SteemSmarter: Finding Daily Posts with Ruby
Steem is awesome. The Steem API documentation, however, is definitely not. I want to help change that.
A month ago @ashe-oro @crypthoe and I decided to grind on a project to explore deep into the Steem blockchain and see what interesting daily data we could dig up. The end result has been @steemsmarter, which we just launched this week. I'm going to be sharing the ups and downs our development cycles as we move forwards with our mission of Making Sense of Steem.
Today we will be taking a look at a simple but commonly asked question among Steem developers:
"How do I get find all the posts for a tag in a single day?"
This should be, "in theory", a simple calculation -- but there are particulars to how the Steem blockchain works along with severe limitations on the Steem API that make this way harder than you'd expect.
The Problem
Steem Never Sleeps
A new block on the Steem blockchain is produced every three seconds. Over the course of a single day, 28,800 new blocks carrying valuable information on posts, votes, comments, witnesses, exchanges rates and more fly past in a never-ending torrent of data.
This presents an interesting challenge while finding Steem blockchain data in the past, since you are always starting from the most recently generated block. This is a fundamental fact to keep in mind when we are designing efficient code for Steem:
The further in the past your queried data lies on the blockchain, the longer it will take to retrieve it.
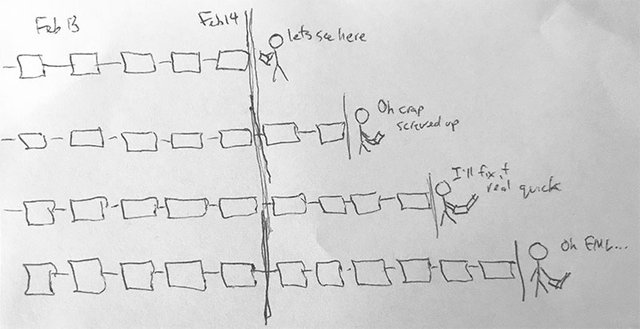
Let's say you run a query to find the 100 most recently created discussions from the blockchain for any given tag. You take a break, have a mojito, and return ten minutes later to run the same query. You are highly likely to receive a slightly different array of discussions: there will be a few newer discussions at the head of the results array, along with an equal number of oldest discussions removed from the tails of the array.
This is no big deal for a casual user clicking around on Steemit viewing 10 posts at time; after all, this pagination pattern is fundamental for feeds on social media sites. For developers interested in analyzing time-range data, however, this is a nightmare! If you want to run the same test against the same time range of posts (for example, all posts for 'crypto' created on 2018-02-14), each subsequent round of this test will take longer based on the number of blocks generated between the target time range and the current time.
Therefore any functionality that makes it easier to find just the posts (etc) specific to a time range will help all of us work with Steem a little smarter.
Steem API Woes
The current Steem API offers the following endpoints related to Tags for our interaction:
getTrendingTags(afterTag, limit, callback);
getDiscussionsByTrending(query, callback);
getDiscussionsByCreated(query, callback); // <-- this is the one we want
getDiscussionsByActive(query, callback);
getDiscussionsByCashout(query, callback);
getDiscussionsByPayout(query, callback);
getDiscussionsByVotes(query, callback);
getDiscussionsByChildren(query, callback);
getDiscussionsByHot(query, callback);
getDiscussionsByFeed(query, callback);
getDiscussionsByBlog(query, callback);
getDiscussionsByComments(query, callback);
Neat stuff, but not super useful towards our particular problem. Of these available endpoints, only getDiscussionsByCreated will return us the discussions (aka posts) for a tag in an order sorted by most recently created timestamp. The other endpoints -- while very interesting in their own respects for data analytics -- do not give us the posts in a strictly time-series oriented order.
No worries, let's just make that query param look for discussions in a certain timeframe... let's say, by using a start_created or end_created param to scope the range. Oh wait, NOPE!! This is the Steem API -- nothing is that straight forward!
Here is what that "magic" query param for getDiscussionsByCreated actually supports...
{
"tag": "steemdev",
"limit": 100,
"start_author": "thescubageek",
"start_permlink": "steem-smarter-vol-1"
}
The following params are required:
tag: tag to search against. Note that, unlike most of the rest of the query params in the Steem API, this param this is passed in as a string instead of an array of strings.limit: number of results to return from the query. The max is 100; any higher and the query will be rejected by the API. Default is 10, which is useful for pagination but not for returning large data sets.
The following params are optional and must work together to form a valid author-permlink pair; any discussion for the tag that matches the author/permlink will be the "starting discussion" from which to return results:
start_author: name of author for starting discussionstart_permlink: permlink for starting discussion
These are params are fine if we're building a pagination-based system like Steemit, but severely underwhelming for doing higher-level analytics on a cluster of data (aka our "Sample Set" of all posts for 'crypto' created on 2018-02-14).
It would be amazing if...
...the Steem API supported start_created and end_created for doing native time-based queries!!!</rant>. Unfortunately, that's just not the way things are right now... but with some clever recursion we can solve this problem.
The Solution
DISCLAIMERS: The Steem API is in Javascript, but as a Ruby on Rails developer I've done this implementation in Rails 5 using the awesome Radiator gem from @inertia for interacting with the API. Naming conventions are pretty much the same between languages (sub snake_case for camelCase when converting to JS, for example), so this should be a pretty easy port from Rails to Javascript or Python.
Pseudocode
Here's the high-level pseudocode for what we're going to try to do:
- "Rewind" the blockchain to the end time of your time range (aka 2018-02-14 11:59:59 in our example):
- Start at most recently created discussion for your tag (aka the "head")
- Find the array of the previous 100 discussions starting from the head
- While the last (oldest) discussion in the current array is more recent than the end time:
- Discard this array
- Load the next array of 100 discussions, this time starting from the last (oldest) discussion
- "Consume" the discussions on the blockchain between the end time and start time (aka 2018-02-14 00:00:00 in our example):
- Find the array of the previous 100 discussions starting from the the last (oldest) discussion in the current array, or the head if current array is empty
- While the last discussion in the current array is more recent than the start time:
- Store this array
- Load the next array of 100 discussions, this time starting from the last (oldest) discussion in the current array
- "Process" the blockchain results:
- Remove all duplicate discussions (the last discussion from the previous array will always be the first discussion of the next array, so there's always +1 duplicate between arrays)
- Remove all discussions created after the end time
- Remove all discussions created before the start time
- Return the final list of discussions
Make sense? Let's see how it works out...
Getting Started
I'm going to be solving this problem in Ruby on Rails. If you want to follow along, you'll need to:
Install Ruby on Rails 5.x on your local machine
Add the Radiator gem from inertia186 to your Gemfile
gem 'radiator'Bundle install the gem:
$ bundle install radiator
Finding All Posts For A Day
Let's create a simple helper class to handle doing these types of queries:
require 'radiator'
class SteemPostFinder
# the max results we can return for a single API query
BATCH_SIZE = 100
def initialize(tag_name)
@tag_name = tag_name
end
# find posts for a tag in a datetime range
def posts_in_time_range(start_date, end_date)
start_date = DateTime.parse(start_date)
end_date = DateTime.parse(end_date)
posts = []
####### do the magic here
posts
end
private
def api
@api ||= Radiator::Api.new
end
end
Now it's time for the magic. We're going to use get_discussions_by_created from Radiator to pull down and parse a payload of 100 posts from the Steem blockchain. First, we'll create a method inside our SteemPostFinder class to make this a little easier:
def get_posts_by_created(author="", permlink="")
params = {tag: @tag_name, limit: BATCH_SIZE}
params.merge!({
start_author: author,
start_permlink: permlink
}) unless author.blank? || permlink.blank?
# get posts from the Steem API
response = api.get_discussions_by_created(params)
return [] if response.blank?
# format response results has indifferent access array of hashes
response['result'].each(&:with_indifferent_access)
end
Note that I'm using the start_author/start_permlink params optionally. This enables us to retrieve discussions from either a specified starting post or from the head of the blockchain.
From here, we should be able to get our first set of newest posts for the tag:
# find posts for a tag in a datetime range
def posts_in_time_range(start_date, end_date)
start_date = DateTime.parse(start_date)
end_date = DateTime.parse(end_date)
posts = []
posts << get_posts_by_created
posts
end
That's only going to give us the top 100 newest posts for right now, not a specific time range. We need to rewind down the Steem blockchain using recursion to find older posts. One super important fact:
We must remember the author and permlink of the oldest post in our current set of posts in order to find the next set of posts
In Computer Science speak, the tail of the last array will be the head of the next array. Let's see how that works out:
# find posts for a tag in a datetime range
def posts_in_time_range(start_date, end_date)
start_date = DateTime.parse(start_date)
end_date = DateTime.parse(end_date)
posts = []
# this is the equivalent of a do-while loop in other languages
loop do
# find author / permlink info if last_post exists
last_post = posts.last
last_author = last_post.try(:author)
last_permlink = last_post.try(:permlink)
# concats the posts array results to the existing posts array
posts << get_posts_by_created(last_author, last_permlink)
# makes the array 1-dimensional and removes duplicates and empty elements
posts = posts.flatten.compact.uniq
# exit the do-while loop under the following circumstances:
# 1. no posts are found in the response, or
# 2. the posts returned the same list of posts as the previous response
# 3. the last post was created before the start date
should_break = posts.blank? || posts.last == last_post || DateTime.parse(posts.last.try(:created)) < start_date
break if should_break
end
end
Do-While loops are typically a no-go in my coding practice, but this is one of the rare cases where its use makes sense. The loop will continue to rewind backwards over the blockchain from a starting point until it runs out of data to consume or goes past the start date for the search.
This code gets us all of the posts from right now to the start date. Now we need to cull out the unwanted posts that fall after the end date. We will add this to the end of our posts_in_time_range method
posts.reject! do |post|
created = DateTime.parse(post.created)
created < start_date || created > end_date
end
And here we go! We should have everything we need to find all the posts for a tag in a time range. Let's take a look at the solution...
Final Answer
require 'radiator'
class SteemPostFinder
# the max results we can return for a single API query
BATCH_SIZE = 100
def initialize(tag_name)
@tag_name = tag_name
end
# find posts for a tag in a datetime range
def posts_in_time_range(start_date, end_date)
start_date = DateTime.parse(start_date)
end_date = DateTime.parse(end_date)
posts = []
# this is the equivalent of a do-while loop in other languages
loop do
# find author / permlink info if last_post exists
last_post = posts.last
last_author = last_post.try(:author)
last_permlink = last_post.try(:permlink)
# concats the posts array results to the existing posts array
Rails.logger.info("#{posts.count} posts found so far...")
posts << get_posts_by_created(last_author, last_permlink)
# makes the array 1-dimensional and removes duplicates and empty elements
posts = posts.flatten.compact.uniq
# exit the do-while loop under the following circumstances:
# 1. no posts are found in the response, or
# 2. the posts returned the same list of posts as the previous response
# 3. the last post was created before the start date
should_break = posts.blank? || posts.last == last_post || DateTime.parse(posts.last.try(:created)) < start_date
break if should_break
end
# reject all posts out of time range
Rails.logger.info("#{posts.count} posts found, removing posts out of range")
posts.reject! do |post|
created = DateTime.parse(post.created)
created < start_date || created > end_date
end
Rails.logger.info("Final results: #{posts.count} posts found")
posts
end
# gets posts from Steem API
def get_posts_by_created(author="", permlink="")
Rails.logger.info("Getting #{BATCH_SIZE} posts starting at #{author} - #{permlink}...")
params = {tag: @tag_name, limit: BATCH_SIZE}
params.merge!({
start_author: author,
start_permlink: permlink
}) unless author.blank? || permlink.blank?
# get posts from the Steem API
response = api.get_discussions_by_created(params)
return [] if response.blank?
# format response results has indifferent access array of hashes
response['result'].each(&:with_indifferent_access)
end
private
def api
@api ||= Radiator::Api.new
end
end
The Code
lib/steem_post_finder.rb
Download the gist from Github
The Magic
To search a time range for a given take, ie 'crypto' from February 14-15 2018, you would simply use:
SteemPostFinder.new('crypto').posts_in_time_range('2018-02-14','2018-02-15')
Once posts_in_time_range finishes crunching the data from the Steem API, you'll have an array of hashes for posts in that time range. This can easily be converted to JSON as well.
Let's Give Credit
Thanks to @morning for the Javascript solution using recursion, @klye for an overview of the API calls, and @inertia for creating the Radiator gem for Ruby
What's next for SteemSmarter Dev?
So you've pulled down a big array of post data from the Steem API. Now what? How do you use the data inside the posts API payload to find out anything meaningful about that post, including its payouts, author, commenters, voters, and more?
In our next post, we will take a look at Exploring the API Post Payload and how you can extract all kinds of interesting data from the Steem blockchain.
Don't forget to upvote and resteem this post if you enjoyed it, and follow both @steemsmarter and @thescubageek to keep up with our latest developments!
Until next time, keep on Steemin' Steemians!
Hi, I just followed @steemsmarter
Seems like it'll be very helpful for a newbie like me. Keep up the good work :)
I'm excited to help out newbies figure out how to make more sense of Steem. I think there's a lot of exciting ways we can build communities based on this data.
Thanks a lot for your efforts. STEEM haven't got 1 million users and even Twitter has 330 million. We have so much potential. I'm totally not powering down anywhere soon.
Good post 👍👌, Please upvote back me, @hazmisyahputra, thank you.
steemsmarter are really helpfull for all community ! it give us the top 100 newest posts for right now, not a specific time range ! we can find recently top payout post! congtragulation and best luck for it!
@ashe-oro
@thescubageek
@crypthoe
you did it!
Thanks @addys it's been a lot of work and there's a lot more work to do, but there's a lot of very cool stuff the @steemsmarter platform can do. I am excited about the work I'm doing with @ashe-oro and @crypthoe.
I look forward to rolling out more cool reports and sharing my code with the community. I appreciate your support!