Word2vec from scratch in Python
Word2Vec is a method used for creating word embeddings. Word embedding is a feature engineering technique used in NLP where words or phrases from a vocabulary mapped to a vector of real numbers. Word2Vec have two different methods, continuous Bag of Words (CBOW) and Skip-gram method. We can use any one of them and create our word embeddings.
CBOW: predicting the word given its context/surrounding words.
Skip-Gram: Predicting the context from the given word.
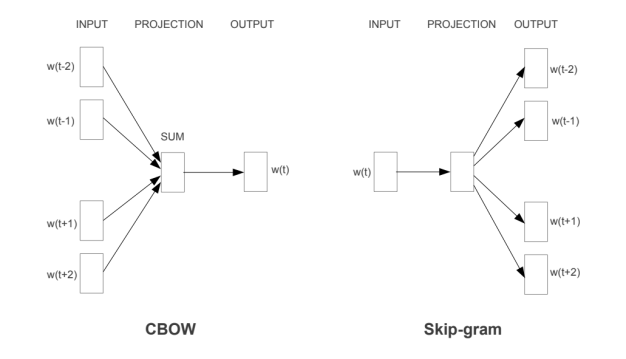
the figure https://arxiv.org/pdf/1301.3781.pdf
Skip Gram model: In skip-gram, the current word is taken as Input and predicts words within a certain range before and after the current word.
Example: Ashraf Marwan is remembered most famously for spying for the Egyptian intelligence agency.
After removing the stop words and all in lowercase:
ashraf marwan remembered famously spying egyptian intelligence agency
If we take the certain range 2, also called WINDOW_SIZE
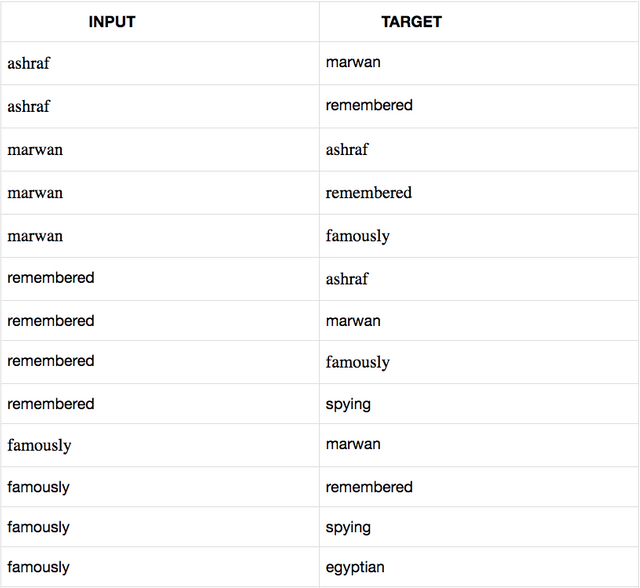
There are three main steps for training word2vec
- clean the text documents, pre-processing.
- converting the input and target into one hot vector using vocabulary.
- creating a shallow Neural network and train it.
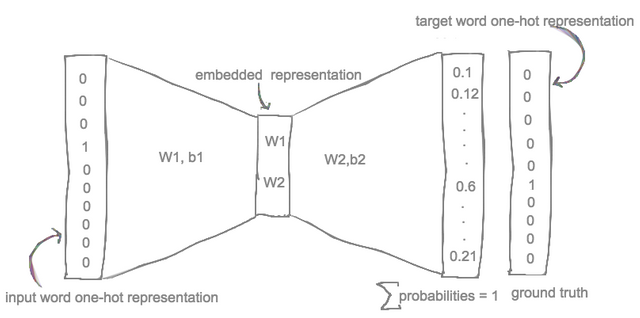
All the above steps and code are explained here: https://aquibjk.wordpress.com/2018/10/03/word2vec-analysis-and-implementation/
Congratulations @aquib! You have received a personal award!
Click on the badge to view your Board of Honor.
Do not miss the last post from @steemitboard:
Congratulations @aquib! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Do not miss the last post from @steemitboard:
Vote for @Steemitboard as a witness to get one more award and increased upvotes!