Uses of Elasticsearch, and Things to Learn.
 At Found, we see a lot of different use cases of Elasticsearch. We are often asked “What is your typical customer?”, however there’s no clear-cut answer beyond “Well, they’d rather spend time building stuff than operate a bunch of clusters!”. We see Elasticsearch used for lots of different awesome things, and a few crazy ones too!
At Found, we see a lot of different use cases of Elasticsearch. We are often asked “What is your typical customer?”, however there’s no clear-cut answer beyond “Well, they’d rather spend time building stuff than operate a bunch of clusters!”. We see Elasticsearch used for lots of different awesome things, and a few crazy ones too!
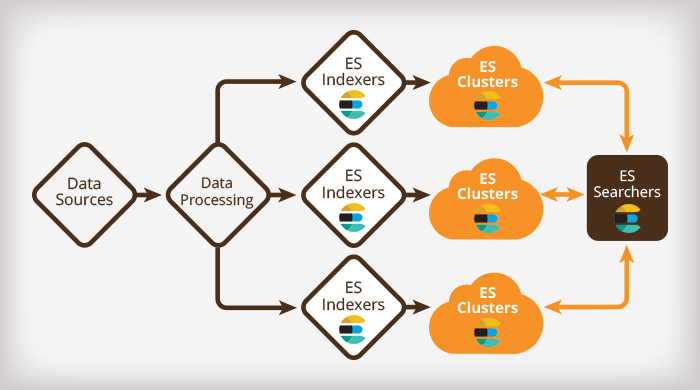
Elasticsearch is still fairly young, and our customers tend to start with Elasticsearch for a certain project, and then later pile on with more clusters for logging and analytics as well.
A common development evolution starts with building a simple search for a web site or a document collection. Then, perhaps faceted navigation is added, and spell checking or “did you mean?” responses. Maybe fuzzy searching is warranted, and auto completion, possibly even “search as you type”. Since relevancy is important, more advanced ranking schemes are likely to be added eventually — possibly based on who the user is, where she is, or who she knows. And of course, to know what the users actually do, usage must be logged — and metrics stored, so we know everything performs well.
You can use Elasticsearch for all of this, and more, but the different uses come with vastly different levels of complexity and resource requirements.
You Know, For Search! (And Counting!)
Unsurprisingly, Elasticsearch is often used to implement “search”, typically meaning there is an input box accompanied by a magnifying glass icon. What we mean by “search” can be ambigious in this case, so I will refer to different kinds of searches as e.g. “simple search”, “fuzzy search”, “aggregating” – simple meaning what you can achieve with a plain match-query.
It surprises many that simple searching is among the least resource intensive tasks you can ask of Elasticsearch. If all you require is the top ten results for a regular, non-fuzzy match query, you can sustain hundreds of searches per second on collections of tens of millions of documents on inexpensive hardware. However, when you add fuzzy searching or faceted navigation to the list of requirements, the CPU and memory needs increase a lot.
Modern search interfaces are generally expected to have some sort of faceted navigation, i.e. where a user can get a quick understanding of the distribution of the search results. How many books are of a particular author, in a certain price range, with a certain rating? These are implemented using aggregations in Elasticsearch, and they come in many forms. You can aggregate on terms, numerical ranges, date ranges, geo distance, and a lot more.
It’s counter-intuitive to many that sifting through millions of documents to find matches is somehow less of an effort than counting and aggregating the matches in various ways. Nevertheless, compared to the information retrieval problem “Which ten documents match (and are most relevant for) these conditions?”, aggregating is expensive. When scoring to find the best documents, Lucene will use tricks like “This set of documents do not match everything these other documents match, so they cannot possible be the best, so just skip them.” When filtering, Elasticsearch will utilize the filter cache a lot. Elasticsearch and Lucene are great at avoiding work when it can, but with aggregations, they need to count all the matching things all the time.
In Elasticsearch from the Bottom Up we cover how the inverted index works, and how the dictionary and posting lists are used to perform a simple search. This and our articles on text analysis should make it clear why processing text correctly is very important when working with search. Sizing Elasticsearch and Elasticsearch in Production both detail what kind of memory usage you can expect.
Analytics
Analytical workloads tend to count things and summarize your data — lots of data, it might even be Big Data, whatever that means! These rely on Elasticsearch’s aggregations, and the aggregations are often generated by tools like Kibana.
We have already mentioned that these aggregations can be quite expensive, both in CPU and memory. The demands on memory are big as Elasticsearch needs to rapidly look up a value given a document, which involves loading all the data for all the documents into memory in a “field cache”. This can be alleviated by using “document values”, which need to be enabled in your mapping before you index documents.
Furthermore, analytical searches often run on timestamped data, which it can make sense to partition into e.g. daily or monthly indexes. Having one index per time unit makes it easy to reduce your search space, and clean up and archive old data.
Fuzzy Searching
A fuzzy search is one that is lenient toward spelling errors. To give an example, you can find Levenshtein when searching for Levenstein. Our article on Fuzzy Searches offer more details on how to use fuzzy searches, and how they work.
Fuzzy searches are simple to enable and can enhance “recall” a lot, but they can also be very expensive to perform. By default, a term in the input can be rewritten to an OR of 50 terms per field, which combined with multi_field can cause quite the combinatoric explosion of terms in the resulting rewritten query.
It is always important to test changes and improvements to your searches with realistic amounts of data before shipping them to production. This is particularly true when adding the fuzziness parameter. It’s an easy option to enable, but it will make your searches several orders of magnitude more expensive.
Fuzzy searches are CPU-intensive. Add them with care, and probably not to every field.
Autocompletion and Instant Search
Searching while the user types comes in many forms. It can be simple suggestions of e.g. existing tags, trying to predict a search based on search history, or just doing a completely new search for every (throttled) keystroke.
There are a lot of different features in Elasticsearch to assist building these features, such as prefix queries, match_phrase_prefix, indexing ngrams, and a family of different suggesters.
Searches like this are very sensitive to latencies. The threshold of what no longer feels “instant” is generally considered to be 100 milliseconds. Searching for almost every keystroke also means quite a higher search throughput as well. Thus, it’s essential that the searches are cheap and that these indexes fit in memory.
Autocompleting searches while also showing the results for the most likely completed search, much like how Google does it, should be considered as two separate search problems. The amount of data to be searched when autocompleting previous searches is probably a lot less than the content being searched, which makes keeping it all in memory and serving fuzzy searches more feasible. Since an autocomplete search will see a lot higher search load than the full search, keeping the two separate makes it possible to scale them separately as well, possibly in completely separate Elasticsearch clusters.
When Soundcloud revamped their search experience, they worked a lot on search suggestions. Implementing it well, they not only saw an increase in search precision, but also a noticable reduction in load on the infrastructure powering the full search. What people search for often follows a Zipf distribution: typically, 10% of the unique searches account for 90% of the search volume. Thus, it’s very likely that the full results for the best search suggestion is already cached (in your application layer), and can be displayed “instantly”.
A lot of the engineering behind Soundcloud’s search suggester is what lead to Elasticsearch’s suggester features. There is an excellent presentation by Muir and Willauer on Query Suggestions with Lucene that is worth watching to learn more.
Multi-Tenancy
Often, you have multiple customers or users with separate collections of documents, and a user should never be able to search documents that do not belong to him. This often leads to a design where every user has his own index.
More often than not, this leads to way too many indexes. In almost every case we see index-per-user implemented, one larger Elasticsearch index would actually be better. There are significant downsides to having a huge number of small indexes:
The memory overhead is not negligible. Thousands of small indexes will consume a lot of heap space. The number of file descriptors can also explode.
There can be a lot of duplication. Consider how the inverted index works, and how Lucene writes and compresses things in segments.
Snapshot/Restore is currently a serial process, with an overhead per index. Snapshotting thousands of tiny indexes take an order of magnitude longer than snapshotting a few large indexes.
In Sizing Elasticsearch, there is more information about sharding and partitioning strategies, with quite a few more references. Fixing an application with suboptimal index design can take significant effort, so understanding the different approaches is well worth its time.
You probably should not make one index per user for your multi-tenant application.
Schema Free / User-Defined Schemas
Related to having multiple individual customers, we also see a lot of use cases where different users can have completely different documents. For example, if you are providing user surveys/questionnaires as a service, it’s likely that different surveys have completely different fields.
Often, this leads to using Elasticsearch’s “dynamic mapping”, sometimes advertised as Elasticsearch being schemaless. However, Elasticsearch will create a mapping for you behind the scenes, and it can be problematic when this grows too big, leading to a “mapping explosion”. Instead, it’s important to make sure that values in a document also end up as values — and not separate fields. This is explained a bit more in “Key/Value Woes”, and in Schemalessness Gone Wrong
Elasticsearch has versatile mapping capabilities, with index templates, dynamic templates, multi fields and more. Use them!
Even when not using a mapping, know what mapping Elasticsearch creates for you.
User-Defined Searches
Related to user defined schemas is often the need to let end users define their own searches, with custom filters, scoring and aggregations. One common approach is to limit the search request to certain indexes, and/or wrap the users query with filters.
Even when doing so, there are several ways that a user can wreak havoc when custom search requests can be defined, such as expressing searches that are CPU-intensive, memory hogging or cause Elasticsearch to crash. These topics are covered in Six Ways to Crash Elasticsearch and Securing Your Elasticsearch Cluster.
Be careful with user-defined search requests.
Crawling and Document Processing
There are many ways to get your data into Elasticsearch.
A river is an Elasticsearch concept where Elasticsearch pulls data from a source, like a database through JDBC, a message queue, a Twitter stream or by crawling web sites. They are quite simple to get started with, but the approach quickly proves challenging to scale and to operate in production. As such, rivers are deprecated, and one should look to solve these problems outside Elasticsearch. Logstash keeps gaining support for more systems and can replace a lot of rivers. For custom applications, there are enough challenges when syncing data to Elasticsearch and preparing Elasticsearch documents that something simple and generic like rivers should not be expected to be sufficient. For crawling, people are using both Scrapy and Nutch together with Elasticsearch.
Related to this is the processing and conversion of documents like Word documents or PDFs to plain text that Elasticsearch can index. There is a “mapper-attachments” plugin which can be used to do this conversion within Elasticsearch. However, while the attachments plugin is convenient, we recommend doing the document conversion before sending the documents to Elasticsearch. This gives you the greatest control of how the documents are converted and refined. Document conversion like this is typically one of the first steps during “content refinement”’s “document/text processing pipeline”. The documents you send to Elasticsearch should be the result of this “content refinement/preparation” – leaving Elasticsearch to do the final text processing and indexing. Document conversion is quite CPU-intensive, but easily parallelizable. It is preferable to let Elasticsearch spend its time on indexing and searching, and let “upstream” clients do the document conversion.