Machine Learning, Function Induction, and Differentiability
Machine Learning!
I see machine learning (at least supervised learning) as "function induction."
Let me explain what this means...
A mathematical function is a mapping from one set to another.
This is a very universal concept...Imagine that your "domain" (input set) is the set of all pictures and your "range" (output set) is the set of all object labels you want to keep track of (like "human", "dog", "cat", "other"). If you could find the function which maps pictures to labels, then that's the holy grail of image classification!
Supervised learning (as far as I see it) is the task of finding the function which maps inputs to outputs for arbitrary sets of data.
Now this is technically impossible to do perfectly since you can never be certain what the true pattern is that created a data set with finitely many data points.
For instance, fill in the blank...
1, 2, 4, 8, 16, ___
If you thought the answer was 32 you'd be wrong!...ACTUALLY the pattern was "double the previous number, except the sixth number is 1."
So now you're probably saying, "Hey! That's not fair! That's not a REAL pattern!", but it IS a function...and some functions are arbitrary...so...

So you now should see that function induction must always require some assumptions about what "types" of functions are "allowed". The space of such functions we are considering is called the "version space" and it varies based on the specific "learner" you use. They all have inherent biases.
That being said...my favorite is the Neural Network.
A great tutorial on it can be found here:
http://neuralnetworksanddeeplearning.com
(I hope to post a short tutorial on this soon as well)
What I want to show in THIS post relates to the inherent biases of almost all learners.
You can also think about finding the solution to a supervised learning problem as an optimization problem in terms of the error. What I mean by this is that you can pick a "candidate" function and then try to minimize the error between it's classifications and the true labels. We can (in theory) graph error as a function of learner parameters and use methods such as Gradient Descent to find the optimal points in "parameter-space" which yield a perfect classifier!
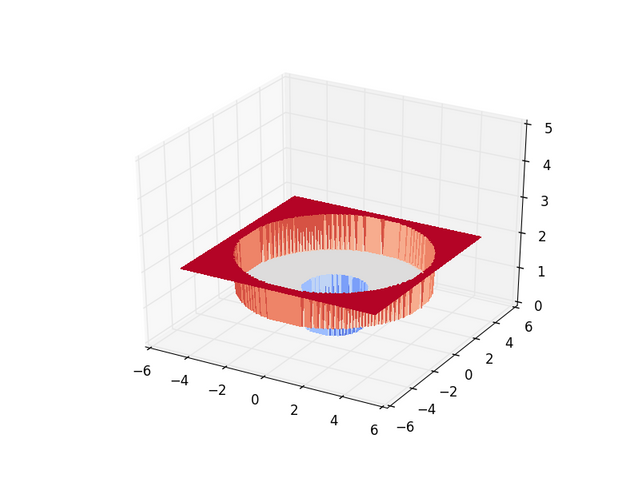
Gradient descent only works well if you can tell how error will change when you change parameters by a small margin...this is not always the case... As a thought expiriment, let me leave you with the following graphs where the x and y axes are parameters of some learner and the z-axis is the error in classification. They are listed in the order of increasing difficulty for most learners to learn...for the most part...
Perfection
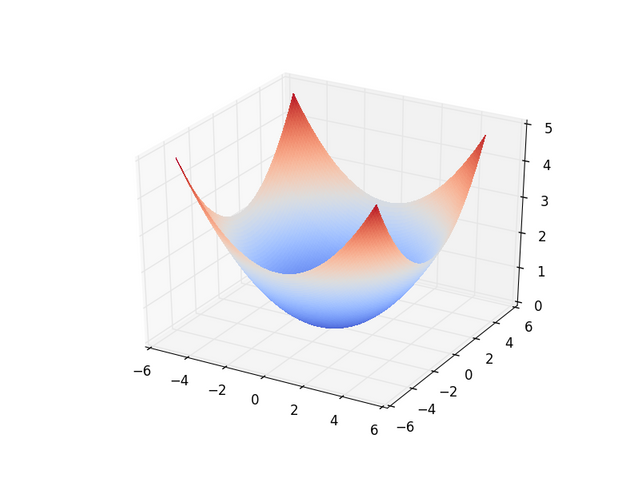
Some Global Signal
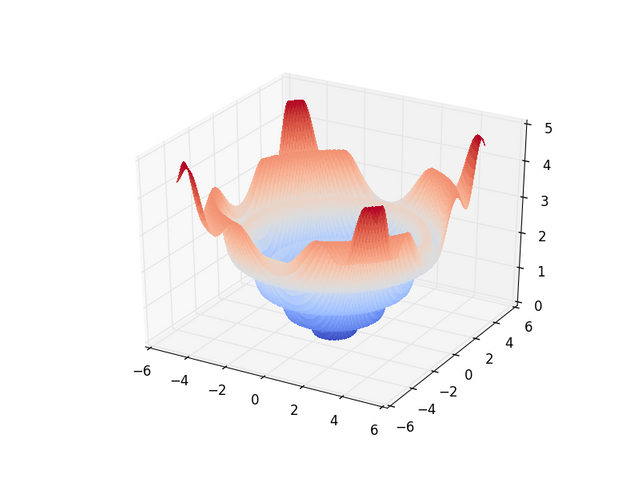
Only Local Signal

No Local Signal
Useful info and I like it
@steemcleaners ...This is how you do this right?
Looking forward to the tutorial on the neural network. This was a great overview, though I don't totally understand it all that well I'm checking out some videos on gradient descent with python to try to get a better idea.
Thanks! I'm glad you liked it! I just posted a post on neural networks...just what the model is, not gradient descent yet...but I hope you like it and let me know if you have any questions about neural networks!
https://steemit.com/mathematics/@jackeown/introduction-to-machine-learning-the-neural-network