Intoduction to XPath
Hi! In this article we will research a basics of parsing web sites and extracting information. This knowledge will be necessary for us when studying Scrapy. As you know to display a web-page browser needs to download html file from the site. Html describes to browser how web-page must look. IRL situation is more complicated, but JavaScript will be a theme of future articles. Today we will talk about parsing static or server-side generated pages. For example we will take https://steemit.com/tags web-page. Pay attention that steemit is based on React framework and it`s dynamic but for todays example it`s enough. So HTML is Hyper Text Markup Language that explains to browser what and where in display it must put information. XPath is a language that allows to extract data from HTML document. Our today task will be to create query for extracting tags from the page. To start our experiment with XPath we need Firefox browser with Firebag and Firepath addons. Let`s open https://steemit.com/tags and Firebug console in FirePath tab and inspect element.
For inspecting element just click on marked button and click on "a" tag. You will see something like next screen.
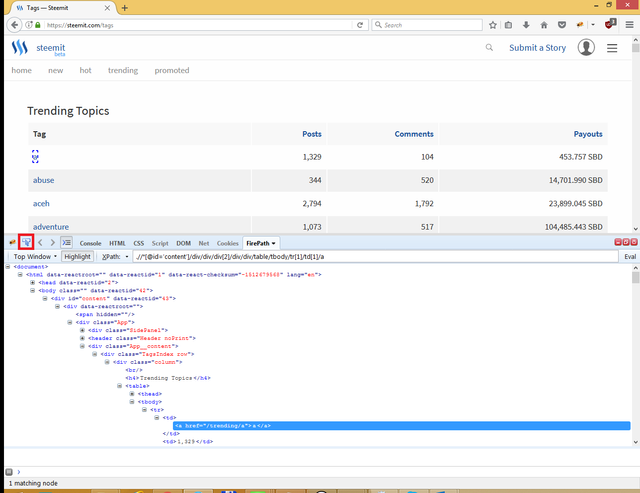
Ok now we have a query that extracts only one element:
.//*[@id='content']/div/div/div[2]/div/div/table/tbody/tr[1]/td[1]/a
what this means and how we can read it? You can imagine a query like a simple directory path where html blocks are instead of directories. We start from the root and descend to div with id = content in body block. Than we drill down through two div blocks:
.//*[@id='content']/div/div/
Now we can see condition div[2] that means drill down on the second div block. Let`s find it
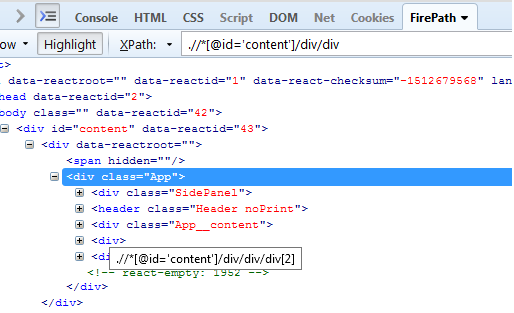
How you may see it has a class name. Let`s add it to condition instead of positional number
.//*[@id='content']/div/div/div[@class='App__content']
Next let`s look to tr[1], this condition picks up only first position of table (a) but we want to extract all positions.
.//*[@id='content']/div/div/div[@class='App__content'] /div/div/table/tbody/tr/td[1]/a
td[1] has no classes or id thats why we leave it as is.
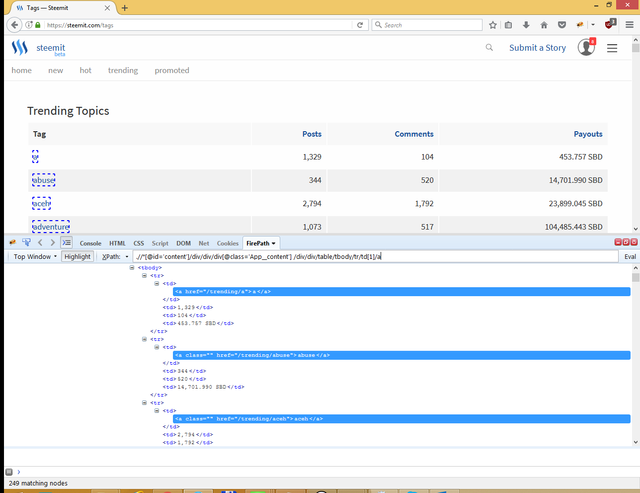
And the last step. We want only text of tag but not link, that’s why we add special function text(). Resulted query
.//*[@id='content']/div/div/div[@class='App__content']/div/div/table/tbody/tr/td[1]/a/text()
and we have 249 matching nodes.
Here you go one more query that find out all commenter of article
.//*[@id='comments']/div/div/div[@class='hentry Comment root']/div[2]/div[@class='Comment__header']/span[1]/span[1]/span[1]/span[1]/strong/text()
In the next article we will use this queries to write a spider on Scrapy.
Cool, thank you!
I will definitely follow you for more useful tips :)
You are welcome :) I hope my next article will be even more useful :)