Uczenie maszynowe #5 Testujemy sztuczny neuron (implementacja C++)
Ten artykuł będzie podsumowaniem dotychczasowej zdobytej wiedzy teoretycznej z poprzednich części, którą zaprezentujemy sobie w praktyce, używając prostego modelu neuronu liniowego ADALINE zaimplementowanego w języku C++. Artykuł podzielony będzie na dwie sekcje
- sekcję ogólną- w której wytłumaczę ideę rozpoznawania przez neuron znaków alfanumerycznych, oraz pokażę jak uruchomić gotowy program bezpośrednio w Twojej przeglądarce.
- sekcję testów - w której użytkownikowi podda się propozycję modyfikacji wartości poszczególnych zmiennych (współczynnik uczenia, zmiana funkcji aktywacji, dobór bias’u), w celach zaobserwowania zjawisk o których mówiliśmy we wcześniejszych artykułach.
Sekcja ogólna
Otwórz w nowej karcie, edytor kodu online.
Poniżej przedstawiam paint-ściągę jak go używać.
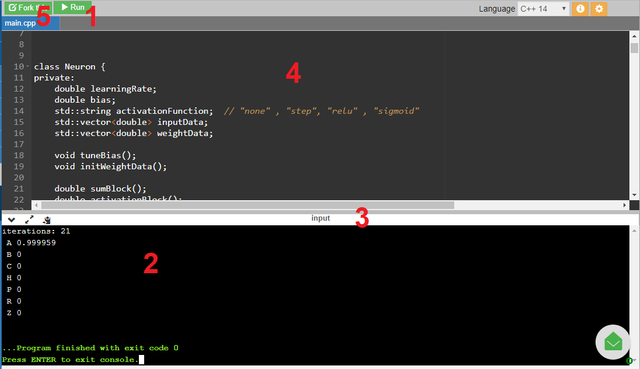
- Przycisk “Run” - wciśnięcie go rozpocznie kompilację kodu, pracę programu oraz prezentację wyników w konsoli
- Konsola - w niej wyświetlane będą wszystkie wyniki, warto zauważyć że posiada ona uchwyt, którym można zmienić rozmiar konsoli (np. dla wygodniejszej prezentacji wyników)
- Uchwyt do zmiany rozmiaru konsoli - przytrzymaj i przeciągnij go myszką, by zmienić rozmiar konsoli
- Edytor kodu - tutaj jest zawarta cała implementacja
- Przycisk “Fork this”- po jego wciśnięciu możesz edytować kod z 4.
Po prawej stronie 4. znajduje się suwak - użyj go lub rolki myszki, by zjechać w dół aż do linii nr. 207 (opcjonalnie, by znaleźć ten fragment kodu możesz użyć skrótu klawiszowego “ctrl+f” i w polu frazy którą szukasz wpisać “WEKTORY”)
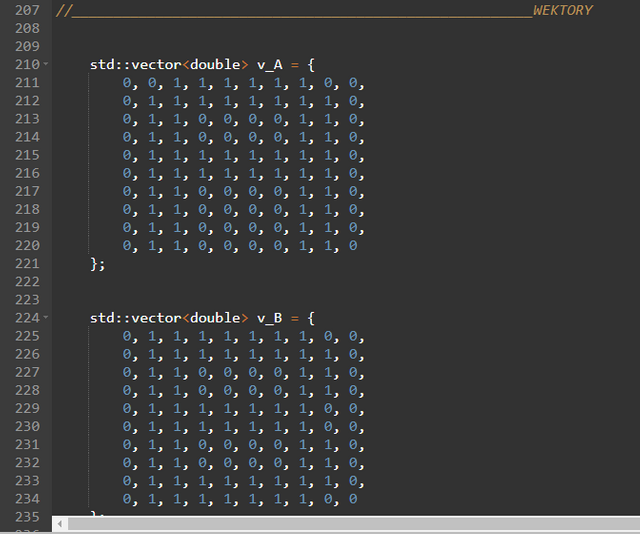
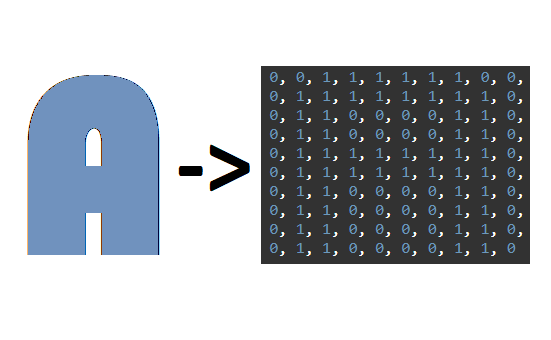
Załóżmy, że do klasyfikacji liter będziemy używać neuronu o stu wejściach, gdzie każde pojedyncze wejście symbolizuje jeden z pikseli obrazka.
W miejscu któremu się przyglądamy zawarte są dane wejściowe w formie wektorów o wymiarach 10x10, które będziemy podawać właśnie na wejście ww. neuronu o 100 dendrytach. Zauważ, że poszczególne cyfry 0 oraz 1 w każdym z wektorów układają się w pewnego rodzaju mozaikę. Umówmy się teraz, że cyfra 1 oznacza piksel litery, a cyfra 0 oznacza piksel tła - w ten prosty sposób możemy dokonać reprezentacji alfanumerycznej każdego symbolu graficznego.
Szablony poszczególnych liter wykonałem w sposób trywialny, ręcznie wprowadzając ciąg cyfr do wektora - w praktyce jednak powszechnie stosuje się parsery które formatują grafikę np. fotografię z pismem odręcznym, bezpośrednio do formy cyfrowej czyli właśnie np. takich opakowanych w wektory ciągów liczb jakimi posługujemy się w tym artykule.
W tej sekcji nie pozostaje nam nic innego jak wcisnąć przycisk “Run”  i zaobserwować wyniki otrzymane w konsoli.
i zaobserwować wyniki otrzymane w konsoli.
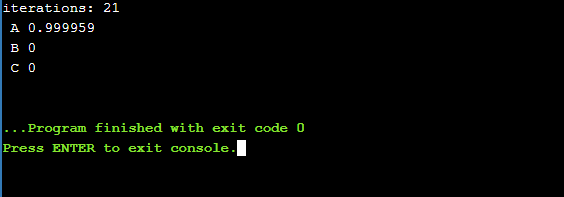
Pierwsza linijka w konsoli oznacza oczywiście liczbę iteracji treningu naszego pojedynczego przypadku litery “A”. Kolejne oznaczają wyniki pojawiające się na wyjściu neuronu dla poszczególnych danych (liter) w procesie pracy. Dla “A” otrzymujemy wynik bliski “1” (prawda), a dla wszystkich innych liter niebędących “A” wynik 0 (fałsz). Możemy więc powiedzieć, że klasyfikacja się powiodła (nie przejmuj się jeśli Twój wynik po przecinku delikatnie różni się od tego na screenie - jest to zupełnie normalne, ze względu na losową inicjację wag początkowych).
Sekcja testów
Okej, działa sobie - ale w nawet w tak prostej implementacji powinniśmy mieć przecież pewną kontrolę nad procesem uczenia.
Na początku wciśnij przycisk “Fork this”  w górnym lewym rogu okna (obok “Run”) - wciśnięcie ww. przycisku przełączy nas w tryb edycji, innymi słowy od teraz możemy wprowadzać zmiany w naszej implementacji.
w górnym lewym rogu okna (obok “Run”) - wciśnięcie ww. przycisku przełączy nas w tryb edycji, innymi słowy od teraz możemy wprowadzać zmiany w naszej implementacji.
Posługując się suwakiem zjedź prawie na sam dół aż do linijki 257: (opcjonalnie użyj “ctrl+f” z frazą “TRENING”)
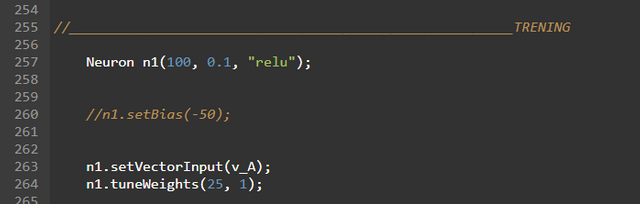
Neuron n1(100, 0.1, “relu”)To oczywiście inicjalizacja neuronu w programie, gdzie wartość 100 oznacza liczbę jego wejść, liczba 0.1 oznacza wartość współczynnika uczenia learningRate, a “relu” wybraną funkcję aktywacji wyjścia neuronu.

Na potrzebę tej implementacji nie będziemy zmieniać liczby wejść, ponieważ posiadamy próbki liter opakowane w wektory wymiarów 10x10, czyli posiadające 100 komórek - dokładnie tyle co neuron wejść. Z pełną swobodą możemy jednak edytować pozostałe wartości. Na początku zamieńmy fragment mówiący o wyborze funkcji aktywacji. Zastąpmy więc “relu” nazwą “sigmoid” (koniecznie z apostrofami “ “) i ponownie wciśnijmy przycisk “Run” by zaobserwować wyniki.
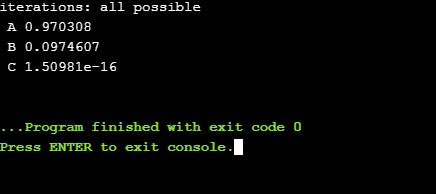
Zauważ, że w tym wypadku wzrosła nam liczba iteracji dla treningu, a jego jakość zdecydowanie spadła - dokładnie o tym mówiliśmy w #4, kiedy było powiedziane że funkcja sigmoidalna zbiega wolniej do żądanego wyniku w porównaniu do reLU. Wniosek jest dosyć prosty - użycie reLU daje lepsze rezultaty :-) Analogiczne obserwacje można wykonać dla funkcji skokowej, przez podanie frazy “step”.
Kolejnym elementem, który możemy modyfikować jest współczynnik uczenia learningRate.
Tak jak mówiliśmy w #2, delikatnie zwiększając jego wartość możemy przyspieszyć proces treningu.
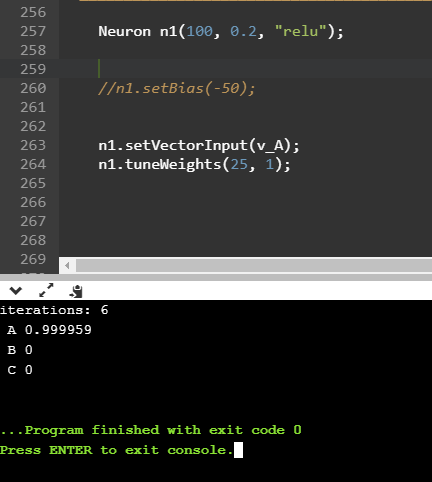
Z kolei po przekroczeniu pewnego odpowiednio wysokiego progu, algorytm klasyfikacji zupełnie się rozbiega - a my w efekcie otrzymujemy wyniki dalece odbiegające od oczekiwań.

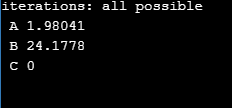
Ostatnią wartością, którą możemy “regulować” w tej prostej implementacji jest przesunięcie bias. Testy, których dokonywaliśmy przed chwilą dobierały go w sposób “automatyczny”(implementacja posiada prostą funkcję, która się tym zajmuje) - teraz jednak - by pokazać, że ten bias na coś jednak wpływ ma, będziemy go narzucać ręcznie. By włączyć manualną wersję regulacji bias’u przejdźmy do linijki:
// n1.setBias(-50);i usuńmy podwójny backslash “//” na początku tej linii przyłączając ją do kodu (podwójny backslash w wielu językach programowania, również w C++ jest oznaczeniem komentarza który nie jest częścią kodu). Zmieniając wartość znajdującą się między nawiasami, ustawiamy pewną wartość przesunięcia. Na początku ustawmy nasz bias na 0, a pozostałe wartości ustawmy jako learningRate 0.2, aktywacja “relu”.

W tym momencie powinniśmy otrzymać następujące wyniki:
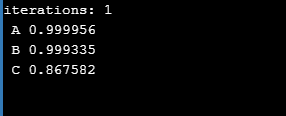
W tym przykładzie można zaobserwować, że bias jednak ma znaczenie - jego brak powoduje, że i owszem litera “A” jest ciągle rozpoznawana jako “prawda”, jednak pozostałe litery których wcale nie chcieliśmy klasyfikować w ten sposób, również są za nią w jakiś sposób uznawane!
Modyfikując wartość biasu (podajemy oczywiście liczbę ujemną, z minusem) możemy otrzymać właściwą klasyfikację, obcinając grupę błędnych wyników (sprawdź dla wartości np. -10 oraz -50).
Przeanalizujmy jeszcze kolejne dwie linijki implementacji:
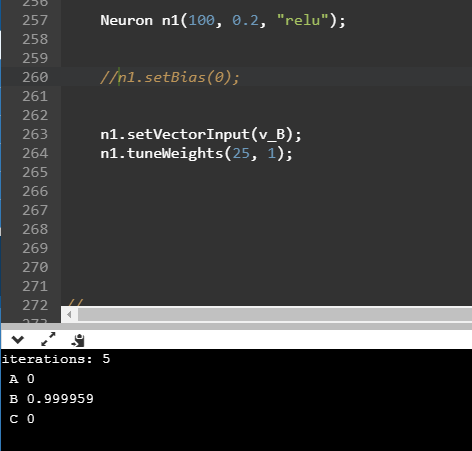
n1.setVectorInput(v_A); n1.tuneWeights(25, 1);Linie te oznaczają kolejno ustawienie wektora wejść dla neuronu, oraz proces treningu dla właśnie tego wektora. Liczba 25 oznacza maksymalną liczbę iteracji treningu, a cyfra 1 - nasze życzenie z, do którego chcemy dostroić synapsy by taki lub zbliżony wynik otrzymywać na wyjściu. Wybierając wektor podawany w ramach treningu, możemy przestroić nasz neuron do rozpoznawania dowolnej innej litery np. “B”.
Zakończenie
W najbliższym czasie, chciałbym poruszyć temat sekwencyjnego uczenia neuronu. Omawiając to zagadnienie, nie sposób nie powiedzieć o pierwszym napotkanym w tego typu sieciach problemie jakim jest katastroficzna amnezja neuronów.
Warto zaznaczyć, że ta prosta implementacja nie rozwiązuje tego problemu tzn. gdybyśmy chcieli nauczyć nasz pojedynczy neuron rozpoznawania kilku wariantów tej samej litery (np. w różnych czcionkach, lub rozmiarach), co więcej - każdą z propozycji podawalibyśmy seryjnie jedna za drugą - istniałoby ryzyko że neuron byłby zdolny do zapamiętania tylko ostatniego schematu, zapominając sobie o poprzednich. W najbliższym czasie przybliżymy sobie sposoby na rozwiązanie tego niekorzystnego zjawiska, co będzie swoistym wstępem do dynamicznego trenowania sieci.
Dziękuję za uwagę!
@callmejoe, I gave you a vote!
If you follow me, I will also follow you in return!
Enjoy some !popcorn courtesy of @nextgencrypto!
Congratulations @callmejoe! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
Click on the badge to view your Board of Honor.
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @steemitboard:
Congratulations @callmejoe! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Vote for @Steemitboard as a witness to get one more award and increased upvotes!