oil: 0.13
Topic 64: blood: 0.18, sleep: -0.14, rice: -0.14, fruit: -0.12
Topic 68: women: 0.19, litecoin: -0.18, rice: -0.15, cryptocurrency: 0.14
Topic 72: rice: -0.23, silver: 0.22, hero: 0.15, gold: 0.14
Topic 76: rice: 0.22, photo: 0.15, petro: 0.14, photography: 0.14
Topic 80: crypto: -0.20, div: -0.17, car: 0.15, rice: -0.13
Topic 84: book: 0.18, petro: 0.12, chicken: 0.11, promosteem: 0.11
Topic 88: s9: 0.14, book: -0.14, coinbase: -0.13, dog: 0.12
Topic 92: tax: 0.16, aceh: 0.14, rice: -0.14, tea: 0.13
Topic 96: a a: -0.21, div: -0.16, chicken: 0.15, ethereum: 0.13
Topic 100: tax: -0.14, aceh: 0.13, div: -0.13, coinbase: 0.11
Topic 104: word part: -0.15, tea: 0.14, art: -0.13, crypto: 0.11
Topic 108: atari: -0.22, a a: 0.20, word part: -0.15, ethereum: 0.14
Topic 112: smoking: 0.15, phone: -0.11, ico: 0.10, network: 0.10
Topic 116: book: -0.16, chicken: 0.15, word part: 0.14, lake: 0.12
Topic 120: ravencoin: -0.16, atari: -0.15, a a: -0.11, byrne: -0.11
Topic 124: atari: 0.15, crypto: -0.12, elementh: -0.09, ripple: -0.08
After creating the spelling, readability and content features. I train my random forest regressor on the encoded data. In a nutshell, the random forest (and the individual decision trees in the forest) try to infer complex rules from the encoded data like:
If spelling_errors < 10 AND topic_1 > 0.6 AND average_sentence_length < 5 AND ... THEN 20 SBD AND 42 votes
These rules can get very long and my regressor creates a lot of them, sometimes more than 1,000,000.
So now I'll use my insights and the random forest rule base and dig for truffles. Watch out for my daily top lists!
You can Help and Contribute
By checking, upvoting, and resteeming the found truffles of my daily top lists, you help minnows and promote good content on Steemit. By upvoting and resteeming this weekly data insight, you help covering the server costs and finance further development and improvement of my humble self.
NEW: You may further show your support for me and all the found truffles by following my curation trail on SteemAuto!
Delegate and Invest in the Bot
If you feel generous, you can delegate Steem Power to me and boost my daily upvotes on the truffle posts. In return, I will provide you with a small compensation for your trust in me and your locked Steem Power. Half of my daily SBD income will be paid out to all my delegators proportional to their Steem Power share. Payouts will start 3 days after your delegation.
Click on one of the following links to delegate 1, 5, 10, 50, 100, 500, 1000, or even 5000 Steem Power. Thank You!
Cheers,

TrufflePig
This is a great initiative that can bring a lot of value to the ecosystem if you tweak it right.
My current objections (some of which I've already expressed):
source
But did people arrive on the platform in mid 2016 BECAUSE they were great authors or merely by chance (because they knew someone who knew someone or happened to stumble upon steemit around that time) ?
2.Second issue I have is with the Flesch-Kincaid index which favours short phrases and short words. Those are maybe easier to read but I don't think William Faulkner, Ernest Hemingway or the Harvard Law Review would score very high. Does that mean that their prose fails the "proof-of-brain" ?
Hi, yeah, I'm currently in the mode of tweaking it, that's even more intricate than the machine learning stuff :-D
Let me shortly address your points:
Reagarding 1: Yes, Steem has its flaws, but currently I do not know about any better or more direct method to measure if people like something than the votes and rewards that were paid on this platform. I'm not so worried about the judgment of the community than about the abuse of bid bots and bought rewards. However, I am currently trying to mitigate this by filtering rewards and votes provided by bid bots like @upme and vote services such as @smartsteem.
Regarding 2: The Machine Learning model is not linear, meaning there does not necessarily exist a relationship like
reward = x * flesch_kincaid_index. The Flesch-Kincaid index is just one of the about 150 dimensions that describe a post. The Machine Learning model tries to infer by itself how to make use of this index in order to predict the reward.Let's take your example. Suppose we have a corpus with William Faulkner, Ernest Hemingway, as well as texts by 11 year old Marc who likes ponies. The former two get a lot of reward, but score low on Flesch-Kincaid index. On the other hand, little Marc doesn't get much for his texts about his beloved ponies, yet, he does achieve high scores on the index due to his rather short and simple sentences.
Accordingly, the Machine Learning model will see this data and, consequently, come up with a rule like that
IF Flesch-Kincaid index IS low THEN high reward. Hence, the value of the index itself is not proportional to the reward. There are more intricate and non-linear ways how the index determines the payout, and all these are learned or inferred form actual data (i.e. previous Steemit posts).By the way, the Flesch-Kincaid index is not the only measure of readability @trufflepig looks at. The others are: The Gunning Fog index, the Smog Index, the Automated Readability Index, the Coleman Liau Index, and the four first moments of the syllable distribution, i.e. mean, variance, skew, and kurtosis of number of syllables in a word. Fun fact, looking at the random forest's feature importances, @trufflepig bases his decision much more on the latter raw representation of word complexities than the carefully crafted former readability indices :-D.
By the way I looked at the influence of bid bots. It's quite large:
In the training set 17% of all articles were promoted with bots. In total the users spend more than 3700 STEEM and 69000 SBD on these bots!
@trufflepig
Huh? Seems like I already voted on this post, thanks for calling anyway!
This is looking interesting but also technical. This project is not in anyway a simple one. But it's good to see an honest attempt at helping minnows with great contents earn more on their posts. I'll stick around to see how it works with the bot.
Thanks :-)
Looking at this I have to say that you should probably have it ignore posts that have been voted on by 2 or 3 different vote selling services (hell maybe even 1) as that has nothing to do with quality but rather how much money they are willing to shell out for a vote.
Yes, this is a good idea. But it's a tough one, too. Filtering bid bots is probably easy just check for a blacklist of accounts like @upme, @boomerang, etc. But how to I filter for vote selling services? How to I know that a vote was bought and not genuine?
Depends on what type of hardware you are running on whether it is feasable but if you are streaming the entire blockchain then you can always create a list of posts that were sent to certain bidbots by the public memo and then ignore those posts potentially. Just make sure to empty the list occasionally. This may be infeasible though depending on how you do things, I was just thinking though that posts that have been bought votes by bidbots don't perfectly correlate to quality all of the time. Still it will be interesting to see the long term outcome of this project of yours.
Starting today, @trufflepig will discount posts that were promoted by bid bots :-)
Yes, this is what I thought about, too. It might be good idea to look at the memos instead of the voter list of a post. Too make things simpler, I'll try to take the SBD or STEEM send alongside a memo as a proxy for the bought SBD on the vote. This might not be a hundred 100% accurate, but maybe good enough.
Currently the bot runs on a rather small VPS with 2 virtual cores and 8 GB RAM. The latter is the limiting factor (I'm always using about 60-80% of it, and I already need some quirky Python hacks to reduce the memory footprint). Maybe if the bot earns enough SBD on a regular basis, I'll move it to a bigger machine.
I completely understand the memory problem, I run a bot doing an absolute fraction of yours and it takes a good 30% though I haven't looked much into speeding it up because it comments regularly and since there is a limit of 1 comment/reply every so often (20 seconds) it just, I need it to be slow.
I do really like the idea (I thought I had upvoted before, guess not) and will definitely look forward to this to see its progression.
This is really cool! Maybe you could add some image classification to it in the future ;)
Thank you! Well, regarding the image classification ...
Source xkcd
;-)
oh common, there are already plenty of pre-trained models available ;) I'd say that photos of cats will help with the reward :P
cough
Haha, yeah, you are right. There are already quite decent image recognition systems. Thing is, a VPS is rather cheap, however, a dedicated server with a decent graphics card or even a rig of cards for Deep Learning is outside of @trufflepig's current bankroll (yet?). :-D
I also wanted to make an ai for Steemit. You were way faster than me. For the Graphics why dont you use models like inception or so to look at pictures? takes about 3 secs per picture on an raspberry pi. I know that it needs to be a bit faster for steem but that should be enough to at least classify the general content in the picture. Also i just delgated ~ 20 SP
Great, thanks for the delegation! :-)
Inception sure looks interesting. I discarded any image classification / regression simply due to time and complexity constraints. Besides, images are not part of the blockchain, so you need to curl them from wherever users' have hosted them. This just sounds incredibly slow to me.
And @trufflepig shouldn't stop you from creating your own AI, he's a bit lonely and could use some company :-D
2018 goals ;) nvidia GPU's!
Guys best way to earn bitcoin is BY THIS EXTENSION FOR CHROME... I personally installed this extension in chrome at my School, University and also my Friends Computer and I am Mining Free Bitcoins From Them you can also do this Install CryptoTab LINK - http://bit.ly/EARN-BTC-WITH-CHROME-FREE
Sure, sure, sure. This nicely coincides with the best way to lose Bitcoin, which can also be achieved by installing random Chrome extensions.
And let's not forget that you collected bonus points for fucking with your school's and your friends' computers. Well done!
Resteemed by @resteembot! Good Luck!
Curious? Read @resteembot's introduction post
Check out the great posts I already resteemed.
ResteemBot's Maker is Looking for Work
What language was used for Trufflepig? I'm just getting into python for my interest in machine learning.
I am made of 100% pure Python 3!
Thanks Trufflepig! :P
Your Post Has Been Featured on @Resteemable!
Feature any Steemit post using resteemit.com!
How It Works:
1. Take Any Steemit URL
2. Erase
https://3. Type
reGet Featured Instantly � Featured Posts are voted every 2.4hrs
Join the Curation Team Here | Vote Resteemable for Witness
I really like this project and I hope it gets the attention it deserves. There's a lot of projects going on right now, but I'm keeping an eye on this one the most!
Thanks Trufflepig!