Meet SteemSigma: AI-based client for Steem. MVP release
Hi Steemians! Today I'm glad to present you a new client for Steem blockchain: SteemSigma. If you like Science & Tech take a closer look at this project since it has a lot of content relevant to these themes! SteemSigma is based on machine learning techniques and allows to select interesting content without human effort.
Update: forget about the 'first' word, mentioned in the permlink since I've discovered steeve.app/ :)
Why SteemSigma
In the world of Big Data, one of the most problems faced by social network users is the selection of interesting content. Traditionally, solutions to this problem are based on the usage of the work of users or the hired editors. With the Steem creation was added another mechanism that is based on economic interest: curation payouts.
However, the constant growth in the amount of content makes these approaches less and less effective. Even in Steam, more than 10 thousand posts are created every day, which makes it impossible to manually select content. Because of this, a significant part of posts is ignored, not because of poor quality.
Problem solution
At the same time, simultaneously with the growth of the data volume, there is an explosive growth of the technologies for their processing. Machine learning based approaches allow to effectively categorize and rank content without human involvement.
So, I decided to launch SteemSigma - a client for the Steam blockchain, based on machine and deep learning technologies. At its core, Sigma is a thematic client that automatically selects posts of authors writing about science, technology, environment and programming.
Main Theme
The Sigma community is built around three main themes: science, technology, and programming. These themes are popular in the modern world, and, moreover, the popularization of such content makes a positive contribution to society. So, I believe that such content should receive much more attention than it receives now.
How it works
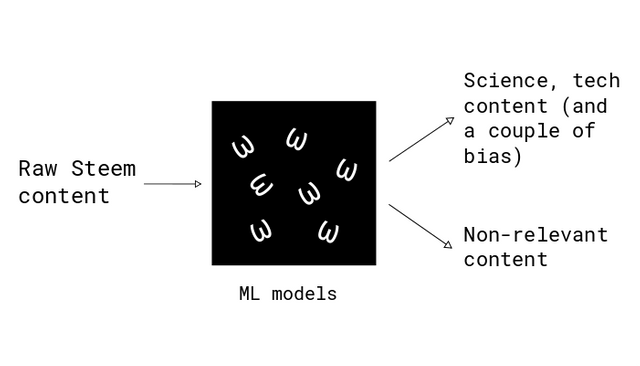
The Sigma backend is based on machine learning algorithms that can be divided into two groups:
- An algorithm that creates sentence embeddings. Unfortunately, the existing ML algorithms are able to work only with numerical data, therefore, to work with texts, they must first be converted into numerical vectors. For this purpose, Sigma uses Universal Sentence Encoder
- Classification algorithms. For this task, Sigma uses CatBoost, a library with one of the most efficient implementations of gradient boosting
Current development status
Currently, the project is in the MVP stage. That means I implemented the core components of the project: ML backend, data syncing and storage, and a simple front end. However, all of these components covers only basic functionality, such as posts reading or commenting, so there is still a lot of features to implement. It should also be noted that many functions can work not as expected due to the early stage of development
Next steps
- Improve stability of the service
- Improve the quality of ML models => the quality of content selection
- Implement new features such as recommender and rating systems
- Move to Open Source
Support project
If you are interested in Sigma project you can upvote & resteem this post, or make a direct donation to my Steem account. I will appreciate any support. Thank you!
You got a 24.69% upvote from @bdvoter courtesy of @ninjas!
Delegate your SP to us at @bdvoter and earn daily 100% profit share for your delegation & rewards will be distributed automatically daily.
500 SP, 1000 SP, 2500 SP, 5000 SP, 10000 SP.
If you are from Bangladesh and looking for community support, Join BDCommunity Discord Server & If you want to support our service, please set your witness proxy to BDCommunity.