Protecting against replay attacks in inter-operating and multi-blockchain environments
tl;dr: I suggest that blockchains still suffer from a strange replay attack and consider how this affects next-generation environments. I also offer a possible solution.
Introduction
Those with familiarity of blockchain forks will have no doubt heard of “replay attacks”. This attack is where one transaction sent on a chain can be resent on the forked chain. I will then go on speculate as to whether the vulnerability still exists, albeit in a lesser sense, and what this could mean for next-generation multi-blockchain environments.
In the last section of the article I will suggest an alternative fix which doesn’t require human invention each time a new blockchain fork occurs.

Recap of previous article
This is a follow on piece from my previous Steemit article where I discussed the two different types of attack: Basic attacks on communication protocols – replay and reflection attacks.
I can appreciate that the understanding that if a transaction is “replayed” then it must be a “replay attack”. In my previous article I reviewed some of the theory of network security and provided a suggestion as to why recent attacks looked like “reflection attacks”.
The conclusion of my previous article in brief: in network security, nonces (single-use random values) are used to prevent replay attacks while participant IDs are used to prevent reflection attacks.
In the so-called replay attacks we see in the blockchain space the proposed fix is a “network ID” which, in my mind, makes it closer to the latter. The proposed fix will help to differentiate one network from another but it doesn’t quite quash the vulnerability completely.
I think the problem still exists if you make another exact copy (fork) of any given network.
Replay attacks on forked chains
Valid transactions don’t suffer from a classic reply attack as I will describe here:
For a valid transaction on any chain we need a transaction to be sent between two valid addresses. The sender must enough coins (sufficient balance) and must provide a valid signature over the transaction in order to prove they have a right to spend the coins. Naively, each transaction is unique. The fact that double-spend is impossible means that someone who receives funds can not replay the transaction in order to receive double the funds. That would be a classic replay attack.
A problem arises when there is a forked chain. The new network is essentially a copy of the original network. The histories will be exactly the same up until the point the fork occurs, but the protocols are precisely the same.
A new transaction sent after the fork which is valid on the first network is also valid on the second network. Two valid addresses on the first chain are also valid on the second chain. The addresses plus the corresponding public and private keys are exactly the same. There is is “nothing” to distinguish the two transactions.
This is an unintended and apparently unexpected consequence of creating a forked chain.
To the best of my understanding you can only replay a new transaction once on the new forked network (once is bad enough, of course!). Note that Ethereum does have a reasonable fix in place but it isn’t quite as strong as I think it could be. Figuring out the exact fix in the Ethereum code took me a while to find!
I fear that this issue could rise again when we consider inter-operable multichain environments, and hence I fear the possible consequences of cloning a network multiple times and replaying the transaction over and over again.
Current fix for replay attacks on forked chains
The current fix is to include an identification value for the network upon which the transaction originates:
- If a transaction is for the ETH network then it will have the ETH identifier inside the transaction.
This helps to differentiate transactions on forked networks. At first I wondered if such attacks looked more like reflection attacks as much as replay attacks. In my previous article I outlined that a typical defense against reflection attacks is to include an ID parameter. The exact different between the two attacks doesn’t really matter but it did provide me with interesting food for thought and led me to write these two articles.

From what I understand of EIP 155 where the fix is discussed is that the network ID (CHAIN_ID) is set by hand in the code. For each transaction the ID value is taken as an input to the signature function: this is definitely a good way to include the ID. It actually took me quite a bit of time to figure out how the fix worked as the chain ID has a couple of different spellings in the code. Originally, it starts off as the parameter v but does eventually become part of a parameter known as m_chainID.
See: libethcore/TransactionBase.cpp
This certainly does help to clearly identify ETH and ETC transactions. It also provides strong cryptographic protection against replays provided the new fork chooses a different chain ID. Most forks will probably choose to change it, but it still gives me this lingering doubt: what if the new fork doesn’t change the ID?
Still vulnerable? Possible attack by creating another fork
I think the protocols are potentially still vulnerable to attacks if you were to make another exact copy of any given blockchain: i.e. someone makes another fork of a blockchain and uses the exact same identifier (chain_ID).
This is a problem as: the code will be kept exactly the same; the transaction history up to that point will be exactly the same, so any new transaction on the old network should also be valid on the new network. There is nothing to stop an attacker making as many copies of a blockchain as they want.
One reason you might not be worried is that the new network will have no economic value if no one uses it. This is true, but the vulnerability still exists in theory and could be a problem for the future when we have inter-operating blockchains and multi-chain environments. Moreover, it seems that not a week passes without more Bitcoin forks being announced.
Interoperating chains and multi-chain environments
This could have interesting consequences for a multichain environment. Either if we are looking at interoperability such as Lightning and Raiden, or at something more advanced like the Polkadot Network.

Polkadot has replay / reflection protection for its parachains since each parachain has a unique identifier; however, I’m not entirely sure how this applies to stand-alone blockchains which are bridged. Polkadot allows stand-alone blockchains to interact with other blockchains via its relay chain.
If my above fears are correct then for any given stand-alone blockchain fork it ought to be possible to replay any new transaction sent after the time of fork. Therefore I wonder how this plays out in future multi-chain environments where blockchains are able to sent transfer value from one chain to another. Is is possible for me to trick the relay chain by creating multiple forks and hence obtain free “money”?
To some extent such behaviour should be blocked by the various “economic” protections that Polkadot has in place. The collator nodes are supposed to find valid blockchains and present these to the validators (relay chain nodes) for processing. Collators presumably cross-check each other and then there are the Fishermen nodes who are supposed to monitor validators for strange behaviour. I presume that they may also check collators for bad behaviour, but I’m not 100% sure.
The behaviour I talk about should be somewhat easy to spot by a human but in an automated environment it is necessary to have protection mechanisms already in the code. The unique identifiers for the parachains (which only exist within the Polkadot ecosystem) will prevent the problem that I talk about; again, it isn’t clear to me that this can prevent the problem from occuring with multiple forks of the same chain.
One possibility is a registration process whereby each stand-alone blockchain must be registered on the network. This means that each new fork will have a entirely unique identifier. If properly monitored and enforced then the problem I discuss will disappear. Moreover, it somewhat suggests that a solution like Polkadot would improve the security landscape for blockchains as a whole. I know they have a goal of pooled security (as per the whitepaper (PDF)), but I suspected that was only for blockchains explicitly transacting within the Polkadot ecosystem.
For reference: the unique identifier of a parachain is known as parachain_index. Take a look under the section Candidate Parachain block of Polkadot’s specification document.
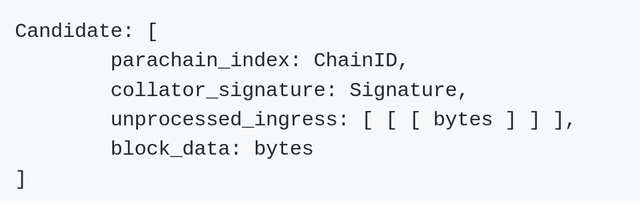
In addition to this, some code has just been released today which includes some of the code for Polkadot’s first Proof-of-Concept and we can clearly see a chainIDparameter parameter.
Another suggestion to fix “replay” attacks: transaction challenge-response protocol
The first thing that came to my mind was to implement a fix which is like a challenge-response protocol. In thinking through this problem I’ve come up with two versions: a lite version and a heavy version.
Lite version
In the lite version all transactions need to include the hash of the previous block as an input to the digital signature function. That is to say that the sender provides a cryptographic commitment to send funds (i.e. make a transaction) but also it ‘anchors’ the transaction to the previous block which is irrefutable and contains a pseudo-random nonce value. If the transaction doesn’t contain a signed recent valid hash value then it will be rejected.
Up until the point of the hard fork the transaction history and all the header hashes for the two chains will match precisely. After the fork the header hashes should no longer match provided the transactions occur between either (1) different addresses, or (2) in different blocks. There only needs to be a difference of one address (or rather, just a single bit of data) and the header hashes will diverge for all time. As header hashes contain the hash of the previous block (it is a blockchain afterall!) then this necessitates that once a single block on one of the chains is different then all future hashes will not match.
It is likely that we need assume that there is some acceptable time window of use such that the has of the previous block is perhaps the hash of a previous block within the timeframe of n blocks (choose an appropriate n for the given blockchain). The downside is that this provides a very brief window of opportunity to make a replayed transaction on the forked chain just after the fork occurs. As it is theoretically possible that the immediately following blocks contain the same contentns. While possible, it is not likely. It would be ideal if it was not possible at all.
Heavy version
The idea of taking a nonce value as an input the signature function of the transaction is kept since this really constrains when the transaction can occur; however, the difference in the heavy version is the addition of an extra nonce (and a couple of supporting parameters).
A sender wishing to make a transaction will signal to the network that they are ready to transact. The response from a mining pool node (PoW) or a validator (PoS) will contain a nonce which is valid for the next n blocks. This nonce will be signed by the mining pool, or validator, node to prove that they sent it and that the value is sufficiently fresh. Having a signed timestamp (as well as nonce value) could also help provide a robust proof of freshness; although that might be a extra unncessary ‘baggage’.
The sender who now has a nonce value, plus a validator-signed nonce-value, can now initiate their transaction and send it out to the network for validation. The transaction data should include the nonce value, the sender’s signature calculated over the nonce and the header hash of a recent block, and the validator’s signed nonce.
The nonce value can be checked as a recent value to prove freshness while the signed nonce value prove’s that the sender intended to make the transaction. Replay is prevented on the forked chain since the malicious user trying to resend the transaction would not have a valid nonce which was generated on the forked network.
It is certainly possible that a colluding validator node might try to push the replayed transaction through as valid, but this should be caught via the consensus mechanism. If the choice of the validator node which issues the nonce is random then it makes collusion harder. In addition, the inclusion of the header hash to the signature function will also make it harder to collude since a single bit of difference into a hashing algorithm will provide a entirely different hash output.
Protocol run (heavy version):
- S → V: “hello, I want to start a transaction.” (probably a broadcast message but I figure that the ‘chosen’ validator is potentially the one who created the last block.)
- V → S:
nonce,<nonce>_v(the nonce really does need to be single-use and unique per transaction). - S → broadcast_to_blockchain:
nonce,<nonce>_v,<nonce | prev_hdr_hash >_s, plus the usual transaction values which prove control over the funds.
Note: the angle brackets <...> denoate the use of a signing function. S is a sender making a transaction, V is a validator node.
I don’t guarantee that this is 100% ironclad with a hard mathemetical proof but rather I’m arguing that I think it ought prevent all replay attacks. I do note that generating on-chain randomness is a tricky problem to keep fair so there is potentially a weakness there but I am currently downplaying that risk.
The part of the protocol where the sender signals an intent to make a transaction is also going to be broadcasted across all nodes, but I’m guessing that it makes sense to select the node who sealed the previous block. The nonce is a single-transaction-only public value which strongly ties all transaction into a particular timeframe.
Note that these suggestions are only theoretical fixes. The actual coding is likely trickier. Given the extra weight of the heavy version I suspect developers will be slower to even consider it.

Hope that was informative and helpful for learning about protocol security and multi-blockchain environments. It was quite a bit longer than originally expected. One article became two long articles.
Disclaimer: This is all my own work. None of the opinions expressed in this blog are that of a past, present, or future employer.