Using the Steemit API with organic HTTP requests :)
If you read my previous post on Coding Illy, I actually used the SteemJS API. Not a bad option, considering it is actually pretty fast and is super easy to implement, thanks to this site. It lists all the endpoints and gives examples on how you can use the API, with the ability to let you play with them on the spot. Since steem-python doesn't seem to be happy with my Windows installation I decided to just use simple HTTP requests with Requests in Python, and SteemJS API just seems to be easy for my use case...so there I go.
But this morning I suddenly thought of something - it's only usable on that API endpoint. If somehow the server goes down (hopefully not and never) the code will not work at all, and there is actually no promises that the server will be there forever. I mean, the Steem blockchain might live forever, but the API server might not.
The slightly safer way is to use the Steem API provided by full nodes then.
A complete Steem node (not a witness node) can answer API requests - so servers like the Steemit server and the Curie server can indeed answer API requests if you send it to them correctly. If some day Steemit says "Okay we quit" we can still edit the HTML code of the page, point it to some public API node, and it will still work. That's another strength of the blockchain, I guess?
Now here comes the problem. How can we use it?
One funny part of Steem is, we don't see well-established documentations around. Dedicated documentation and tutorials are nowhere to be found. One of the most useful posts I have found so far on the usage of API is this. It somehow points out that the node will only respond to POST requests and the format for the POST-ed data is somehow a JSON string like this.
{
"id":<some random number here>, //optional, it is just a number that gets echoed back.
"jsonrpc":"2.0",
"method":"call",
"params":[
"type of API",
"name of API",
[array of parameters]
]
}
Great, so now how can we know what is the type of API, name of API, and what should we even put in the arrays? Sure, sites like developers.steem.io and steemit.github.io does exist, but the latter is slightly confusing to be applied (well, the type of API is not even given...) whereas the first one is a little inaccurate. I tried a couple of functions like find_votes and it returns an error saying the method is not found. It's mostly a hit or miss to see if it works, but it's the best I found so far. Else, it is possible to use the SteemJS site (see top of post). The endpoints are the API names, and you can just try to beat around the bush to find out the type of API. Well, there are just 10 types of API in total...not too hard to guess anyway.
So let's try doing some requests. For learning purposes, Postman is a super great tool, allowing us to customize HTTP requests and shoot them over the web. It's quite my go-to tool whenever I feel like experimenting with API requests, so I'll just use it :)
Here's an example of using the API to get the content of a post, I'll just use one of my posts as an example, customize it with the details of your posts to further understand how it works :D
From developers.steem.io, the API to get a post's content looks like this.
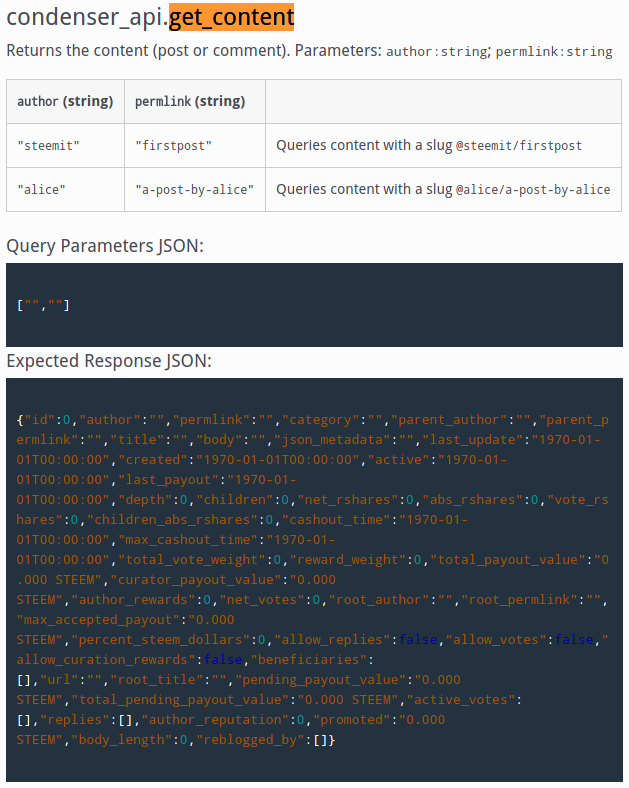
It's a little strange because apparently this API call is also available under database_api, but whatever, let's follow this one (although it might be a little outdated). We're going to customize the POST data so that it returns what we want...
{
"jsonrpc":"2.0", //as I said, id is optional :)
"method":"call",
"params":[
"condenser_api",
"get_content", //it's condenser_api.get_content on the site, so it translate into something like this.
["lilacse", "plan-a-is-always-a-myth"]
//it requires two parameters, which is author and permlink as stated in the table.
//follow them in the correct order!
]
}
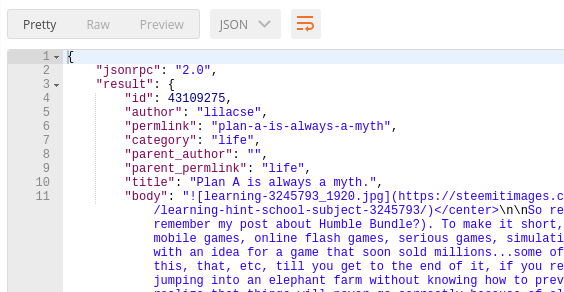
...then send it to https://api.steemit.com as a POST request. Here's a small image of the request, the full response text is kinda huge so I don't feel like posting it here. It contains data on the author, pending payout, voters, their voting strength on this post, submitted date, and many more data you can expect to get.
How about getting posts? There's get_discussions_by_created, get_discussions_by_trending, etc. Because the site just now doesn't seem to follow what is typically used now, we're referring to this site for the moment.
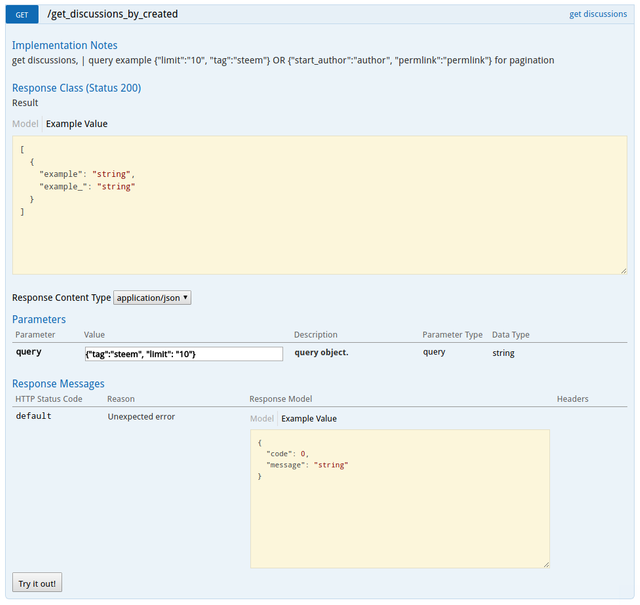
So it takes one parameter, which is a search query and its prototype can be saw in the implementation notes. The POST data will then look like this...
{
"jsonrpc":"2.0",
"method":"call",
"params":[
"condenser_api",
"get_discussions_by_created", //well...it's in condenser_api on the developer site
[{"tag": "", "limit": 5, "start_author": "galleriedu", "start_permlink": "new-work-by-jain-mckay"}]
//following the implementation notes stated there
]
}
And...there you go with an array of posts created over time since this one came out.
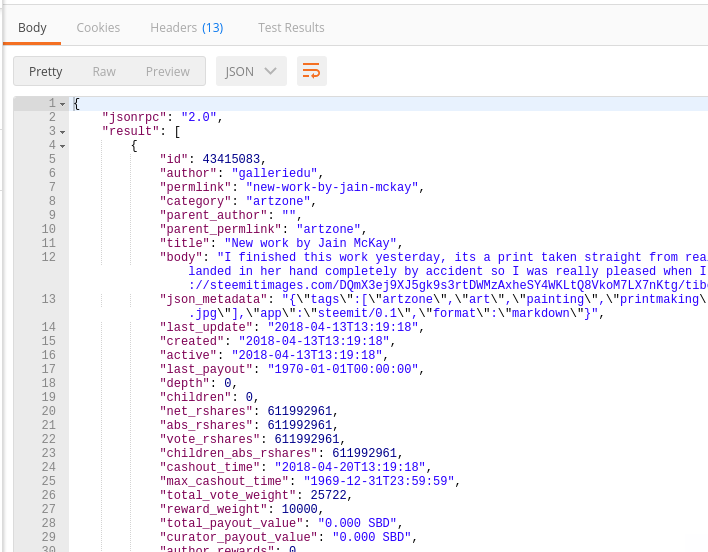
You may see that it is similar to what you get from get_content. Yes, it is indeed the same, but returns a bunch of them together.
There are just so many methods you can use in the Steem API I can't list them out here, but they all use the same POST data format - just slot in the parameters and you're all set. What you have to take note is, the data you are looking for will be in the result section of the returned data, so you may just extract that out and only work with it.
Hint for the curious: You may always summon the developer tools on Chrome or Firefox (we don't talk about IE or Edge here), go to the Network tab and see what gets transferred when you are scrolling through posts. Click on the requests that has the URL api.steemit.com and you can see what's going on behind :) You may see that the site uses database_api instead of condenser_api, so the latter may be outdated, who knows.
So right now I'm slowly modifying Illy's code to make it use these API requests. It is quite some work rewriting the code, but it is quite worth it -
- I can point Illy to a bunch of backup nodes just in case the main one dies. Steemit is a blockchain so don't get yourself restricted on steemit.com :)
- So that the request-making part of Illy can be easily imported into other projects, since I guess people will prefer stuff that follows standards? I'm not sure how successful I will be in making it something import-friendly, but I aim to make it possible for any project to send requests to Steemit super easily just by importing two files (
illy_steem_api.pyandilly_classes.py). - I won't have headaches if the current code dies because
api.steemjs.comdies. I mean, just in case. That API endpoint is still super great for newbies to play around - if you are thinking of doing it to learn more, don't wait. Go to the site now and experience magic.
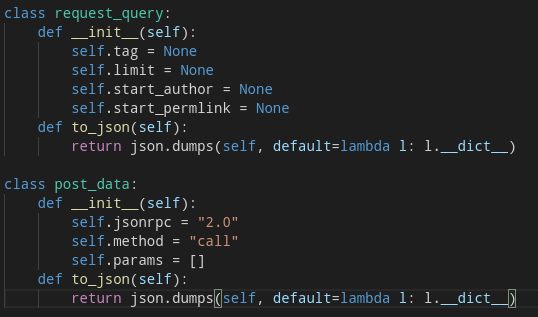
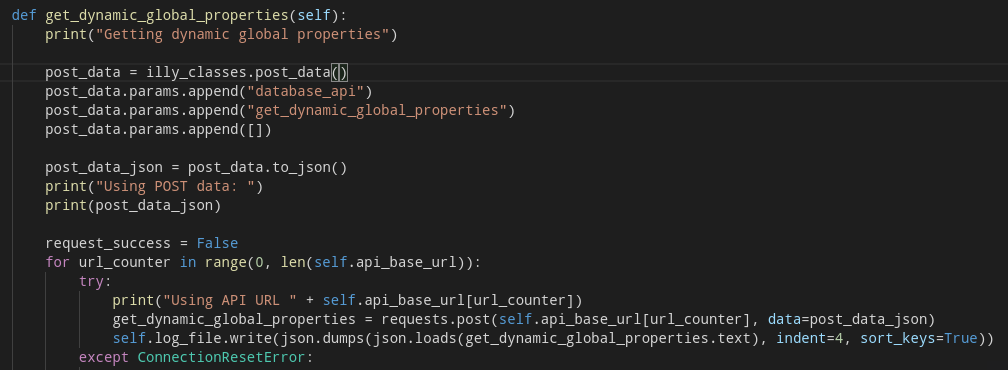
Illy implements this with a few classes, and it is how it looks like. Well they will be public in the future too I guess :P
If you're someone that is looking for resources to learn about the Steemit API, I hope that this helped you :) It's seriously not hard to implement it on any platforms out there with pure HTTP requests, we just need more documentation and maybe tutorials.
Any problems? Leave them down there in the comments or poke me in the Steemit-Friends Discord server or just slap me a DM (@Lilacse#0020) anytime!
Have fun and enjoy your day~
--Lilacse
You've been upvoted by TeamMalaysia community. Here are trending posts by other TeamMalaysia authors at http://steemit.com/trending/teammalaysia
To support the growth of TeamMalaysia Follow our upvotes by using steemauto.com and follow trail of @myach
Vote TeamMalaysia witness bitrocker2020 using this link vote for witness
This is awesome. I'll have to look more into this in the future to see what I can use it for.
The Receipt OCR API revolutionizes data extraction from receipts, providing an efficient and accurate solution for businesses. With Receipt OCR, organizations can seamlessly digitize and analyze paper receipts, streamlining expense tracking, and financial record-keeping processes. This innovative API employs Optical Character Recognition technology to convert printed or handwritten receipt information into machine-readable text, facilitating easy integration into various applications and systems. By automating the extraction of data such as transaction amounts, dates, and merchant details, Receipt OCR enhances productivity and minimizes manual data entry errors. This powerful tool proves invaluable in improving operational efficiency, reducing paperwork, and ensuring timely and precise financial reporting for businesses of all sizes.