Becoming a Data Scientist

Due to the changes in computational power and storage of data, the demand for Data Scientists has increased exponentially and will keep growing in the next years. Even though I feel that the term "data scientist" is a bit vague, I believe that doing data science serves as a starting point for beginners in the field of AI, and eventually helps them to further shape their career paths within this field.
In a broad perspective, Data Science is defined as a multi-disciplinary field that uses different methods and algorithms to extract information or knowledge and derive insights from data. Despite the fact that it seems to exist a clear definition of a Data Scientist, the role can be (an still is) confused with other job titles. I think that this misunderstanding is actually multi-sided: both specialists and companies are not entirely sure how Data Scientist's skills can benefit their business.
The main goal of this post is to illustrate the actual meaning of being a Data Scientist, from the understanding of the different data science roles, to the tools used and even some of the challenges that a Data Scientist might face while doing his/her job. Everything stated in the post it is based on my own experience while looking for a Data Science position to working as a Data Scientist.
Different Data Science roles
Speaking from my own experience and by reading different blogs on the internet, I have found that data scientists do actually have something in common despite the same title and job position: we are always looking for new job opportunities. This is something that shouldn't be taken as something negative but rather positive. The data science field and position is relatively new as data scientists draw that thin line between statisticians and software developers.
I found an interesting guide on How to Get Your First Data Science Job [1] where the authors explain some differences between different roles within the data science field. It caught my attention mostly because one of the reasons I believe data scientists are in constant look for opportunities is that their job expectations do not really match the reality and I think this is link to the fact that companies do not really posses a proper structure for data scientist, and therefore they hire someone specialist in data without a clear defined task. I think these four roles are well described in the guide and should be used by companies who are starting to integrate AI in order to build new teams in this field.
In the table below I highlighted some of the most important aspects of each of the different roles explained by [1].
Data scientists | Data analysts and business analysts | Data engineers | Machine learning engineer |
Identifying business problems | Visualizations and reports for presenting insights | Handle large amount of data | Building, deploying, and managing ML projects |
Clean and explore data | Business implications of the data | Manage databases | Implementation and optimization of models |
Generate insights | Communicate answers | Software developer oriented | Understand the theory behind ML models |
Build predictive models | Help understand results through visualizations of data | Take predictive models into production | Models to production |
Communicate findings | DS early stage |
I will perfectly understand if you still don't know where do you fall within these categories. Personally, based on my skills I could easily fall in 3 our of those 4 categories, and my current work requires the skills of those categories. The one I might be missing is the business-oriented one. The commercial aspect of an AI product is quite crucial, and I feel lucky that I am part of a department that works closely with business innovation projects, so I believe in the future I could cover 4/4 positions, but then how should I select the correct one?
If you get a position in the Data Science field right now, you would definitely experience all of these different stages and you will learn them. The difficult part might be to shape your path within one of those. I will suggest that people should not worry about the title itself but mostly about what they are passionate about and what they think they might enjoy doing at work.
The Data Science process
We are finally going to dig a bit into a very interesting part which answers the question of what are the duties of a Data Scientist. All data scientists follow a very simple and iterative process, which I will complement with come cases based on my experience so far.
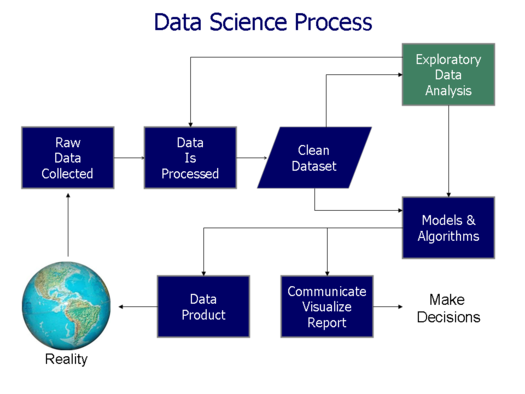
Business understanding: framing the problem
If you are part of a company, the first step that all data scientists should do is to frame the problem question. This step will normally be executed by formulating questions and/or hypothesis depending on the business or value proposition goals of the company you work for.
Sometimes when you work for a large company, such as I do, there is no direct question or established goal, but rather you might be located into an 'innovation' department, where your first duty will be to actually do market research and try to understand what are the needs for the customers, or ways to improve the existing business and existing products with innovative solutions.
In both cases, whether you need to solve a specific task for your company or conceptualize ideas, you will need the help of experts who have experience in for example use cases or talk directly to customers. It is an important step for creating any data science project and it can extend as much as needed before having a clear and defined goal.
Data acquisition: raw data collection
After understanding the context of the problem, the next step is to collect the appropriate data to solve it. It is common that when you are working for a large firm, the data might be already collected, or part of it, which means that you could already start processing the data and cleaning it in order to verify that you don't need extra data. In case of needing extra data, you will have to start collecting it by yourself.
This topic of "collecting data" is actually a bit tricky and it is very different depending if you are working on your personal project or you are part of an organization. When I was doing my master thesis, I had a lot of freedom for collecting data from any open source datasets that I could find useful for the problem at hand and the resources for storing it will mainly come from yourself or sometimes you will get access to university servers. In the case of large organizations, the decision of collecting data will not only rely on yourself but many parties are involved. With this, and some internal and external regulations that we have to account for can make much difficult the problem of collecting data. This approval process can take quite a lot of time plus the extra time that we have to wait for the enough data to be collected.
Data processing: previous to any further analysis
Raw data or real-world data comes in many different shapes, and it is necessary for a data scientist to know exactly how to process the data that they have been provided with.
Most of us already know that the easy data to process is the structured data but from experience is way more likely that you will get unstructured data when working for a company, and you will probably be getting data from different sources. However, this is not a reason to panic, I think this part is one of the coolest when working with data, specially when you get it raw and without any processing, as you have the freedom to structure it as you want to in the best way that will be easier for solving the business problem.
The first thing I will do before processing the data is to get familiar with it and understand what is the data telling you in each row and column, this is not something you will have to wait until the Exploratory Data Analysis (EDA) step happens. It is good if you take some notes on the different columns to see what is the type of data you have.
Nowadays, we are surrounded by a lot of data, and most companies approach is to collect as much data as possible, even before hiring any AI or data specialist, so is our job to get rid of unnecessary data or garbage that eventually will not give any value either for the problem framed or for the future. It is very important that when we want to present results or build a model we don't account for 'garbage' data. I can explain this with a very simple example:
If you are building a neural network that wants to predict whether an object is a computer or not, you have to teach/feed/train the network with the correct information for it. You can compare this with educating a kid, when a boy or girl points to a dog, we make sure that we tell them that is a dog and not a cat, based on the differences between those animals and the enough samples of how a dog looks and how a dog doesn't look, the boy or girl will eventually be capable of recognizing if s/he is seeing a dog or other animal.
This is applicable to any framed problem, you want to make sure that if you want to predict something, you need the right data for it, as clean as possible. When we talk about cleaning data, it refers to detecting some errors that might affect later on the output of our model. Some of this errors could be missing or corrupted values in the data. There are many random errors that you could find in the data, I have found dates in data that I had to clean that haven't even occurred yet, for example some day in 2020.
It is recommended sometimes to automatize this process, as new data will keep coming and will have to be checked the same way before being used for same or future models.
Exploratory data analysis
The EDA is basically the part where you get to play with the data and start getting some results of it. I think this part is the most creative one, as you can start mapping the values from different columns and start exploring the relationships between variables.
My approach to this step is to start by doing a univariate analysis, which is the simplest statistical analysis that you can perform, where only one variable is involved and it is easy to see what is the relationship between the different values in the expect outcome. After this type of analysis I like to start doing a bivariate analysis, when I can see the relationship between the variables and how can this relationship affect the output. A multi-variate analysis is than applied after to see the correlations between the different variables and the output.
The idea of the first part of an EDA is to try to find some patterns in order to perform a more in-deep analysis after, once we have an idea of what are the relationships among variables and what type of information it provide us with. We can start answering some of the questions for the framed problem or generating more hypothesis on the go.
Models and algorithms
Once the EDA is done, you can use the information extracted from it to start thinking and building predictive models that will help reject or accept the previous formulated hypothesis.
The chose of models will depend in the data that we collected and the problem formulation. I like to test different models in the same data to see how the models perform and to see which one is more suitable. After this step, you are capable of communicating the results.
Communicate the results
Storytelling is one of the most important skills of a data scientist, in this part is where the become the key factor for generating value from the data. You must have the necessary soft skills to communicate the insights, it is mainly a translator job where you have to explain the process that you have undertaken in order to derive results.
It is very important that you don't use very technical words when addressing this, as normally you would not be communicating results to statisticians or software developers but rather managers that are more focus on the value proposition of their business. If you fail to explain this part, you will probably fail in selling your idea, you will not convince superiors to actually make your idea a product.
Product generation
Once we have completed all the steps from the Data Science framework, the next step will be to discuss the possibilities of integrating the model into existing or as a new product. This is a very interesting aspect, as it is very cool to build your own AI solutions and sell them. There is a process of maintenance after the product is launched and you have to account for that, as new data will come and the product must be optimized.
The skills (and tools) of a Data Scientist
In this section I would like to sum up and highlight the different skills that someone should have or learn to become a data scientist.

Programming
Knowing to code is essential for a Data Scientist, as it helps with the analysis and solve statistical problems. Most used programming languages for Data Science are R and Python. I personally use Python, as I don't know R programming. As far as I know, R is more for statistical approach while I believe Python is more versatile for a data science project.
Libraries I use to Data Science: NumPy, Pandas, matplotlib, Seaborn, SciPy, scikit-learn, Keras, Tensorflow, NLTK, OpenCV.
Mathematics and statistics
It is necessary to know statistics, linear algebra and calculus to derive conclusions from large amount of data.
Data structures and databases
Handling data structures is basic when doing data science such as arrays and lists. It is also good to know how to work with raw data, not only structured by unstructured data. Data comes in many different shapes in real-world and if you want to be a good data scientist you should be familiar with the concept of unstructured data. Unstructured data is very complex but realistically, the chances of getting real world data stored in beautiful tables are not high.
Some file formats that you should be familiar with are .csv, JSON files and SQL. Databases such as Hadoop and NoSQL.
Machine learning and AI
Common knowledge of supervised and unsupervised learning algorithms is required in order to build predictive models. Data scientist do not necessary have to be experts in machine learning, as that is a position someone else will cover to complement the data scientist, but does need to know the theory behind the algorithms to understand the framed problem and how to solve it and also to understand the insights that the machine learning model generates for the business and value proposition.
Data visualization
The Data Scientist must be capable of generating understandable graphs in order to communicate the insights to other people from the company that do not have a data science background.
Communication skills
Fluently translate the technical findings into non-technical for teams in departments such as Communications, International Relations or Marketing and Sales.
Business acumen/Domain expertise
Knowing the business and industry you work in is an essential part for becoming a Data Scientist, as knowing the problems that company is facing is critical for later on solving them. Knowing the industry will also help understand better the collected data and how to generate benefits out of it.
Curiosity and creativity
I believe that one of the most important aspects to become a Data Scientist is to be curious and to be creative. The job as a data scientist is very dynamic and evolves as fast as technology, it requires a fast adaptation and introducing innovative solutions in order to stay ahead of the competition.
... and of course, you be passionate about it!
References
[1] How to Get Your First Data Science Job. Springboard 2019. Link: https://www.springboard.com/resources/guides/guide-to-data-science-jobs/
[2] AI for Everyone. Coursera course by deeplearning.ai (Andrew Ng). Link: https://www.coursera.org/learn/ai-for-everyone
[3] The Data Science Process by Springboard. Link: https://www.kdnuggets.com/2016/03/data-science-process.html
[4] The Data Science Process, Rediscovered by Matthew Mayo, KDNuggets. Link: https://www.kdnuggets.com/2016/03/data-science-process-rediscovered.html
[5] 9 Must-have skills you need to become a Data Scientist, updated. Link: https://www.kdnuggets.com/2018/05/simplilearn-9-must-have-skills-data-scientist.html
Original post:
https://codingartificialintelligence.com/2019/06/26/becoming-a-data-scientist/
Congratulations @aicoding! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Vote for @Steemitboard as a witness to get one more award and increased upvotes!
Dear STEM Geek! I am writing this comment to inform you that the leader of our tribe, @themarkymark, has unfairly banned me from the discord server of our tribe. Show him we are a decentralized community and that such acts of tyranny will not be accepted in the STEM tribe! Tell him to let me in again!
Thank you!