Parse HTML in .NET and survive: an analysis and comparison of libraries
In the course of working on a home project, faced with the need of parsing HTML. Search on Google gave comment Athari and his micro-review of the current parsers in HTML .NET for which he thanks.
Unfortunately, no figures and/or arguments in favor of a parser has not been found, what was the reason for writing this article.
Today I will test popular at the moment, libraries for working with HTML, namely: AngleSharp, CsQuery, Fizzler, HtmlAgilityPack and, of course, Regex-way. Compare them for speed and ease of use.
TL;DR Code of all benchmarks can be found on github. There are test results. The actual parser is currently AngleSharp — convenient, fast, youth parser with easy API.
Those who are interested in a detailed overview — welcome under kat.
Content:
Description of the libraries
---HtmlAgilityPack
---Fizzler
---CsQuery
---AngleSharp
---Regex
Benchmark
---Obtaining addresses from the links on the page
---Getting data from table
Summary
Description of the libraries
In this section, a brief description of these libraries, description of licenses and so on.
HtmlAgilityPack
One of the (if not the most) famous HTML parser in the world .NET. Written about him many articles in both Russian and English, for example habrahabr.
In short it is a fast, convenient library to work with HTML (if the XPath queries will be simple). Repository long time not updated.
License MS-PL.
The parser will be convenient if the task is a typical and well described by the XPath expression, for example, to get all links from a page, we need quite a bit of code:
public IEnumerable<string> HtmlAgilityPack()
{
HtmlDocument htmlSnippet = new HtmlDocument();
htmlSnippet.LoadHtml(Html);
List<string> hrefTags = new List<string>();
foreach (HtmlNode link in htmlSnippet.DocumentNode.SelectNodes("//a[@href]"))
{
HtmlAttribute att = link.Attributes["href"];
hrefTags.Add(att.Value);
}
return hrefTags;
}
However, if you want to work with css classes, the XPath will give you a lot of headaches:
public IEnumerable<string> HtmlAgilityPack()
{
HtmlDocument hap = new HtmlDocument();
hap.LoadHtml(html);
HtmlNodeCollection nodes = hap
.DocumentNode
.SelectNodes("//h3[contains(concat(' ', @class, ' '), ' r ')]/a");
List<string> hrefTags = new List<string>();
if (nodes != null)
{
foreach (HtmlNode node in nodes)
{
hrefTags.Add(node.GetAttributeValue("href", null));
}
}
return hrefTags;
}
Noticed oddities — specific API, sometimes obscure and confusing. If none is found, returns null and not an empty collection. Well, to update the library somehow delayed — the new code hasn't comical. Bugs not fixate ( Athari mentioned a critical bug Incorrect parsing of HTML4 optional end tags that leads to incorrect processing of HTML tags, closing tags which are optional.)
Fizzler
Add-in to HtmlAgilityPack that allows you to use CSS selectors.
Code, in this case, will be a clear description of what problem it solves Fizzler:
var html = new HtmlDocument();
html.LoadHtml(@"
<html>
<head></head>
<body>
<div>
<p class='content'>Fizzler</p>
<p>CSS Selector Engine</p></div>
</body>
</html>");
var document = html.DocumentNode;
// return: [<p class="content">Fizzler</p>]
document.QuerySelectorAll(".content");
// return: [<p class="content">Fizzler</p>,<p>CSS Selector Engine</p>]
document.QuerySelectorAll("p");
// return null
document.QuerySelectorAll("body>p");
// return [<p class="content">Fizzler</p>,<p>CSS Selector Engine</p>]
document.QuerySelectorAll("body p");
// return [<p class="content">Fizzler</p>]
document.QuerySelectorAll("p:first-child");
On speed of operation practically does not differ from HtmlAgilityPack, but easier at the expense of working with CSS selectors.
Commits with the same problem as HtmlAgilityPack — updates is long gone and, apparently, is not expected.
CsQuery
Was one of the modern parsers for HTML .NET. As the basis was taken by the parser validator.nu for Java, which in turn is a port of the parser from the Gecko engine (Firefox).
API drew inspiration from jQuery, to select elements is in the language of CSS selectors. Methods are copied almost one-to-one, that is for programmers familiar with jQuery, learning will be simple.
At the moment development CsQuery is in a passive stage.
Message from the developer
The author advises to use AngleSharp as an alternative to his project.
Code for receiving links from the page looks nice and familiar for anyone used jQuery:
public IEnumerable<string> CsQuery()
{
List<string> hrefTags = new List<string>();
CQ cq = CQ.Create(Html);
foreach (IDomObject obj in cq.Find("a"))
{
hrefTags.Add(obj.GetAttribute("href"));
}
return hrefTags;
}
AngleSharp
Unlike CsQuery, written from scratch in C#. Also includes parsers for other languages.
APIs are based on the official specification for JavaScript HTML DOM. In some places there are oddities, unusual for developers .NET (for example, by referring to the wrong index in the collection will return null, not throw an exception; there is a separate class Url; namespace very granular), but overall, nothing critical.
Developing a library of very quickly. The number of different buns that make simply amazing, for example IHtmlTableElement, IHtmlProgressElement and so on.
The code is clean, neat, comfortable.
For example, the extraction of links from a page does not differ from Fizzler:
public IEnumerable<string> AngleSharp()
{
List<string> hrefTags = new List<string>();
var parser = new HtmlParser();
var document = parser.Parse(Html);
foreach (IElement element in document.QuerySelectorAll("a"))
{
hrefTags.Add(element.GetAttribute("href"));
}
return hrefTags;
}
But for more complex cases, there are dozens of specialized interfaces that help to solve the problem.
Regex
The ancient and not the best approach for working with HTML. I really liked the review Athari so I did, comment here and duplicates:
Terrible and horrible regular expressions. To apply them is not desirable, but sometimes necessary because parsers that build a DOM, visibly hungry than Regex: they consume more CPU time and memory.
If it came to regular expressions, then you need to understand that you will not be able to build a universal and absolutely reliable solution. However, if you want to parse a specific site, this problem may not be so critical.
For God's sake, don't try to turn a regular expression into an unreadable mess. You are not writing C# code in one line with single-letter variable names, and regular expressions don't need to spoil. The regular expression engine in .NET powerful enough to be able to write good code.
Code for receiving links from the page looks more or less clear:
public IEnumerable<string> Regex()
{
List<string> hrefTags = new List<string>();
Regex reHref = new Regex(@"(?inx)
<a \s [^>]*
href \s* = \s*
(?<q> ['""] )
(?<url> [^""]+ )
\k<q>
[^>]* >");
foreach (Match match in reHref.Matches(Html))
{
hrefTags.Add(match.Groups["url"].ToString());
}
return hrefTags;
}
But if you want to work with Excel and in an elaborate format, please, first look hither.
Benchmark
The speed of the parser, anyway, one of the most important attributes. The speed of HTML rendering depends on how much time you have is one or the other task.
To measure the performance of the parsers I used the library BenchmarkDotNet from DreamWalker for which he thanks a lot.
The measurements were carried out on Intel® Core(TM) i7-4770 CPU @ 3.40 GHz, but experience tells me that relative time will be the same for any other configurations.
A few words about Regex — do not repeat this at home. Regex is a very good tool in the right hands, but working with HTML it's not exactly where there is to use it. But as an experiment I tried to implement a minimal working version of your code. His task he completed successfully, but the amount of time spent on writing this code, suggests that to repeat it I won't.
Well, let's look at benchmarks.
Obtaining addresses from the links on the page
This problem, I think, is the base for all parsers — often with such formulation of the problem begins a fascinating introduction to the world of parsers (and sometimes the Regex).
The benchmark code can be found on github and below is a table with the results:
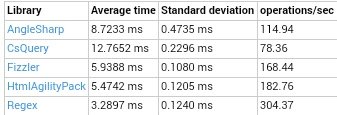
Overall, the expected Regex was the fastest, but not the most comfortable. HtmlAgilityPack and Fizzler showed approximately the same processing time, slightly ahead of AngleSharp. CsQuery is, unfortunately, hopelessly behind. It is likely that I don't know how to cook it. I will be glad to hear comments from people who worked with this library.
Appreciate the convenience of not possible, since the code is almost identical. But, ceteris paribus, CsQuery code and AngleSharp I liked more.
Getting data from table
With this task I have faced in practice. Moreover, table I predstala to work was not easy.
I attempted to maximally hide everything that is not related to HTML processing, but due to the nature of the task, not everything turned out.
Code all the libraries are about the same, the only difference is the API and how results are returned. However, it is worth mentioning two things: first, AngleSharp there are specialized interfaces that facilitate the solution of the problem. Secondly, a Regex for this task is not suitable at all nohow.
Let's look at the results:
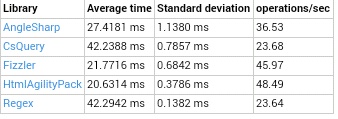
As in the previous example, HtmlAgilityPack and Fizzler showed similar and very good. AngleSharp behind them, but maybe I didn't do it in an optimal way. To my surprise, CsQuery Regex and showed the same bad processing time. If CsQuery all clear — he's just slow, then the Regex is not so clear — most likely the problem can be solved in a more optimal way.
Summary
Insights, probably everyone has done for himself. From myself I will add that the best choice now will be AngleSharp, as it is actively developed, has an intuitive API and shows good processing time. Does it make sense to run on AngleSharp with HtmlAgilityPack? Probably not — we put the Fizzler and enjoy a very fast and comfortable library.
Thank you all for your attention.
The entire code can be found in the repository on github(https://github.com/forcewake/Benchmarks). Any additions and/or changes are welcome.