Machine Learning...and the Apocalypse?

Someone obviously didn't read the Q-Tips warning labels!
Trying to learn everything that goes along with Data Science in the span of 6 months can be a daunting task. Where do you begin? How in depth can you really get? Can I learn it all?
The Data Science master’s program director and lead professor at the University of Dundee work hard at answering these questions as best they can for myself and my classmates. While both have worked in the data science field commercially for a number of years, written numerous books and articles about databases, MDX, programming, deep learning, etc., they didn’t just rely on what they personally felt to be the most important aspects to teach their students. What they actually did was contact directors of data science at companies, CEOs, etc. and simply said…”You are going to want to employ our graduates. What do you expect them the know and be able to do?”
I'm slightly over simplifying it, but essentially that is what they do. They do this on an annual basis to adjust the program and the modules appropriately. I appreciate this approach as it keeps the program relevant, up-to-date, and I’m learning skills that employers are actually looking for.
That doesn’t go without saying, that sometimes, some aspects may be glanced over. For me, that concept was Machine Learning. Sure we talked about it, but not in great depth. We even got philosophical with trying to define machine learning, artificial intelligence, and can machines really “think” on their own. I believe one day, we will see computers using their "intelligence" to make unsupervised decisions. We also jokingly talked about how it may lead to the apocalypse when eventually the machines start deciding to take over the world. Hence we named our short lecture for that day “Machine Learning and the Apocalypse”.

Well, maybe not in my lifetime.
I just recently talked to the director, and they recognize machine learning's growing importance and they are revamping the modules for the next academic year. Which means for me, I started a year too early in the program.
But that’s ok. I mean isn’t one of the aspects of earning a Master’s degree to do independent learning and research? And to dive into those aspects driven by curiosity?
So that’s what I’m doing.
I randomly came across this website called Datacamp. There I found a tutorial about Machine Learning using baseball statistics. I love sports and baseball. I'm completely engaged in these data science concepts...and I suppose you could say my “dream job” once I finish this master’s in January would be to work for a professional sports organization to apply these data science skills. I was immediately drawn to this tutorial and had to try it.
I won’t bore you too much with the coding. But if you are curious, you can read through the tutorial to get the gist of it here https://www.datacamp.com/community/tutorials/scikit-learn-tutorial-baseball-1#gs.Te1=zxs
This is my first attempt (I loosely say 'first' because I tried it a bit before with an assignment, but didn't get very far with it as I was still trying to grasp the concept) at doing some machine learning on my own.
I input over 100 years of each baseball team's statistics...so each team, for each season, going back to 1900, from a database into a statistical program (Python). I could train the program to develop an algorithm to determine the relationship between all those statistics (runs scored, hits, doubles, triples, HRs, walks, fielding percentage, errors, home-runs allowed, strike outs, etc) and make a correlation to overall games won for that team, for that year.
However, I altered the original code, in that I was curious if I could input the current statistics as of August 2nd, 2017 to predict the end of the year wins for each team (where as the way the tutorial is set up, would predict the wins up until the date the statistics were taken. So if a team played 162 games, it predicted wins out of those 162. If a team only played 100 games, it predicted the wins from those 100 total games. Thinking about it now, I suppose I could have used the winning percentage to calculate out the total wins in 162 games, and test if it was more accurate than the modeled results below).
Once the model is trained on the modified code, I could then input the teams' statistics as of August 2nd for this current season to predict how many wins they will have at the end of this season. There's 2 more months of baseball left until the playoffs. So I'm posting this up here now so we can go back to see how close I got (and if it ends up being really close, I won't be accused of changing the results to my favor).

There needs to be a method to the madness. Stirring would be a poor choice.
But before inputting the new data, you need to test the model with known results. I mean, what good is a model if's not accurate? When I tested my model with known results, on average, it was predicting the wins +- 2.7 from actual wins. I'm sure I could tweek, maybe add more variables, to reduce that variance. I also had not checked the distribution or standard deviations. Had this been an assignment, I obviously would be more thorough in testing the model. But like I said, this was my first attempt and I was more focused on if I could get it to work, not necessarily analyzing the accuracy...but an average of +-2.7 was not bad for a one days attempt....
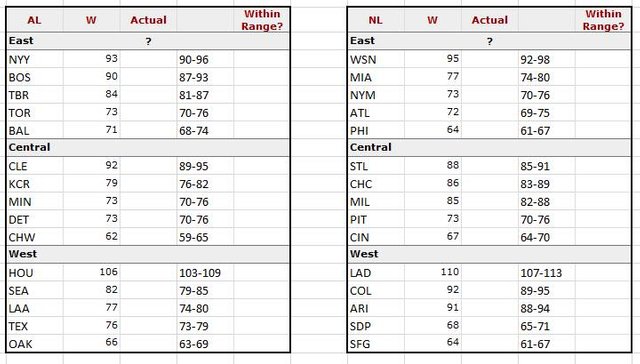
Here are the results (from inputing the data from August 2nd, 2017).
So we'll see you in October when we can look at how well this model predicted the amount of wins!
.jpg)
Thanks for viewing!
Images 1, 2, 3, 4, 5
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Up Next
Part 2 of the tutorial is to predict which current position MLB players will make the HOF. I will use it as a guide to try and predict MLB pitchers' HOF probabilities.
I might also tackle the NFL, and see if college statistics and the NFL combine measures could predict how well an athlete will perform in the NFL.
Hi, as a sign of my support for the tag #sports and #football, I vote for you and begin to follow you.
Great post, great use of pictures, glad to have you on Steem. Upvoted and resteemed and followed.
As my buddy, also a math teacher, used as the motto for his school's math program: math is life.
Well thank you @eeks. I'm really new to blogging and also by having more of that "math" mind, can sometimes find it hard to be creative to write and really express thoughts very clearly. I guess being a teacher, I do have some experience of going into a mindset of intentionally communicating clearly (and try to be entertaining at the same time). But regardless, it's nice and reassuring to hear someone compliment a post.
what about you :D did u got supply in maths ? :D Just kidding :D
I love your post, thanks for sharing! I gave you a vote. I hope you enjoy it.
I like your professors! And your article! Resteemed! :)
One of the professors mentioned above is retired. So he's just been teaching for the fun of it the last few years. And it's obviously apparent when sitting in his lectures that he has a passion for teaching and for data science. He is phenomenal.
If only all profs and teachers would be like this...
Machine learning is something very very important, and I hope many people will master to create good machine learning projects since we need to make sure AI will be in the hands of the mass rather than owned by the few large corporates. That will be the only way to survive and live a kind of free world when AI reaches singularity, something that it will do for sure in my opinion.
You're not kidding! If a few large corporates dominate the Machine Learning and AI, the World will be at their mercy...and that's scary.
Join us on #steemSTEM / Follow our curation trail on Streemian
Thank you for this very interesting article. It has been advertised on our chat channel (and upvoted).
The steemSTEM project is a community-supported project aiming to increase the quality and the visibility of STEM (STEM is the acronym for Science, Technology, Engineering and Mathematics) articles on Steemit.
Unfortunately, I think stirring and fine-tuning is popular to boost scores on common datasets. Which is fine if you are making a model to just predict that dataset, but may end up perform worse against more general applications (like reality). Lazy programming and poor analysis will end up leading us to the apocalypse. Good think sport prediction models won't become sentient. I hope.
Good luck on your data science journey!
That's actually one thing we did talk about in our classes. Not necessarily that it's poorly done intentionally, but rather companies/businesses are asking their employees with a background in programming or BI to start and run their data science division...with the assumption that the transition is seamless (and more importantly will cost them less money). But what they don't realize is that they're setting it up to fail from the start (or at best, not going to reach its full potential), because the employee goes in there, (through no fault of their own, they just need the training), hacking away at the data and potentially overfitting.
Another thing we talked about too is that sometimes, the companies don't even know what they need. My director was telling me some of his students weren't getting certain jobs because companies were seeking candidates with deep knowledge and understandings of machine learning, deep learning, AI, etc...when all they really need is just someone who understands it to the point of being able to implement it. In others words, seeking candidates with PhDs, when really, a bachelors with some ML experience would have sufficed.
I just think a lot of companies want to get on board with it, as fast as possible, and not really thinking ahead of time how they want to utilize it.
Strange post, very amazing and good, I interest in this post. @na722