[저 세상 정리] MIT 6.S191 1강
[저 세상 정리]는 내 맘대로 이해한 강의 내용을 내 맘대로 정리하는 post이므로 매우 부정확할 수 있음
MIT 6.S191 Introduction to Deep Learning #1
S191 수업은 딥러닝의 다양한 알고리즘을 소개하고 그 알고리즘들이 어떻게 작동하는지, 그리고 왜 작동하는지에 대해 다룰 것이다.
첫 수업에서는 다음과 같은 주제를 다룬다.
1. What is Deep Learning?
2. Why Deep Learning and Why Now?
3. The Perceptron
4. Building Neural Networks with Perceptrons
5. Applying Neural Networks
6. Training Neural Networks
7. Neural Networks in Practice: Optimization
8. Neural Networks in Practice: Mini-batches
9. Neural Networks in Practice: Overfitting
이제 하나 하나 살펴 보도록...(귀찮..)
수업 자체가 딥러닝 입문에 관한 수업이니 만큼 우선 딥러닝이 무엇인지 부터 설명한다. 딥러닝이란, NN(Neural Networks)을 이용하여 데이터의 내재된 특징(underlying features)을 '다이렉트로' 학습하는 기법이다. 그렇다면 왜 데이터의 특징을 다이렉트로 배우는 것이 좋은가, 혹은 필요한가? 딥러닝 이전에는 인간이 데이터를 가공하여 feature를 만들었는데, 이러한 방식의 단점은 실제로 사용하기에 시간이 많이 걸리고(time consuming) 안정적이지 않으며(brittle) 확장성이 떨어진다(not scalable). 결론은 딥러닝..
딥러닝의 개념을 말로는 대충 알겠으니 딥러닝 모델이 실제로 어떻게 생겨먹었는지 보도록 하자. 위에서 딥러닝의 개념을 설명할 때 NN을 이용한다고 했다. 이 NN의 가장 기본이 되는 유닛이 perceptron이라는 놈인데, 인간 신경세포(neuron)의 기계 버전이라고 생각하면 된다. 뉴런은 어떤 자극 혹은 정보(input)를 받으면 일련의 과정을 거쳐 화학 물질(output)을 분비해 다음 뉴런으로 정보를 전달한다. Perceptron도 똑같다. 정보(input)가 들어오면 일련의 과정을 거쳐 결과물(output)을 생성한다. 다음 그림을 한번 보자.
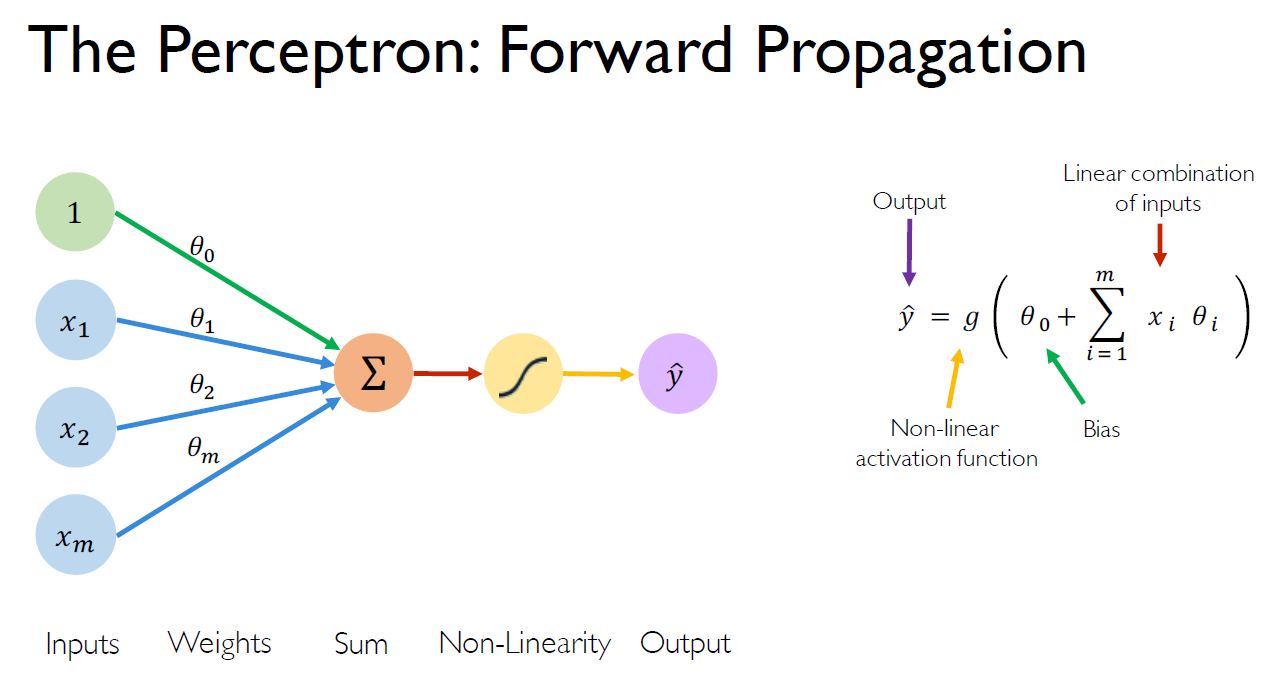
퍼셉트론의 작동 방식은 간단하다. input data x_1, ... , x_m에 해당 가중치(theta)를 곱하여 더하고(weighted sum), 이 결과물에 비선형성(non-linearity)을 주기 위해 activation function을 적용한 것이 최종 output이다. 여기서 bias의 역할은 input data로 모두 0이 들어와도(=input data가 없어도) activation function의 input으로는 0이 아닌 수가 전달되도록 한다. Activation function의 input으로서 0의 의미란..? 결론부터 말하면 임계치다. Activation function의 input이 양수(음수)이면 다음 perceptron에 더 강한(약한) 자극을 주기 위해, 즉 더(덜) activate하기 위해 큰(작은) 값을 전달한다.
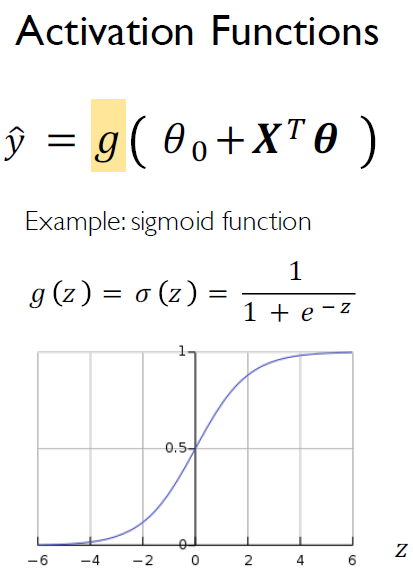
Simoid는 많이 쓰이는 activation function 중 하나이다. Sigmoid는 input 값을 0~1 사이의 값으로 mapping한다. 이는 확률로도 해석할 수 있으며 input 값 0을 중심으로 0.5 이상 혹은 이하의 값(확률)을 반환한다. Sigmoid와 마찬가지로 다른 activation function도 0을 임계치로 갖는다.
다음은 activation function의 비선형성에 대해 얘기하려 한다. Activation function의 진짜 존재 이유는 network에 비선형성을 주기 위함이다. Network에 비선형성을 뭐라고..? 직관적으로 와닿지 않기 때문에 그림을 통해 설명한다.
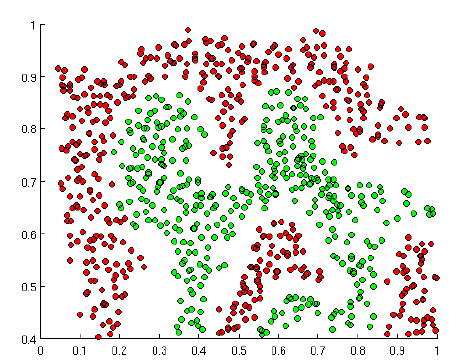
위의 초록점과 빨간점을 구분하는 NN을 설계하려고 하는데... 하나의 직선으로 나눌 수 있을까? 대답은 ㄴㄴ....
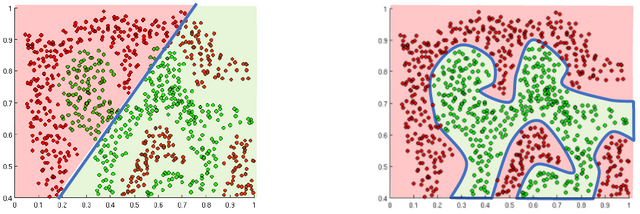
만약 activation function이 선형이라면, NN의 결과는 왼쪽 그림과 같을 것이다. Activation function의 비선형은 NN이 오른쪽 그림 처럼 구분하도록 할 수 있다. 즉 비선형은 network가 복잡한 함수에 근사할 수 있도록 한다!
Perceptron도 대충 알았으니 NN을 만들어보자!
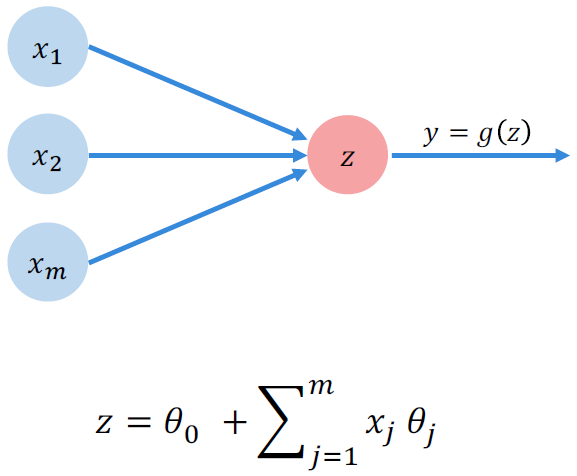
Peceptron은 위와 같이 간소화하여 표현될 수 있다. 이를 응용하여 두 개의 output을 내는 구조를 만들어 보면?
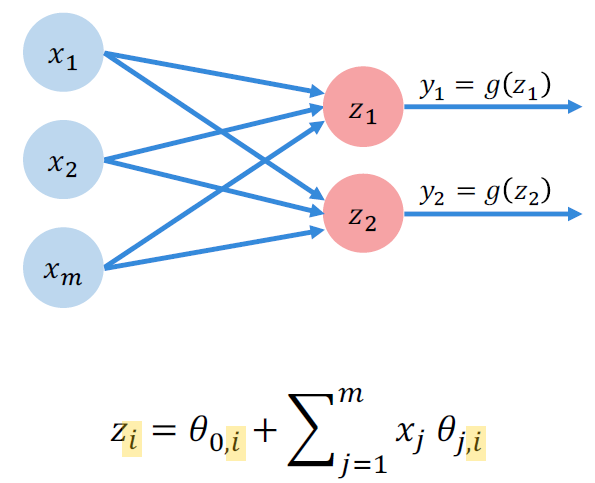
더 이어 붙여보도록 하자.
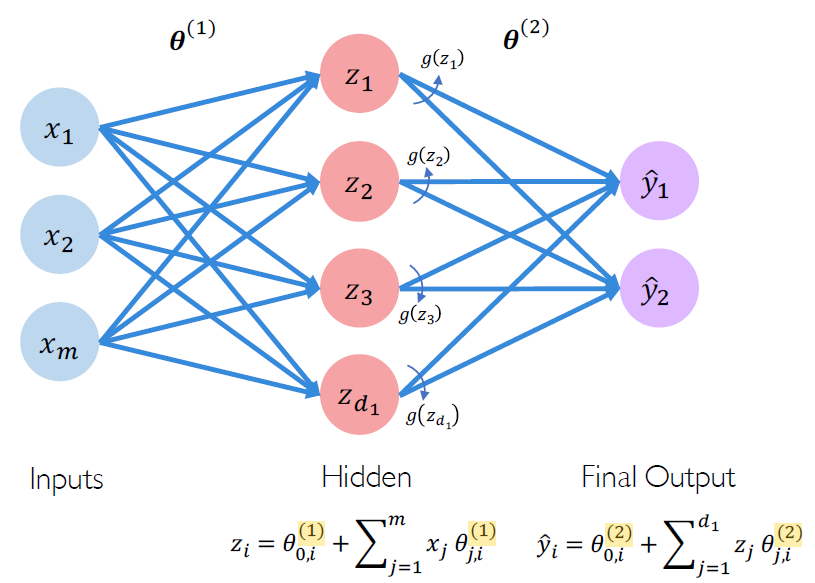
복잡해 보이지만 전혀 그렇지 않다. 단지 perceptron의 연장선일 뿐이다. 다음 그림을 보면 이해가 쉬울 것이다.
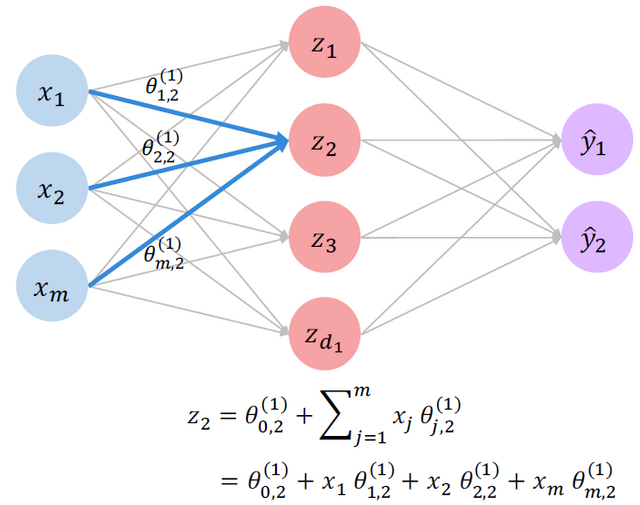
y로 향하는 화살표 또한 동일하다.(참 쉽죠?) 만약 layer를 더 쌓는다면?
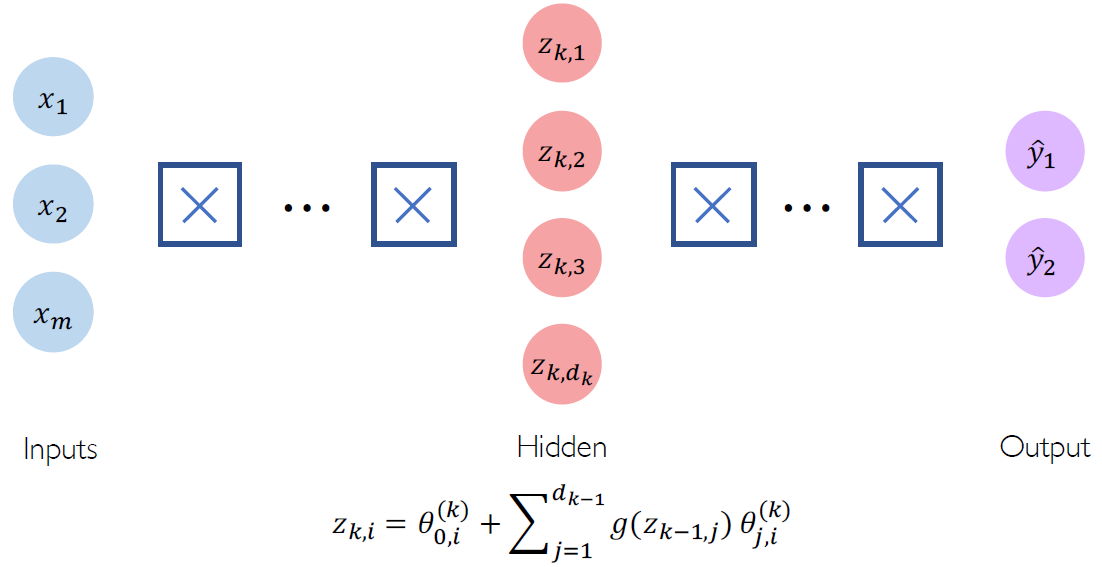
DNN(Deep Neural Network)가 완성되었다. 구조가 복잡해져도 기본 구조는 하나의 perceptron이라는 것을 잊지 말자. dot product와 non-linearity의 연속..
NN을 만들어봤으니 어떻게 사용하는지 알아보자. 다음 문제에 NN을 적용할 것이다.
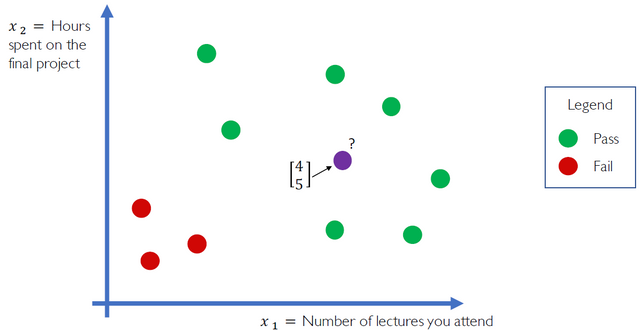
x_1축은 수강중인 수업의 수, x_2축은 final project에 쏟은 시간, 초록점은 수업 pass, 빨간점은 fail.. 그럼 새로운 데이터 보라점은 pass일까 fail일까? 우리의 NN에게 판단을 맡겨본다.
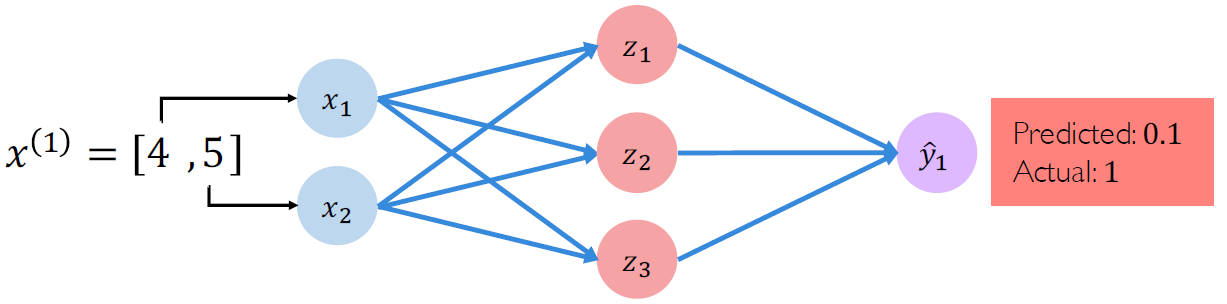
결과는 0.1을 예측했고 실제 값인 1과는 거리가 있어 보인다. 이렇게 예측 값과 실제 값의 차이를 loss라고 하는데, loss의 정량화(quantifying) 표현은 다음과 같다.
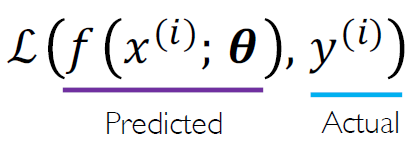
이는 하나의 데이터에 대한 loss를 나타낸 것인데 전체 데이터에 대한 loss 또한 단순 합이나 평균을 통해 다음과 같이 구할 수 있고 empirical loss라 한다. 같이 쓰이는 말로는 objective function이나 cost function 등이 있다.
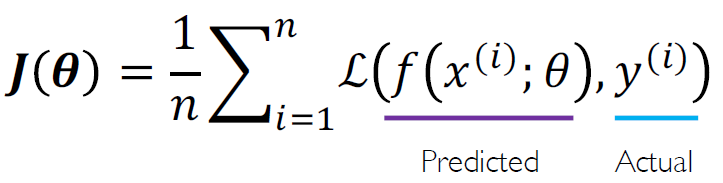
많이 쓰이는 cost function 2개를 소개한다.
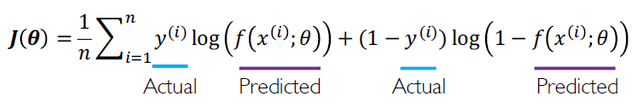
Cross entropy loss는 확률 값을 output으로 내는 모델에서 사용할 수 있다.
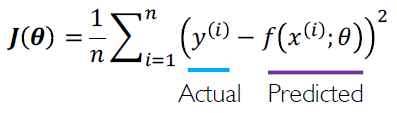
Mean squared error loss는 regression 모델에서 사용할 수 있다.
이러한 loss 계산은 NN을 학습시키는데 필수적이다. Loss를 최소화 시켜야만 옳은 output을 기대할 수 있기 때문이다. 그렇다면 loss는 어떻게 최소화될 수 있는가. 위에서 예측 값과 실제 값의 차이를 loss라 했다. 실제 값은 달라지지 않으므로 loss를 줄이려면 실제 값에 가깝게 예측 값을 계산해야 한다. 다시, 예측 값은 어떻게 계산되는가. 어렵다면 perceptron으로 가정하고 생각하면 쉽다. input의 weighted sum, 그리고 activation function. 여기서 가변적인 것은 weight뿐이므로 실제 값과 가깝게 예측 값을 만드는 weight를 찾아야 한다. 설명은 길었지만 다음 식으로 간단히 할 수 있다.(위의 loss 식들이 모두 network weights의 식인 이유는 이때문이다.)
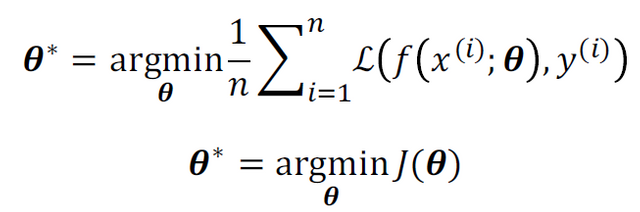
Loss를 최소화하는 weight를 찾는 방법, 즉 loss optimization에 대해 알아본다. 다음 그림은 cost function을 간략히 2개의 weight로 이루어진 함수라 가정하고 시각화하여 optimize하는 과정을 나타낸 것이다.
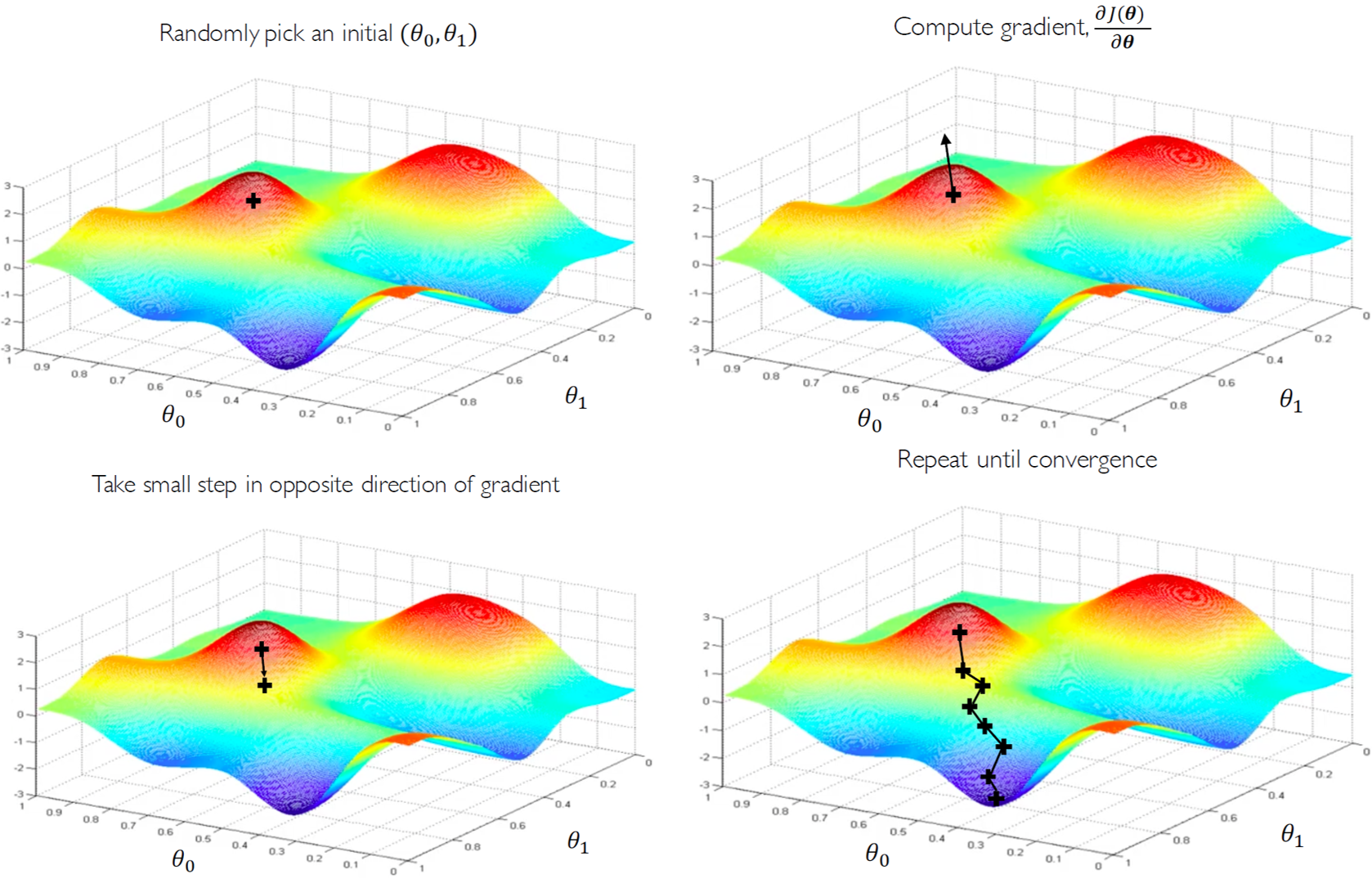
세로축이 cost function의 값이므로 가장 낮은 지점을 찾아가는 과정이다. 이를 알고리즘으로 표현하면 다음과 같다.

이러한 방법을 gradient descent algorithm이라 한다. 여기서 4번을 자세히 보자. 구해진 gradient에 η(에타)를 곱하여 사용하는데 η의 값에 따라 weight가 크게 혹은 적게 바뀔 수 있다. 이러한 의미로 η를 learning rate라 한다. 이η을 '적당한' 값으로 설정해 주는 것이 굉장히 중요하다. 너무 작은 값으로 설정하면 천천히 어떤 값으로 수렴(converge)해가는데 그 값이 우리가 찾아야하는 global minima가 아니고 local minima일 수도...(함정카드). 반대로 너무 큰 값으로 설정하면 weight가 크게크게 바뀌어서(unstable) 발산(diverge)하는 문제를 갖는다. 그럼 도대체 어떻게 그 '적당한' 값을 찾을 수 있을까..
Idea 1. 노가다... 되는대로 다 실험해보고 '적당한' 값 결정
Idea 2. 상황에 따라 변하는 adaptive learning rate를 설계할 수는 없나? 해보자!
똑똑하신 분들이 이미 다 만들어 놓았다. Learning rate는 더이상 고정된 수가 아니라 gradient, 학습 속도, 특정 weights에 크기 등에 따라 변할 수 있다. 이런 adaptive learning rate algorithm의 종류에는 Momentum, Adagrad, Adadelta, Adam, RMSProp 등이 있다.
하지만 gradient descent algorithm에 치명적인 단점이 있다. 바로 gradient를 계산하는 비용이 너무 크다는 것이다. 왜? 애초에 cost function이 모든 데이터에 대한 loss를 뜻하기 때문에 데이터가 많다면 한 iteration에 대한 비용이 클 수 밖에 없다. 이에 대한 대안으로 SGD(Stochastic Gradient Descent algorithm)이 있다. 다음 그림을 보자.

전체 데이터 중 B개의 데이터를 대상으로 gradient를 계산하여 비용을 줄이는 알고리즘이다. SGD의 loop 한 번이 GD의 loop 한 번과 같은데, GD에서 계산된 gradient와 SGD에서 계산된 gradient는 당연히 차이를 보일 수 밖에 없지만 SGD의 gradient를 GD의 추정치로 사용하는데에는 문제가 없다.
이렇게 NN의 학습이 완료되었다(?). 이제 학습 완료된 모델의 generalization problem에 대해 알아본다.
우선 overfitting problem

머신러닝 혹은 딥러닝에서 모델을 학습하는 궁극적인 이유는 test data를 우리의 의도대로 잘 표현하기 위함이다. 다르게 말하면 우리가 만든 모델이 training data로부터 패턴을 학습하고 모델에 아직 보여지지 않은 test data에 대해서도 일반화가 잘 되길 원한다. 위의 그림에서 ideal fit의 상태처럼 선을 그어 점들을 나누고 싶은데 underfitting의 경우 모델의 complexity가 충분히 높지 않을 때 발생할 수 있고 overfitting의 경우 complexity가 너무 높아 training data를 기억할 때 발생한다. 두 경우 모두 test data에 대해 제대로 generalized 되지 않는다.
이러한 문제를 해결하기 위해 regularization 방법을 많이들 사용한다. 이 방법을 사용하면 모델이 너무 complex해지는 것을 방지할 수 있다. Regularization의 방법 중 하나로 dropout이 있다. 다음 그림을 보자.
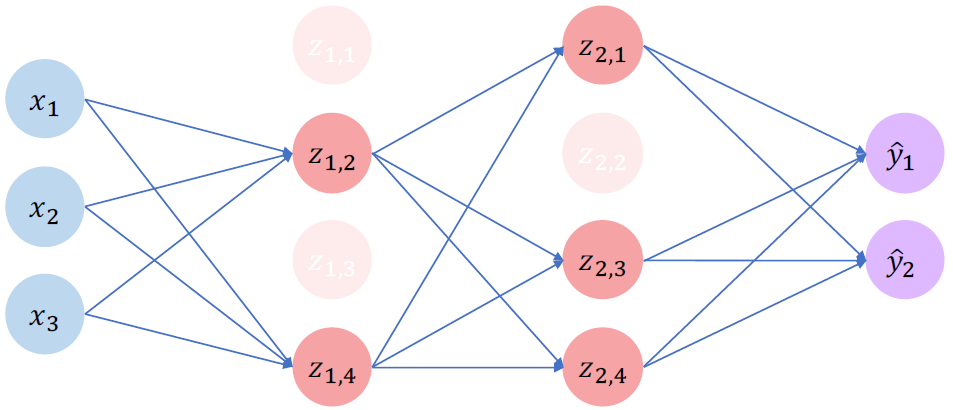
Training 과정 동안 임의로 몇 개 뉴런의 activation을 0으로 만드는 방법이다. 다시 말하면, 몇 개의 뉴런을 '사용 중지' 상태로 만드는 것이다. 이 방법을 쓰면 network가 하나의 뉴런에 크게 의존하지 문제를 방지한다. 일반적인 usage는 한 layer에서 50%의 뉴런만 유지되며 매 iteration마다 유지되는 뉴런은 바뀐다.
두 번째 방법으로는 early stopping이 있다. 이 방법은 overfitting이 발생하기 전에 training을 강제로 마치는 방법이다.
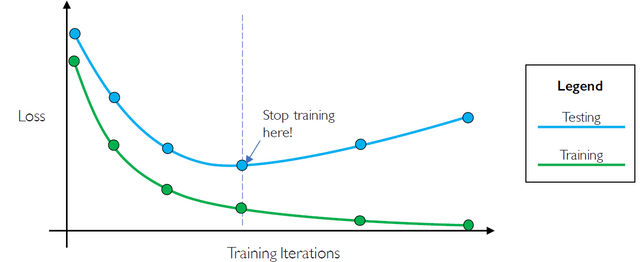
1강에 대한 정리는 여기까지...
2강 듣는대로 정리한드아..
@yskoh, welcome and congratulations on making your first post! I gave you a $.05 vote! If you would be so kind to give me a follow in return, that would be most kind of you!!
Resteemed your article. This article was resteemed because you are part of the New Steemians project. You can learn more about it here: https://steemit.com/introduceyourself/@gaman/new-steemians-project-launch
Congratulations @yskoh! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOP