Introducing SteemData - A Database Layer for STEEM

Why
The goal of the SteemData project is to make data from the STEEM blockchain more accessible to developers, researchers and 3rd party services.
Today, most apps use steemd as the source of data. In this context, steemd is used for fetching information about the blockchain itself, requesting blocks, and fetching recent content (ie. new blog posts from a user, homepage feed, etc.)
Unfortunately it also comes with a few shortcomings.
Running steemd locally is very hard, due to its growing RAM requirements. (None of my computers are capable of running it). Which means that we have to rely on remote RPC's, and that brings up another issue: time.
It takes a long time for a round trip request to a remote RPC server (sometimes more than 1 second per request).
Because steemd was never intended for running queries, aggregates, map-reduce, text search, it is not very well equipped to deal with historic data. If we are interested in historic data, we have to get it block-by-block form the remote RPC, which takes a really really long time.
For example, fetching the data required to create a monthly STEEM report now takes more than a week. This is simply not feasible.
Hello MongoDB
I have chosen MongoDB for this project for a couple of reasons:
- Mongo is a document-based database, which is great for storing unstructured (schema-less) data.
- Mongo has a powerful and expressive query language, ability to run aggregate queries and javascript functions directly in its shell (for example: map-reduce pattern).
- By utilizing Mongo's Oplog we can 'subscribe' to new data as well as database changes. This is useful for creating real-time applications.
- Steemit Inc is already developing a MySQL based solution, and Microsoft SQL solution exists on http://steemsql.com/
Server
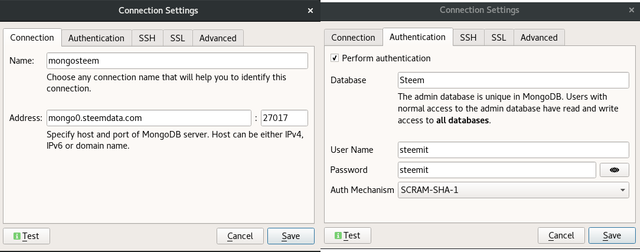
I have setup a preview version of the database as a service. You can access it on:
Host: mongo0.steemdata.com
Port: 27017
Database: Steem
Username: steemit
Password: steemit
The steemit user account is read-only.
I highly recommend RoboMongo as a GUI utility for experimenting with the database.
After you're connected, you can run queries against any collection like this:
Data Layout
Accounts
Accounts contains Steem Accounts and their:
- account info / profile
- balances
- vesting routes
- open conversion requests
- voting history on posts
- a list of followers and followings
- witness votes
- curation stats
Example
Find all Steemit users that have at least 500 followers, less than $50,000 SBD in cash, have set their profile picture, and follow me (@furion) on Steemit.
db.getCollection('Accounts').find({
'followers_count': {'$gt': 500},
'balances.SBD': {'$lte': 50000},
'profile.profile_image': {'$exists': true},
'following': {'$in': ['furion']},
})
Posts
Posts provide us with easy to query post objects, and include content, metadata, and a few added helpers. They also come with all the replies, which are also full Post objects.
A few extra niceties:
bodyfield supports Full Text Search- timestamps are parsed as native ISO dates
- amounts are parsed as Amount objects
Example
Find all Posts by @steemsports from October, which have raised at least $200.5 in post rewards and have more than 20 comments and mention @theprophet0 in the metadata.
db.getCollection('Posts').find({
'author': 'steemsports',
'created': {
'$gte': ISODate('2016-10-01 00:00:00.000Z'),
'$lt': ISODate('2016-11-01 00:00:00.000Z'),
},
'total_payout_reward.amount': {'$gte': 200.5},
'$where':'this.replies.length>20',
'json_metadata.people': {'$in': ['theprophet0']},
})
Example 2
Find all posts which mention meteor in their body:
db.getCollection('Posts').find({'$text': {'$search': 'meteor'}})
Operations
Operations represent the entire blockchain, as seen trough a time series of individual actions, such as:
operation_types = [
'vote', 'comment_options', 'delete_comment', 'account_create', 'account_update',
'limit_order_create', 'limit_order_cancel',
'transfer', 'transfer_to_vesting', 'withdraw_vesting', 'convert', 'set_withdraw_vesting_route',
'pow', 'pow2', 'feed_publish', 'witness_update',
'account_witness_vote', 'account_witness_proxy',
'recover_account', 'request_account_recovery', 'change_recovery_account',
'custom', 'custom_json'
]
Operations have the same structure as on the Blockchain, but come with a few extra fields, such as timestamp, type and block_num.
Example
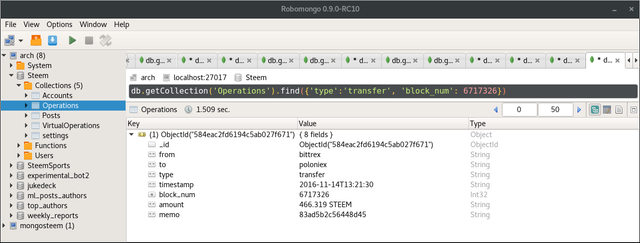
Find all transfers in block 6717326.
db.getCollection('Operations').find({'type':'transfer', 'block_num': 6717326})
We get 1 result:
{
"_id" : ObjectId("584eac2fd6194c5ab027f671"),
"from" : "bittrex",
"to" : "poloniex",
"type" : "transfer",
"timestamp" : "2016-11-14T13:21:30",
"block_num" : 6717326,
"amount" : "466.319 STEEM",
"memo" : "83ad5b2c56448d45"
}
VirtualOperations
Virtual Operations represent all actions performed by individual accounts, such as:
types = {
'account_create',
'account_update',
'account_witness_vote',
'comment',
'delete_comment',
'comment_reward',
'author_reward',
'convert',
'curate_reward',
'curation_reward',
'fill_order',
'fill_vesting_withdraw',
'fill_convert_request',
'set_withdraw_vesting_route',
'interest',
'limit_order_cancel',
'limit_order_create',
'transfer',
'transfer_to_vesting',
'vote',
'witness_update',
'account_witness_proxy',
'feed_publish',
'pow', 'pow2',
'liquidity_reward',
'withdraw_vesting',
'transfer_to_savings',
'transfer_from_savings',
'cancel_transfer_from_savings',
'custom',
}
Operations have the same structure as in the steemd database, but come with a few extra fields, such as account, timestamp, type, index and trx_id.
Example:
Query all transfers from @steemsports to @furion in the past month.
db.getCollection('VirtualOperations').find({
'account': 'steemsports',
'type': 'transfer',
'to': 'furion',
'timestamp': {
'$gte': ISODate('2016-10-01 00:00:00.000Z'),
'$lt': ISODate('2016-11-01 00:00:00.000Z'),
}})
TODO
- [] Historic 3rd party price feeds (partially done)
- [] add Indexes based on usage patterns (partially done)
- [] parse more values into native data types
- [] create relationships using HRefs
- [] Create Open-Source Server (Python+Docker based)
- [] Create Open-Source Client Libraries (Python, JS?)
Looking for feedback and testers
I would love to get community feedback on the database structure, as well as feature requests.
If you're a hacker, and have a cool app idea, feel free to use the public mongo endpoint provided by steemdata.com
Expansion Ideas
I would love to expand this service to PostgreSQL as well as build a https://steemdata.com portal with useful utilities, statistics and charts.
Sponsored by SteemSports
A 32GB RAM, Quad-Core baremetal server that is powering SteemData has been kindly provided by SteemSports.

Don't miss out on the next post - follow me
Damn this is some impressive work. Thanks for opening up an query able archive for Steemit.
This looks like incredibly useful. This must have been a lot of work. Good job!
Wow! this is great @furion. With SteemData, we could query Steem Blockchain and build Accounting App for community members or even build some tools for financial education, espically in the field of micro-financing to empower the unbanked. Congratulation.
Just want to know, I was trying to access the Steemit Database using the robomongo however it always was failing to connect. Is there new connection to the database ??
Well done my friend, I am proud of what you have accomplished here.
pretty impressive! good job!
A quick Python implementation can be seen in one of the use cases here
Great work and initiative, brother!
Is it being populated real-time?
I'm also interested to know how quickly the blockchain data gets added to the db as I have some apps in the pipeline that need a refresh quicker than SteemDB's 10 minute.
refreshing this in the browser: https://steemdata.com/stats seems to add up blocks every 5-10 seconds which is freaking awesome!
I think, there is queue for block addition it looks (15 blocks behind or so). If @furion can clarify exact numbers or way it is being populated, it would be helpful.
Operations and new Posts are near real time, new accounts will be too in the future. Everything else is delayed. Once work sharding is in place, it should be pretty fast.
Blocks don't always have data/transactions so this is why it isn't a constant x blocks added each x seconds i think, but yea, let's wait for @furion
Great accomplishment, thanks for sharing! All for one and one for all!!! Namaste :)
I might not understand everything you are saying, but this is an impressive work @furion.