Creating a curation intelligence - Post 1 - What have I done so far? and Steem Veggies
Hello everyone! I have just recently started the Spring semester at college. I apologize for not posting in the fall when school got busy, but I have still been working towards my goal of learning about programming with Steem in Python, and decided I have done enough to make a post!
What I have done so far? and Steem Veggies
I began a course on programming artificial intelligence (and data science) in Python over the break, and am a little over half-way through. I still have to actually develop the model (once I learn about all of the different options, and experiment with which ones work the best), but what I have so far is most of the work I think. At this point, what I have developed is a way to download the data in a clean way, and store it in a database. The course went over a lot about how to clean data, and how to visualize data. What I've realized is you can't really just feed an AI data, but rather you have to intuitively understand the data (which visualizations help you do), and pick the best model based on the data you have.
Anyway, I have realized that I need to make some tools for working with the data I have, and that these tools could eventually be useful to other people. So I am prematurely calling the tools Steem Veggies (pun intended). My hope is it will eventually break into three different vegetables:
Steem Asparagus - For working with individual account data such as author rewards, curation rewards, change in reputation, etc
Steem Broccoli - For working with blockchain data (I don't think this tool will be extremely important towards curation, but it could be)
Steem Carrot - For working with curation data pertaining to individual articles. This is what I currently have developed (for my use at least). The visualizations that I am using further down in this article was made using that tool.
If you would have an interest in using these tools, please let me know, and I may actually try to develop them for public use, but for now they are just for my own use in building and improving an AI.
Setup
First of all, I began this project months ago by setting up a virtual machine for linux on my laptop, and downloading the Steem Python library there. That was a week long task just figuring out how to get Steem to work in python, and I wound up having to do a lot of error searches, and installing new packages to make the installation of Steem work. Unfortunately the Steem Python library is not well-maintained. However, that virtual machine on my little laptop was not feasible, and I found myself spending more time waiting for it to load, than I actually spent working. So over the break, I had to come up with another solution, and I used WSL on my PC at home (now at school) to download pycharm, and learned how to run GUI apps on WSL. I then had to go through the entire process of setting up for Steem again, but once I did, it turned out to be a fantastic solution. Unfortunately I have to use python 3.8 because there was a huge problem in 3.9 working with Steem. I cannot emphasize enough that that library is not well-maintained.
What data am I tracking?
From there, I continued with my work which had been done on the laptop so far. The project began with a file for downloading articles from the blockchain, and extracting the data. Originally, I was storing the articles in a text file, but eventually when I was trying to delete every version except the most recent of articles that are edited, I realized that the text file wouldn't work, and @remlaps said I should learn to work with a database. So there I found myself on a week long tangent learning how to setup a mysql database. It was not hard, but very time consuming because I ran into a lot of syntax errors simply because using mysql in python involves just putting the code in strings in the execute function. So far the data I am recording is as follows (CK stands for the cksum which is a function for generating an integer to represent a word):
- Title
- Link
- Title Word Count
- Body Word Count
- Primary Language
- Primary Language CK
- Spelling Errors
- Percent of body that is spelled wrong
- Created
- Edited (boolean of whether it is edited or not)
- Total number of Edits
- Tags (only the first 5)
- Tags CK (only the first 5)
- Number of Tags
- Author
- AuthorCK
- Author reputation
- Total Beneficiaries
- Beneficiaries (list of them)
- Beneficiaries CK
- Total Votes
- Total Comments
- Percent SBD (whether it is 100 percent powered up or not)
- Total Value
- Author Value
- Curation Value
- Beneficiary Value
- Historic Values (at 4 to 10 min, 15 min, 20 min, 25 min, 30 min, 1 hour, 12 hours, 1-6 days)
- Historic average vote value (at the same time frame)
- Historic Vote Counts (at the same time frame)
- Historic Median Voter (at the same time frame)
- Historic Median Voter CK (at the same time frame)
- Historic Top Voter (at the same time frame)
- Historic Top Voter CK (at the same time frame)
- Post ID
- Post block number
The biggest challenge I faced in downloading this data was tracking the spelling errors. Originally, I was detecting the language of each word, and listing the language as one of the post's languages if that language had a certain number of words in the post. I then spell checked every word in the body in each of the dictionaries for the languages the post was in, and listed it as an error if it wasn't in any of the dictionaries. The problem came that most of the articles with bigger word counts and multiple languages were taking a minute or more to process. Almost all of the articles were taking a couple of seconds.
Some Data Visualizations
I have downloaded the data from December 18th, 2021 to January 18th, 2022 (176,902 articles). Here are some visualizations from that data!
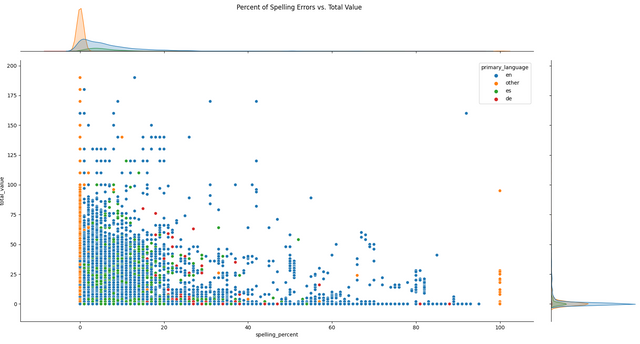
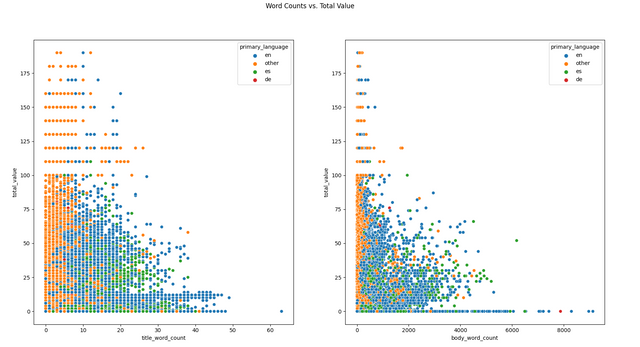
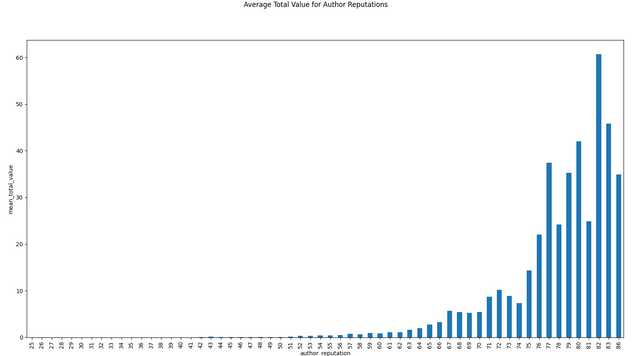
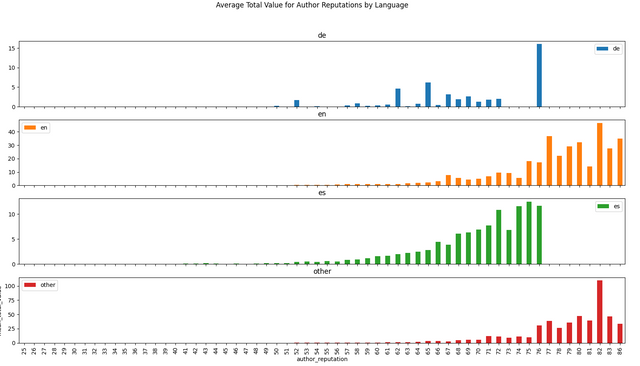
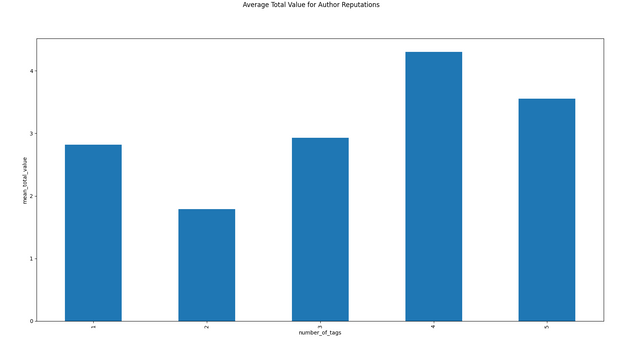
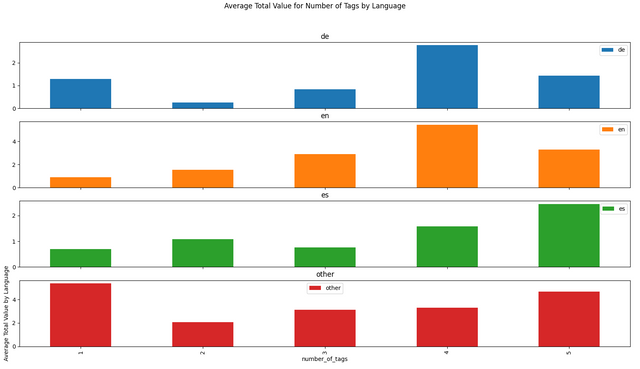
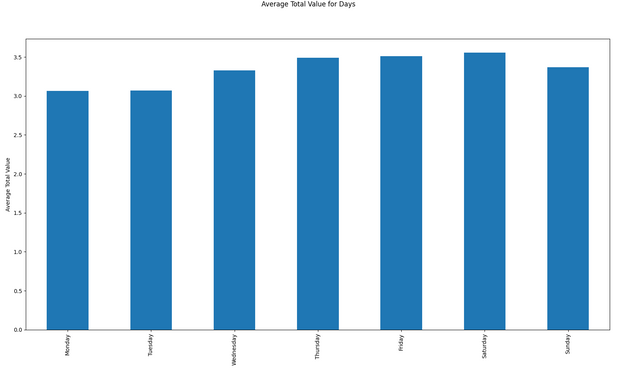
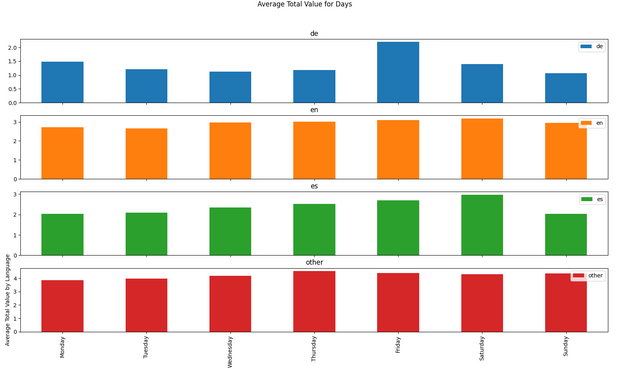
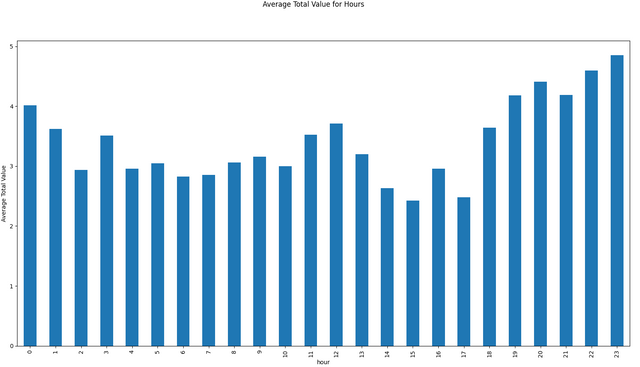
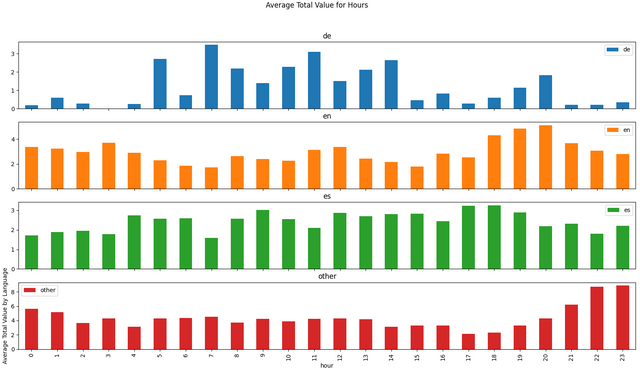
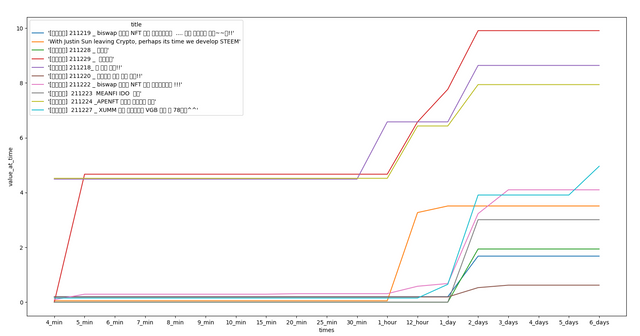
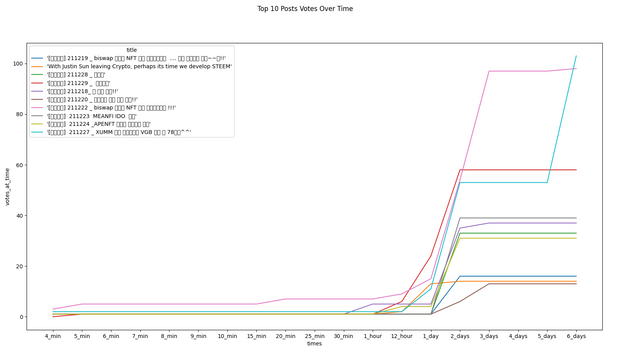
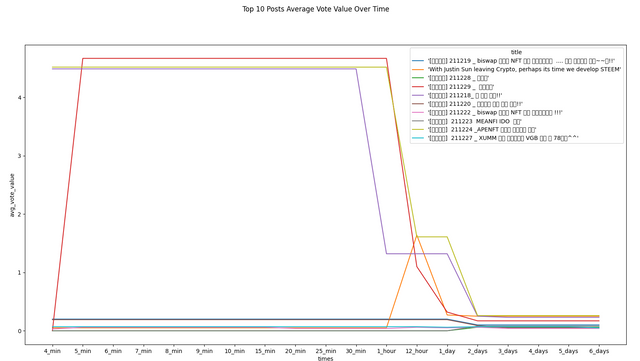
Conclusion and Requests
Thanks everyone for reading this! Feel free to suggest visualizations to add, and leave feedback on whether you would want access to a tool for visualizations like this. I will make more updates as I do more work on this project. Thanks again for reading this! @pennyforthoughts will be used to give out 25% of the liquid rewards for feedback!
I also found the installation of the Steem python library (also with python 3.9) too difficult. My problem was that a required package (pycrypto) was no longer updated and this generated errors when compiling. In the end, I could only solve it by transferring an installation from another computer. That was very annoying!
On the subject of AI: Currently you are "only" collecting quite a lot of data. This can only help to train the AI. AI usually means that the AI will later do something with the data or decide something from the data. The data will be processed, linked, etc. in some way by the AI.
Do you already have a rough idea? Or are you still searching for the possibilities?
Your visualisation is interesting in any case.
I guess that "de" means "deutsch"/german?! In that case I think it's very good ;-))
In regards to pycrypto, I think after surfing google, I learned you have to replace it with a different module, or install another module to help installing pycrypto. Eventually, I found a solution that worked, and just had to follow one of the forums on the internet I found when searching the error I was getting. But I was getting other errors in 3.9 to and just switched to 3.8 to eliminate those.
As for the AI, I am going to try predicting several things and seeing which one works best for maximizing curation rewards. It's a tough problem because there's no easy way to go about it, but one idea I had was to go through every article and calculate the change from the 5 minute value to the total value, and record a yes or no if it was in the top 10 (could be a different number) of the articles that value changed the most for that day, and giving the AI only the 5 minute value, and predicting whether or not it will be one of the articles with the largest shift in value or not. Then using that with streamed articles to curate and tweaking things from there based on real world performance.
That is what I have thought of right now with the models I have learned about in the course, but I want to wait and see how neural networks and deep learning work, and see if I can conceptualize a better idea for those models that might perform better.
Yes, "de" means German!
I also found some troubleshooting hints on the Internet, but unfortunately none of them helped me. I then found my own solution. :-) However, this was only possible because I had installed the library on another computer with the same processor architecture and the same python version.
At some point I would probably have tried the downgrade to 3.8 :-) Good to know that this also works.
Those are the strengths of an AI. In any case, it will be exciting to try different things based on the data collected. I am very curious...
Hallo @meocki ich lese immer wieder Post in denen es ums Programmiren geht dabei ist zwischen lesen und verstehen ein sehr sehr tiefes Tal , ich möchte dieses Tal wenigstens im Ansatz verstehen ,kannst Du mir was vorschlagen was man gelesen haben sollte? Oder welche P. Sprache würdest Du Anfänger empfehlen um überhaupt mal ein Grundverständnis zu bekommen ?
VgA
Hey Atego, heute bin ich wieder in Kommentar-Laune... ;-)
Jo... mit dem Programmieren fing man früher mit prozeduralen Sprachen (wie Pascal) an. Das nennt sich so, da das Programm Prozedur für Prozedur abgearbeitet wird. Ich glaube, das wird heute nicht mehr gemacht, kennt überhaupt noch jemand Pascal ;-)).
So zum Reinkommen empfehlen sich vielleicht Oberflächen wie Scratch, damit kann man visuell programmieren.
Für Objektorientierte Sprachen eignen sich dann eher Java oder eben Python. "Objektorientiert" heißt es im Grunde, da hier Objekte angelegt werden, die entsprechende Eigenschaften und Methoden besitzen...
Also ein Objekt "Hund" hat zum Beispiel eine Eigenschaft "Farbe" und eine Methode "Bellen"...
Ein ganz guter Einstieg für Python wäre z. B. https://www.python-lernen.de/. Damit hatte ich auch angefangen, da ich vor Steemit auch noch nichts mit Python programmiert hatte.
Mit Java habe ich im Studium mal ein Spiel programmiert. Da kann ich dir aktuell gar keine Epfehlung geben. Java ist wegen diverser Sicherheitslücken etwas in Verruf geraten.
Für die Blockchain ist Javascript sehr gut geeignet, da man das gut in eine Internetseite einbauen kann.
Habe momentan auch nicht den meisten Antrieb aber das gibt sich wieder
Danke für den Link
Es hat mich gefreut das du für deinen Inhalt belohnt wurdest das Betteln ist einfach nur peinlich das kommt aber auch weil die Bedingungen so einfach zu erfühlen sind da verschalt es gänzlich das der steemcurator geschrieben hat, kein Garantie Vote !
VgA
Thank you for this useful and relevant comment.
#lucky10
Thank you for the recognition.
@steemcurator01 please visit my profile and I'm not getting support from your side and I'm working since so long time here, as i am following all the club5050 and club100 rules
Buenas tardes amigo @steemcurator01, lo saludo y felicito por el gran trabajo que han venido realizando en toda la comunidad steemit, se que no es bien visto que le escribamos, pero creo que soy invisible, por que tengo ya más d 4 meses sin recibir visita de usted mi amigo ni de nuestro amigo @steemcurator02, se que el trabajo que realizan en muy grande y en muchas ocasiones serán muchos como yo los que se les pasaran por alto sin querer, tengo desde que comenzaron los #club5050, #club75 y #club100, he venido realizando mi participación con los pequeños votos que he obtenido del soporte booming, pero no he sido visitada por ustedes, me gustaría que revisara mi blog y vieran por ustedes mismo que trato de subir contenido variado cada semana, disculpe si causo molestia, pero es la única forma que he visto para llamar su atención.
Hallo.
piensa en el club Vote #club 5050, #club75 y #club100 después !
¿Encuentra el sistema de voto para el poder correctamente donde no se trata de contenido sino sólo el Poder-Up es el principal foco para obtener un voto de amor del Steemcurator?
Vote for Power-Up 👎
Best regards Atego
Habe gerade deine Antwort unter dem Bettel-Kommentar gesehen. Ich glaube, dass ist auch ein Grund, warum sich der SC mit Kommentaren zurückhält. Unter jedem Kommentar vom SC tauchen Leute auf, die dann auf sich aufmerksam machen wollen...
Thank you too
Hi! I really like statistics and would be happy to have any tool for the general public, ie not for programmers. I'm especially interested in the ability to generate reports for an individual community: the overall SP, who and how much oversees the content, anything. I don't know if this is possible and if you would be interested in it, but I think there would be a demand for such tools. Each community has moderators who would like to know statistics about their community.
That would be a very useful tool! I will look into it!
Wow man, I wish I could understand programming languages as well but then we can't do everything at once. ;)
I'm sure you'll be able to add much value to this platform
Ps: looking at your profile I learned that you're a german?
ich habe auch deutsch gelernt bis A zwei.
Auf Wiederhören
Interesting graphs. Thank you.
Obviously, you can't read too much into a single average, but I'm a little surprised that 4 tags averaged more than 5 tags in English, German, and overall.
Also, the word count graphs are interesting. I wasn't expecting to see so much English. And the language groupings for word counts in the title and bodies are interesting. Maybe part of that is because Asian languages use symbols instead of letters and words. In English, German, and Spanish, it seems like there's a strong preference for titles under 20 or so words and bodies under 1,000 or 1,500 (the image resolution won't let me distinguish in more detail).
Next, I'm thinking the "cause and effect" for total value vs. author reputation is backwards from the way we might think of it at first glance. High reputation doesn't necessarily produce high rewards, but rather, authors who consistently get high rewards build higher reputations.
First thing last, I'm curious about the horizontal bands in the upper portions of the top 3 charts.
My thoughts on this are very simple - those with high reputations often have large delegations to UpVu so both their rewards and reputations increase in parallel.
@cmp2020 - it'll be interesting to see the correlation between rewards and reputation if UpVu (and any other voting services) were removed.
Agreed. That's the sort of relationship I was thinking about, but your description is better. I was thinking the cause/effect were flipped, but that's not quite right, either. In many cases, there's another factor, having nothing to do with the "quality" or informative content of the post, that's causing both the high rewards and the high reputations.
Sir, please add me to your curation list
and I'm honest about all of that, I don't understand anything related to posting and I see that I hope I can learn from you, my friend, I don't understand that graph, you are as smart as the knowledge that you get, friends.
😅😅😃👍🏻
Sungguh kerja yang begitu bagus, sehat terus buat anda, hormat saya buat anda😇
https://steemit.com/hive-172186/@akb01/achievement-1-introduce-myself-in-world-of-steemit-akb01
https://steemit.com/hive-172186/@zain02/introduction-with-magical-steemit
Am following you, please do me a. Favour by following me