Programmieren in C - Verkettete Listen
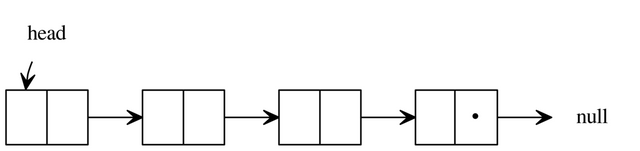
Bild Referenz: https://commons.wikimedia.org/wiki/File:DeterminingTheSizeOfASinglyLinkedListHsrw.png
{kind=link}
Intro
Hallo, ich bin's @drifter2! Das heutige Thema sind Verkette Listen die am englischen Artikel "C Linked Lists" basiert sind. Das heißt aber nicht das ich einfach den Artikel meines Hauptaccount's (@drifter1) übersetzen werde aber auch viel mehr Informationen aus dem Internet hinzufügen werde. Also dann fangen wir dann mal direkt an!
Datenstrukturen generell
Datenstrukturen sind Objekte die zur Speicherung und Organisation von Daten dienen. Es handelt sich um Strukturen die Daten in einer bestimmten Art und Weise anordnen, so das der Zugriff auf die eingespeicherten Daten und ihre Verwaltung so effizient wie möglich ist. Wir charakterisieren diese also nicht durch die enthaltenen Daten, sondern durch die Operationen auf diese Daten, die uns den Zugriff und die Verwaltung einer solchen Struktur ermöglichen.
Die leichtesten Strukturen sind die so genannten Datensätze oder Datenfelder, die ein oder mehrere Elemente enthalten. Die Struktur die aber am leichtesten verwendet werden kann ist das Feld (oder Array), wo mehrere Variablen mit dem selben Datentyp gespeichert werden. Der Zugriff auf die einzelnen Elemente wird über einen so genannten Index ermöglicht. Bei einer simplen Array kann man nur indiziert Speichern und indiziert Lesen. Damit eine solche Struktur effizienter wird können wir diese zu einer assoziativen Array umwandeln, wo der Zugriff auf die Elemente durch einen Schlüssel ermöglicht wird (die Hash-Tabelle die wir bei einen der folgenden Artikel analysieren werden). Wenn es sich um Integer oder Float-Elemente handelt (generell Nummern) kann mann natürlich auch durch das Sortieren des Feldes Zeit speichern und die Struktur effizienter beim Lesen machen. Natürlich wird das Einfügen-Speichern neuer Elemente dadurch viel langsamer. Das Problem mit Felder generell ist aber das diese meistens Statisch sind und sogar ein Dynamisches Feld, hat immer noch sehr viele Effizienz-Probleme.
Um Elemente dynamisch zu Speichern benutzen wir deswegen Dynamische Strukturen, die uns die Speicherung von beliebig vielen Objekten-Elementen ermöglichen. Solche Strukturen sind manchmal viel Effizienter bei speziellen Problemen. Natürlich müssen wir sehr viele Operationen implementieren die uns den effizientesten Zugriff und natürlich auch die Verwaltung dieser Elemente ermöglichen. Deswegen sind solche Strukturen meistens viel komplexer.
Verkettete Liste
Eine solche Dynamische Struktur ist die so genannte Liste oder Verkette Liste. Listen sind lineare Strukturen die eine angeordnete Speicherung von Datenelementen erlauben. Natürlich ist die Anzahl an Objekten-Elementen nicht festgelegt. Die Anzahl bleibt für die gesamte Lebenszeit der Listen-Struktur offen. Eine Liste enthält Elemente vom selben Datentyp. Die einfachste Liste (Einfach verkettete Liste) besteht aus Knoten die sich nur mit einen weiteren Knoten verbinden. Jeder solcher Knoten besteht aus seinen eigenen Nettodaten und einen Verweis auf den Nachfolgeknoten. Beim Letzen Knoten ist die Nachfolgeknote ein Null-Zeiger.
Wie wichtigsten und elementaren Listenoperationen sind:
- Das Erweitern der Liste - wo man einen Knoten am Anfang, Ende oder sogar zwischen bestimmten Knoten einfügt
- Das Entfernen eines Knoten - am Anfang, Ende oder sogar einen bestimmten Knoten
- Die Suche nach einem gewissen Knoten
- Ausdrucken aller Inhalte in einer normalen oder rückwärts Reihenfolge (hier wird ein Rekursiver Algorithmus sehr von Nutzen sein)
Die Effizient jeder Operation ist abhängig vom Einfügepunkt. Operationen am Anfang der Liste sind natürlich sehr schnell. Solche Operationen haben eine Komplexität von O(1). Bei N-Elementen ist die Komplexität dadurch O(N). Bei Operationen am Ende der Liste muss man natürlich durch alle Knoten iterieren das N-Schritte bedeutet. Wenn man die Effizienz einer Liste mit der eines unsortierten Feldes vergleicht sieht man das das Suchen von einem bestimmten Objekt nicht immer O(N)-Schritte braucht, sondern 1 bis N-Schritte. All das mit geringen zusätzlichen Speicherbedarf der nur aus einem Verweis-Zeiger besteht. Listen kann man auch sehr leicht mit anderen vermischen und beliebig erweitern. Das heißt das jeder Knoten nicht die selbe "Art" an Daten abspeichern muss. Manche Knoten können kleiner oder größer als die anderen sein, da diese andere Daten und Datentypen enthalten.
Nach einer gewissen Anzahl an Objekten wird eine Liste aber trotzdem gleichwertig oder sogar schlechter als ein Feld bei der Verwaltung dieser Objekte. Das gute an Listen ist aber das man an ein beliebiges Objekt unabhängig von der Anzahl an Objekten (also in konstanter Zeit) zugreifen kann.
Implementation einer Liste in C-Sprache
In C wird eine Liste natürlich als eine Struktur oder struct definiert. Einee einfach verkettete Liste besteht aus Knoten oder Nodes, die wir als struct's definieren.
Die generelle Form einer Node-struct ist:
typedef struct Node{ // Nettodaten struct Node *next; // Verweis auf Nachfolgeknoten}Node;Wie ihr sehen könnt haben wir nur einen Zeiger-Verweis auf andere Knoten. Doppelt verkette Listen enthalten einfach noch einen Zeiger mit Namen "previous" für vorheriger Knoten. Wir werden aber nur über die leichte Form reden :)
Jedes Objekt der Liste ist dadurch so eine Node-struct. Alles was wir abspeichern müssen um auf die Elemente der Liste zugreifen zu können ist nur das erste Objekt-Element der Liste das man auch Kopf (Head auf Englisch) nennt. Das geht wie folgend:
Node *head = NULL; // Kopf der ListeNatürlich muss der Kopf ein Zeiger (Pointer) sein, so das die Liste viel leichter mit Operationen bearbeitet werden kann. Ihr solltet auch nie vergessen diesen Zeiger auf NULL zu initialisieren!
Starten wir dann mal mit den elementaren Listenoperationen:
- Einfügen (Insert)
- Löschen (Delete/Remove)
- Suchen (Search)
- Ausdrucken (Print)
Einfügen
Um ein neues Element-Objekt einzufügen erstellen wir einen so genannten neuen Knoten (new Node oder nn). Bei diesem temporären Objekt werden wir die Daten des hinzuzufügenden Objektes abspeichern. Dadurch kann man sehr leicht ein Element am Anfang oder Ende einfügen. Dieses neue Objekt muss natürlich erstmal zu einen gewissen Speicher zugeordnet werden. Das geht ganz leicht mit der Funktion malloc() von stdlib. Natürlich geht all das nur wenn man das neue Element als Zeiger definiert. Wenn man mit Zeigern arbeitet, kann man auf die Strukturfelder mit "->" anstatt '.' zugreifen. Der Code der all das macht sie wie folgend aus:
Node* nn;nn = (Node*) malloc (sizeof(Node));// fuer alle Nettodaten des Knotennn->Data = value;// der Nachfolgeknoten ist beim ersten oder Kopf Knoten// natuerlich auf NULL initialisiert (mehr spaeter)nn->next = NULL;Beim einfügen müssen wir erstmals immer sehen ob die Liste leer ist, das ganz leicht mit einer Vergleichung des Kopf-Zeigers mit NULL geht (wie ihr sehen könnt ist die Initialisierung des Kopfes auf NULL hier bei diesem Schritt sehr nützlich).
Beim Einfügen am Anfang der Liste muss man einfach den "next"-Zeiger einfach auf den Kopf der Liste zeigen lassen und den neuen nn-Knoten einfach als "neuen" Kopf zurückgeben. Das geht wie folgend:
Node *insertFirst(Node *head, int val){ Node *nn; // neuen Knoten erstellen nn = (Node*)malloc(sizeof(Node)); nn->val = val; nn->next = NULL; // Kontrollieren ob Liste leer ist if(head == NULL){ // wenn ja ist nn der neue Kopf return nn; } // der vorherige Kopf wir der "next"-Zeiger nn->next = head; // nn wird als neuer Kopf zurueckgegeben return nn; }Beim Einfügen am Ende muss man erstmal durch die ganze Liste iterieren. Das geht ganz leicht durch einen current_node-Zeiger der auf die aktuelle Knote/Node zeigt. Wenn der "next"-Zeiger NULL ist ist man am letzten Knoten der Liste und kann ganz einfach diesen Zeiger zu dem "nn"-Zeiger machen. Die neue Knote/Node hat natürlich einen "next"-Zeiger der einen NULL-Wert hat. Das ganze sieht als Code wie folgend aus:
Node *insertLast(Node *head, int val){ Node *nn, *cur; // neuen Knoten erstellen nn = (Node*)malloc(sizeof(Node)); nn->val = val; nn->next = NULL; // Kontrollieren ob Liste leer ist if(head == NULL){ // return pointer to nn return nn; } // aktuelle-Knote Zeiger zeigt auf Kopf der Liste cur = head; // mit Loop letztes Element finden while(cur->next != NULL){ // aktuelle-Knote Zeiger zeigt auf das naechste Element cur = cur->next; } // Das naechste von der letzten Node wird unsere neue Knote cur->next = nn; // Listenkopf zurueckgeben return head; }Um bei einer gewissen Stelle einzufügen muss man erstmal nach einem gewissen Element suchen, bei dem man das neue Element danach einfügen will. Das könnt ihr ganz leicht implementieren wenn wir über die Suche geredet haben.
Löschen
Um ein gewisses Element löschen zu können muss die Liste natürlich nicht Leer sein. Deswegen fängt auch jede Lösch/Delete-Funktion genau mit dieser Kontrollierung an, wie ihr gleich sehen werdet.
Um das Erste Element (also den Kopf) zu löschen kann man ganz leicht den Kopf zu dem "next" Pointer vom Kopf umtauschen. Dadurch wir die Liste alles nach dem Kopf sein. Der Code sieht wie folgend aus:
Node* deleteFirst(Node *head){ // Kontrollieren ob Liste leer ist if(head == NULL){ // Liste ist leer printf("Empty List!"); return head; } // "next"-Zeiger zurueckgeben, also die Liste nach dem Kopf return head->next;}Um das letzte Element zu löschen muss man etwas ähnliches wie beim einfügen machen. Wir müssen also das Element finden das zu dem letzen Element zeigt und den "next"-Zeiger auf dieses Element auf NULL umändern. Das sieht wie folgend aus in Code:
Node* deleteLast(Node *head){ Node *cur; // Kontrollieren ob Liste leer ist if(head == NULL){ // Liste ist leer printf("Empty List!"); return head; } // Kontrollieren ob es sich um das einzige Element handelt if(head->next == NULL){ // Liste wird jetzt NULL return NULL; } // aktuelle-Knote Zeiger zeigt auf Kopf der Liste cur = head; // mit Loop das Element das zum letzten Element zeigt finden while(cur->next->next != NULL){ // aktuelle-Knote Zeiger zeigt auf das naechste Element cur = cur->next; } // "next"-Zeiger auf NULL setzten cur->next = NULL; // Listenkopf zurueckgeben return head;}Um ein gewisses Element zu löschen muss man erstmal die Knote die auf dieses Element zeigt finden und danach den "next"-Zeiger dieses Knoten zu dem "next"-Zeiger des Elements das wir löschen wollen setzen (ja hört sich schwer an, ist es aber nicht). Nach dem Suchen, das gleich kommt, könnt ihr das sicher implementieren als Aufgabe :P
Suchen
Um ein gewisses Element zu finden/suchen muss man durch alle Knoten iterieren und einen oder mehrere Werte vergleichen, die dieses Element von den anderen differenzieren. Wenn man das Element findet kann man es ausdrucken oder auch zurückgeben. Bei einer Fehlerhaften Suche (nicht gefunden) gibt man NULL zurück so das man weiß das es bei dieser Liste nicht existiert. Der Code dazu ist wie folgend:
Node* searchList(Node *head, int val){ Node *cur; // Kontrollieren ob Liste leer ist if(head == NULL){ // Liste ist leer also kann man's nicht finden printf("Empty List!"); return head; } // aktuelle-Knote Zeiger zeigt auf Kopf der Liste cur = head; // mit Loop das Element das zum letzten Element zeigt finden while(cur != NULL){ // Werte vergleichen if(cur->val == val){ // Wenn es sich um das korrekte Element // handelt gibt man es zurueck return cur; } // aktuelle-Knote Zeiger zeigt auf das naechste Element cur = cur->next; } // wenn es nicht gefunden wurde gibt man NULL zurueck return NULL; } Ausdrucken
Um die Elemente-Objekte der Liste auszudrucken kann man eine normale Iterative Funktion wie bei dem folgenden Code benutzen:
void printList(Node *head){ Node *cur; // Kontrollieren ob Liste leer lsit if(head == NULL){ printf("Empty List!"); } // aktuelle-Knote Zeiger zeigt auf Kopf der Liste cur = head; // Loop - um durch alle Knoten zu iterieren while(cur != NULL){ // mit -> drucken damit es wie eine Liste aussieht printf("%d->",cur->val); // aktuelle-Knote Zeiger zeigt auf das naechste Element cur = cur->next; } printf("NULL\n"); }Kann man damit aber jetzt auch die Liste rückwärts ausdrucken? Hmmm, die Antwort ist natürlich Nein. Ein 'Ja' würde natürlich sehr viel Speicher in Anspruch nehmen und eine weitere Datenstruktur.
Ein rekursiver Algorithmus würde natürlich eine rückwärts Ausdruckung sehr leicht ermöglichen, einen den wir jetzt erklären werden. Eine leichte Abbruchbedingung für einen solchen Algorithmus ist die "leere Liste". Bei jeder Rekursion müssen wir also kontrollieren ob die Liste leer ist, den Wert des Knoten ausdrucken und die Funktion nochmals abrufen. Der Code sieht wie folgend aus:
void printList(Node *head){ // Kontrollieren ob Liste leer ist if (head == NULL){ // Abbruchbedingung printf("NULL\n"); return; } // mit -> drucken damit es wie eine Liste aussieht printf("%d->", head->val); // nochmals abrufen mit "next"-Zeiger printList(head->next);}Wie ihr sehen könnt ist dieser Code viel kleiner und auch viel Speicher-effizienter. Mit solchen Rekursionen kann man also viel komplexere Funktionen implementieren sehr leicht implementieren. Eine solche Funktion ist die rückwärts Ausdruckung der Liste. Diese kann sehr leicht implementiert werden durch einen sehr simplen Tausch (abrufen und ausdrucken) wie beim folgenden Code:
void reversePrintList(Node *head){ // Kontrollieren ob Liste leer ist if (head == NULL){ // Abbruchbedingung printf("NULL"); return; } // nochmals abrufen mit "next"-Zeiger reversePrintList(head->next); // mit -> drucken damit es wie eine Liste aussieht printf("<-%d", head->val);}Cool hah?
Natürlich könnten wir auch viel komplexere Operationen wie Sortieren implementieren, aber das macht mehr Sinn bei anderen Datenstrukturen.
Ein komplettes Beispielprogramm
Zuletzt hier ein komplettes Programm das alle Funktionen benutzt:
int main(){ // Kopf wird als NULL initialisiert Node *head = NULL; // 5 am Anfang einfuegen und Liste "normal" ausdrucken head = insertFirst(head, 5); printList(head); // 6 am Ende einfuegen und Liste "normal" ausdrucken head = insertLast(head, 6); printList(head); // 3 am Ende einfuegen und Liste "normal" ausdrucken head = insertLast(head, 3); printList(head); // Nach '5' suchen Node *search; search = searchList(head, 5); // wenn nicht gefunden if(search == NULL){ printf("Not Found!\n"); } else{ // natuerlich wird das hier ausgedruckt printf("%d was Found!\n", search->val); } // Liste rueckwaerts ausdrucken reversePrintList(head); }Referenzen:
- https://de.wikipedia.org/wiki/Datenstruktur
- https://de.wikipedia.org/wiki/Liste_(Datenstruktur)
- http://www.inf-schule.de/algorithmen/suchbaeume/datenstrukturen/einfachliste
- https://perlgeek.de/de/artikel/einfach-verkettete-listen
- https://de.wikibooks.org/wiki/C-Programmierung:_Verkettete_Listen
- https://steemit.com/programming/@drifter1/programming-c-linked-lists
Vorherige Artikel
Grundlagen
Einführung -> Programmiersprachen, die Sprache C, Anfänger Programme
Felder -> Felder, Felder in C, Erweiterung des Anfänger Programms
Zeiger, Zeichenketten und Dateien -> Zeiger, Zeichenketten, Dateiverarbeitung, Beispielprogramm
Dynamische Speicherzuordnung -> Dynamischer Speicher, Speicherzuweisung in C, Beispielprogramm
Strukturen und Switch Case -> Switch Case Anweisung, Strukturen, Beispielprogramm
Funktionen und Variable-Gueltigkeitsbereich -> Funktionen, Variable Gueltigkeitsbereich
Datenstrukturen
Rekursive Algorithmen -> Rekursion, Rekursion in C, Algorithmen Beispiele
Schlusswort
Und das war's dann auch schon mit dem heutigen Artikel und ich hoffe ich hab alles verständlich erklärt. Νächstes mal werden wir mit einer weiteren Datenstruktur weiter machen, die so genannten Bäume (Trees).


Keep on drifting! ;)
Hello! Your post has been resteemed and upvoted by @ilovecoding because we love coding! Keep up good work! Consider upvoting this comment to support the @ilovecoding and increase your future rewards! ^_^ Steem On!

Reply !stop to disable the comment. Thanks!
wow super Artikel. Resteem. Und da wir hier schon mal jemanden vom Fach haben. Würdest du sagen, dass die Blockchain als Datenstruktur eine Technologie ist?
Ab wann ist etwas eine Technologie sehe in der Blockchain keine Technologie, erst maximal im Protokoll-Layer. "Blockchain-Technologie" kommt mir wie ein Nonsense-Begriff vor ...