Ressolid’s Rating Mechanism
.png)
Ressolid’s mission of facilitating an abundance of trust is an immense challenge, and arguably the most important mechanism that will power the Ressolid trust machine is the rating system which will be used to determine user reputation. Using a blockchain to almost perfectly store information is useless if the information is not pertinent. The standard model of rating used today lacks the structure needed to provide a fair and balanced way of digitally measuring human interactions and needs a serious upgrade.
A good rating system needs to serve several functions at the same time, first it needs to be a fair portrayal of what is measured, in our case collaboration; secondly it needs to minimize biases and gamification, and thirdly it also needs to push in a desired direction by supporting a type of behavior which in our case is positive and fruitful collaborations. On the other side, of functionality, we have ergonomics and this means the user experience needs to be logical and natural. The following text will be a theoretical approach in addressing all of these challenges followed by a simple mathematical model to exemplify how it would work.
Measuring collaboration
The greatest area of concern with measuring collaboration regards biases, people tend to have an emotional approach when giving a rating, especially if something went wrong. If you have a standard rating system in which you evaluate an interaction with one question like “how did you find the interaction?”, this is not a fair way of doing it because people tend to focus on the negative and disregard the positive aspects of the interaction, thus the standard approach is way to biased to portray a proper picture of collaboration.
Firstly, we need to understand that there is no way of fully eliminating biases because human nature is biased, thus our aim is to minimize them as much as possible and one way of doing it is to arrive at a rating by using questions which are pertinent to collaboration. Because the Ressolid app will be quite versatile and permit several types of collaboration, we need to have custom tailored ways of measuring each type, but for the sake of simplification, we will address just two of them, long term team collaborations and one interaction jobs.
For jobs which involve only one interaction, due to the limited time spend interacting it’s very hard to survey the more nuanced traits of the person you came in contact with, so it’s best to keep things simpler in this context. For this type of interactions we mainly have two actors involved, on the one side we have the service provider and on the other the beneficiary, which both need to be rated, but for different things. Below we have a table with the questions which would give the rating for each side of the interaction.
For long term teamwork, we need a different approach because things become nuanced and more traits can be rated fairly in this context. Although there are hierarchies present in most teams, it does not seem like a good idea to use different metrics in rating each individual. A more cohesive approach would be to find the common denominators which are relevant to all people involved and use them for each team member. These are some of the more suitable ones: communication skills, engagement, flexibility, conflict management skills, reliability and creativity.
One other aspect we need to take into account is that things are not binary, the metrics we need to rate are not “yes” or “no” questions, thus a gradient approach would yield fairer results. This is where we need to take into account the ease of use and find a way that is user friendly and logical, one way that could provide the result needed is by using a slider from “bad” to “good” in conjunction with a number metric system like from minus 50 to positive 50 and then transpose this in the five star rating metric. For the quality of work it could range from poor to excellent, for timetable adherence it could be from terrible to perfect and so on.
This model of structuring the way ratings are assigned serves as a foundation on which we can start building the Ressolid trust mechanism, but this is not something field tested and we will aim to bring constant improvements in order to minimize biases even further.
All votes count, but are all votes equal?
All opinions should be taken into consideration, but not all opinions carry the same weight. The question is how can a digital rating system determine which votes carry more weight than others? There is no standard answer or approach, but in the case of Ressolid where the goal is to create an abundance of trust, it would be safe to say that users which proved to be more trustworthy in collaborations would have more influence in a rating score than users with less trustworthiness. But, just the standard 5 start metric is not enough to provide a good foundation for the weighted vote approach, so a different element needs to be added into the equation, like reputation maturity.
Reputation maturity
The question is simple, which would you trust more? A user with 4.7 stars and 10 interactions or a user with 4.5 star and 100 interactions. The idea is that the number of interactions also needs to be taken into consideration when portraying a user rating and this could be defined as reputation maturity. A maturity metric in conjunction with the reputation score has two main benefits, the first is that it helps other users in relating with a particular score and the second is that you can derive a more comprehensive algorithm to determine the weight of each vote. The logic is that users with higher ratings and more maturity have a higher weight than those with a lower rating or less maturity.
For the purpose of exemplifying in a simple way, we will use round numbers and simple progressions. We will take a maturity scale from 1 to 10 and ratings from 0.5 star to 5 stars which will also be equated with a scale from 1 to 10, the weight of a vote will be determined by the multiplication of the two, thus we will have weights that range from 1 to 100. Below we have a table with each weight and the mathematical formula to calculate the final rating.
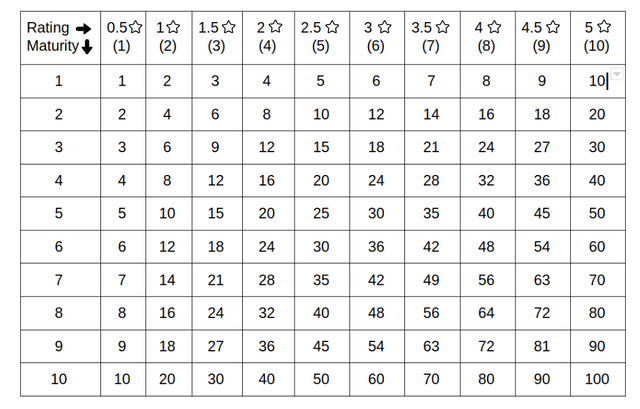
user 2 with maturity 5 and rating 4 votes with 4.5 stars ( weight = 20 )
user 3 with maturity 2 and rating 3 votes with 2 stars ( weight = 6 )
From the example given, we can see that although there are just three votes, the first of five stars, the second of 4.5 stars and the third of just 2 stars, due to the fact that the user which voted with 2 stars did not demonstrate trustworthiness, his vote did not impact the overall score in a significant way. This is not by any means a perfect system, but it can be a working model to determine a more equitable rating, starting from the premise that users with higher reputation and maturity are more trustworthy.
When deriving the maturity from the number of interactions there are some aspects that need to be factored into the equation, like the fact that different jobs have longer and shorter time spans. A one day gardening job compared to a one week IT freelance job cannot have the same intervals for determining maturity, thus we need to divide work into categories, this will become much easier and more effective as we acquire data about each field of interaction and with time we can reach an organic result. Another aspect is that people can have multiple skills, in this case, both the rating and maturity can be calculated by using the number of interactions as the weight for each one of the skills.
An area of concern that must be addressed with real world data is the prevention of creating “whales”, which would be a super influential class of users that could control most of what is happening on the platform. The goal of reputation maturity is to prevent gamification and portray a more organic reputation score, not to create class stratification.
Simplifying things
While under the hood of a car there are a lot of things going on, the driver only interacts with the cabin of the car. This should also be the case with the Ressolid rating system, while in the back end precise and complex calculations occur, the end user experience should be very simple and intuitive. So instead of displaying a maturity from 1 to 10, we can divide it up in three intervals from 1 to 4, from 4,1 to 7 and from 7,1 to 10 and we can assign a name for each interval like rookie, professional and expert, and to further simplifying we can add three levels to each interval or a loading bar that fills up with each interaction completed. So the end result would look something like the images below.
.png)
The goal is to provide a simple and effective visual way of portraying both the rating as well as the maturity so people can easily understand what is the level of each user.
Further incentivising positive and fruitful interactions
Ressolid is all about facilitating and incentivize fruitful collaboration between people and there is a way we can integrate such an incentive in the rating system. Introducing the “dispute token” which is a token that can be generated every given number of interactions and would be used in a waging mechanism to reduce the weight of a disputed vote.
A concrete example would be to generate a token every ten interactions, with a limit of no more than 3 tokens to be held at the same time. And when a user gets a bad rating, there would be the possibility of using a dispute token to minimize the effect that particular vote has on the overall rating score. A user could wage this dispute token in a bet that the following interactions will have a positive outcome, meaning that votes received will be at least 4 stars. The bet could involve from one to nine of the following interactions, the more interactions the higher is the decrease in the influence of the disputed vote, each interaction having a 10% decrease. Users would need to set the number in advance and would only win if all the interactions stated would be positive. Thus if a user bets the next three interactions are positive, in our case 4 stars or above, he would get a 30% decrease in the weight of the vote disputed in the case he wins the bet, and no decrease if he loses the bet. The maximum decrease in the weight of a vote would be by 90% if a user wages on nine positive interactions and pulls it off.
Although this might seem as gamification, it’s the positive kind because the ultimate goal is to have as many successful and rewarding interactions as possible and a dispute token wage mechanism, such as the one presented above, can have a positive role in this endeavor. And we also need to accept that people have good and bad days, so a way of minimizing the impact of a mistake made on a bad day is something that seems fair.
Let’s round things up
As stated at the beginning of this post, a good rating system needs to minimize biases, minimize gamification and incentivize desired behaviour.
Targeted questions that are relevant to collaboration aim to minimize biases when gaging interactions with other users. Weighted votes given by the combination of rating and rating maturity aims to minimize gamification. And the dispute token mechanism sets out to incentives successful interactions.
This is just the first iteration of a possible rating mechanism for the Ressolid app, a skeleton that needs to be fine tuned by real world data once the Ressolid trust machine is in motion. Future discussions and ideas need to integrated, so please join the conversation, we are fully open to any opinion.
Oh wow! Super work! This is really going in the right direction, big kudos!