The best way to analyze a huge amount of corporate data - Decision tree

The rapid development of information technology and progress in methods of data collection, storage, and processing has allowed many organizations collect massive amounts of data that must be analyzed. The volume of data is so large that experts’ capacity is not enough- it raised a demand on automatic data analysis techniques.
Decision tree - one of the major and most popular methods in the field of analysis and decision-making.
What is a decision tree
Decision tree - it is a way of representing rules in a hierarchical, coherent structure, where each object corresponds to a single node, which gives a solution.
Under the rule I mean a logical structure, presented in the form of "if ... then ...".
There are a lot of ways of using decision trees, but the problems that can be solved by this machine can be combined into the following three classes:
Information Description: Decision trees allow you to store information about the data in a compact form - we can store a decision tree that contains an exact description of the objects.
Classification: Decision trees brilliantly cope with classification tasks - assigning objects to one of the previously known classes.
Regression: If the target variable has got continuous values, decision trees allow us to establish the dependence of the target variable from independent variables. For example, numerical prediction problems are related to this class.
How to build a decision tree?
Suppose we are given a training set T, containing objects each of which is characterized by m attributes, and one of them points that the object belongs to a particular class.
{C1, C2, ... Ck} - classes (label of class value), then there are three situations:
- set T contains one or more examples of the same class Ck. Then the decision tree for T – is a leaf that defines the class Ck;
- set T does not contain a single example, it is an empty set. Then it is a leaf again, and a class, associated with a leaf, is selected from the plurality of another non-T set, from the set associated with the parent;
- set T contains examples belonging to different classes. In this case, you should divide the T set into some subsets. For this purpose one of the features having two or more distinct values O1, O2, ... On is selected. T is divided into subsets T1, T2, ... Tn, where each subset Ti contains all examples having Oi value for the selected characteristic. This procedure will continue recursively until the final set consists of the examples related to the same class.
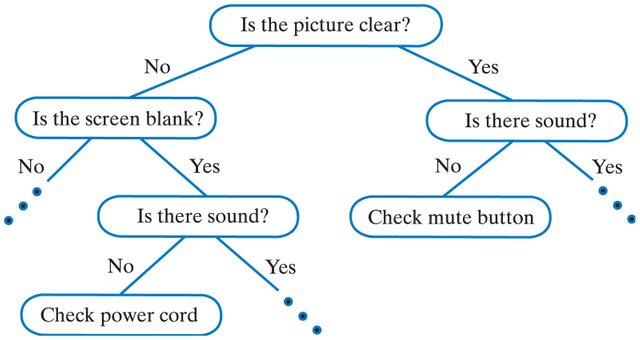
Stages of decision tree constructing
Division rule
To build the tree on each internal node it is necessary to find such a condition, which would divide the set associated with this node in the subset. One of the attributes must be selected for this check. A general rule for selecting an attribute can be summarized as follows: The selected attribute should divide the set so that the result obtained in the subset would consist of objects that belong to the same class, or would be as close to it as possible, it means that the number of objects of other classes in each of these sets would be as small as possible.
Stop rule
The use of statistical methods to assess the feasibility of further decomposition, the so-called prepruning. Ultimately prepruning of a process is attractive in terms of training time economy, but it is appropriate to make one important caveat: this approach builds less accurate classification models.
It limits the depth of the tree and stops further construction if a division leads to a creation of a tree with a depth greater than a predetermined value.
Pruning rule
Very often the algorithms for constructing decision trees provide complex trees that are "filled with the data" have a lot of nodes and branches. Such "branchy " trees are very difficult to understand.
To solve this problem pruning is often used.
A precision of recognition of the decision tree is the ratio of correctly classified objects during training to the total number of objects from the training set, and a mistake - the number of misclassified objects. Let’s assume that we know the tree error estimation method, branches, and leaves. Then we can use the following simple rule:
- build a tree;
- prune or replace those branches that do not lead to an increase of error.
In contrast to the build process, pruning of branches is done from up from the bottom, moving through leaves in a tree, marking nodes as leaves or replacing them with subtree.
The advantages of using decision trees
- quick learning process;
- intuitive classification model;
- high accuracy of the forecast;
- construction of non-parametric models.
In conclusion, I want to say that decision trees are a wonderful tool for decision support systems and data mining.
The structure of many packages for data mining includes methods of construction of decision trees. In areas where the cost of failure is high, they serve as an excellent tool for analyst or supervisor.
Decision trees are successfully used to solve practical problems in the following areas:
- Banking. The credit rating of bank customers when issuing loans.
- Industry. Quality control, non-destructive testing, etc.
- Medicine. Diagnosis of various diseases.
References: 1
Follow me, to learn more about popular science, math and technologies
With Love,
Kate
Nice post Kate :)
thanks for the feedback. Appreciate it
This is incredibly helpful. Thank you for posting. The pruning process was especially enlightening for me.
I'm glad you found this interesting. Thanks
I have already used several times (boosted) decision trees in my work, trying to use some observable quantities to be able to extract a signal from some (simulated) data. On my field, we can use the BDT in order to determine automatically how a signal would behave with respect to those observables in contrast to the background and use that information to extract it.
wow, sounds interesting. Probably you could tell about it in more details in one of your articles
I will think about it and add it to my list. I am however pretty busy those days and have not much time to write... patience may be required.... especially as i would like to continue writing my lecture notes on quantum mechanics ...
thank you for the info - I guess I'm not an engineer of sorts.... :)
upvoted and following you.
thank you)