Machine Learning Latest Submitted Preprints | 2019-07-11
Machine Learning
Secure multi-party linear regression at plaintext speed (1901.09531v2)
Jonathan M. Bloom
2019-01-28
We detail distributed algorithms for scalable, secure multiparty linear regression and feature selection at essentially the same speed as plaintext regression. While the core geometric ideas are simple, the recognition of their broad utility when combined is novel. Our scheme opens the door to efficient and secure genome-wide association studies across multiple biobanks.
Unsupervised Data Augmentation for Consistency Training (1904.12848v2)
Qizhe Xie, Zihang Dai, Eduard Hovy, Minh-Thang Luong, Quoc V. Le
2019-04-29
Despite much success, deep learning generally does not perform well with small labeled training sets. In these scenarios, data augmentation has shown much promise in alleviating the need for more labeled data, but it so far has mostly been applied in supervised settings and achieved limited gains. In this work, we propose to apply data augmentation to unlabeled data in a semi-supervised learning setting. Our method, named Unsupervised Data Augmentation or UDA, encourages the model predictions to be consistent between an unlabeled example and an augmented unlabeled example. Unlike previous methods that use random noise such as Gaussian noise or dropout noise, UDA has a small twist in that it makes use of harder and more realistic noise generated by state-of-the-art data augmentation methods. This small twist leads to substantial improvements on six language tasks and three vision tasks even when the labeled set is extremely small. For example, on the IMDb text classification dataset, with only 20 labeled examples, UDA achieves an error rate of 4.20, outperforming the state-of-the-art model trained on 25,000 labeled examples. On standard semi-supervised learning benchmarks CIFAR-10 and SVHN, UDA outperforms all previous approaches and achieves an error rate of 2.7% on CIFAR-10 with only 4,000 examples and an error rate of 2.85% on SVHN with only 250 examples, nearly matching the performance of models trained on the full sets which are one or two orders of magnitude larger. UDA also works well on large-scale datasets such as ImageNet. When trained with 10% of the labeled set, UDA improves the top-1/top-5 accuracy from 55.1/77.3% to 68.7/88.5%. For the full ImageNet with 1.3M extra unlabeled data, UDA further pushes the performance from 78.3/94.4% to 79.0/94.5%.
On Designing Machine Learning Models for Malicious Network Traffic Classification (1907.04846v1)
Talha Ongun, Timothy Sakharaov, Simona Boboila, Alina Oprea, Tina Eliassi-Rad
2019-07-10
Machine learning (ML) started to become widely deployed in cyber security settings for shortening the detection cycle of cyber attacks. To date, most ML-based systems are either proprietary or make specific choices of feature representations and machine learning models. The success of these techniques is difficult to assess as public benchmark datasets are currently unavailable. In this paper, we provide concrete guidelines and recommendations for using supervised ML in cyber security. As a case study, we consider the problem of botnet detection from network traffic data. Among our findings we highlight that: (1) feature representations should take into consideration attack characteristics; (2) ensemble models are well-suited to handle class imbalance; (3) the granularity of ground truth plays an important role in the success of these methods.
Sparse Networks from Scratch: Faster Training without Losing Performance (1907.04840v1)
Tim Dettmers, Luke Zettlemoyer
2019-07-10
We demonstrate the possibility of what we call sparse learning: accelerated training of deep neural networks that maintain sparse weights throughout training while achieving performance levels competitive with dense networks. We accomplish this by developing sparse momentum, an algorithm which uses exponentially smoothed gradients (momentum) to identify layers and weights which reduce the error efficiently. Sparse momentum redistributes pruned weights across layers according to the mean momentum magnitude of each layer. Within a layer, sparse momentum grows weights according to the momentum magnitude of zero-valued weights. We demonstrate state-of-the-art sparse performance on MNIST, CIFAR-10, and ImageNet, decreasing the mean error by a relative 8%, 15%, and 6% compared to other sparse algorithms. Furthermore, we show that our algorithm can reliably find the equivalent of winning lottery tickets from random initialization: Our algorithm finds sparse configurations with 20% or fewer weights which perform as well, or better than their dense counterparts. Sparse momentum also decreases the training time: It requires a single training run -- no re-training is required -- and increases training speed up to 11.85x. In our analysis, we show that our sparse networks might be able to reach dense performance levels by learning more general features which are useful to a broader range of classes than dense networks.
Learning the Wireless V2I Channels Using Deep Neural Networks (1907.04831v1)
Tian-Hao Li, Muhammad R. A. Khandaker, Faisal Tariq, Kai-Kit Wong, Risala T. Khan
2019-07-10
For high data rate wireless communication systems, developing an efficient channel estimation approach is extremely vital for channel detection and signal recovery. With the trend of high-mobility wireless communications between vehicles and vehicles-to-infrastructure (V2I), V2I communications pose additional challenges to obtaining real-time channel measurements. Deep learning (DL) techniques, in this context, offer learning ability and optimization capability that can approximate many kinds of functions. In this paper, we develop a DL-based channel prediction method to estimate channel responses for V2I communications. We have demonstrated how fast neural networks can learn V2I channel properties and the changing trend. The network is trained with a series of channel responses and known pilots, which then speculates the next channel response based on the acquired knowledge. The predicted channel is then used to evaluate the system performance.
Complete Dictionary Learning via 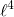 -Norm Maximization over the Orthogonal Group (1906.02435v2)
-Norm Maximization over the Orthogonal Group (1906.02435v2)
Yuexiang Zhai, Zitong Yang, Zhenyu Liao, John Wright, Yi Ma
2019-06-06
This paper considers the fundamental problem of learning a complete (orthogonal) dictionary from samples of sparsely generated signals. Most existing methods solve the dictionary (and sparse representations) based on heuristic algorithms, usually without theoretical guarantees for either optimality or complexity. The recent
-minimization based methods do provide such guarantees but the associated algorithms recover the dictionary one column at a time. In this work, we propose a new formulation that maximizes the
A Non-Asymptotic Analysis of Network Independence for Distributed Stochastic Gradient Descent (1906.02702v4)
Alex Olshevsky, Ioannis Ch. Paschalidis, Shi Pu
2019-06-06
This paper is concerned with minimizing the average of
cost functions over a network, in which agents may communicate and exchange information with their peers in the network. Specifically, we consider the setting where only noisy gradient information is available. To solve the problem, we study the standard distributed stochastic gradient descent (DSGD) method and perform a non-asymptotic convergence analysis. For strongly convex and smooth objective functions, we not only show that DSGD asymptotically achieves the optimal network independent convergence rate compared to centralized stochastic gradient descent (SGD), but also explicitly identify the non-asymptotic convergence rate as a function of characteristics of the objective functions and the network. Furthermore, we derive the time needed for DSGD to approach the asymptotic convergence rate, which behaves as
, where
denotes the spectral gap of the mixing matrix of communicating agents.
Specialized Decision Surface and Disentangled Feature for Weakly-Supervised Polyphonic Sound Event Detection (1905.10091v4)
Liwei Lin, Xiangdong Wang, Hong Liu, Yueliang Qian
2019-05-24
Sound event detection (SED) is to recognize the presence of sound events in the segment of audio and detect their onset as well as offset. SED can be regarded as a supervised learning task when strong annotations (timestamps) are available during learning. However, due to the high cost of manual strong labeling data, it becomes crucial to introduce weakly supervised learning to SED, in which only weak annotations (clip-level annotations without timestamps) are available during learning. In this paper, we approach SED as a multiple instance learning (MIL) problem and utilize a neural network framework with an embedding-level pooling module to solve it. The pooling module, which aggregates a sequence of high-level features generated by the neural network feature encoder into a single contextual feature representation, enables the model to learn with only weak annotations. We explore the self-learning ability of different pooling modules on finer information and propose a specialized decision surface (SDS) for class-wise attention pooling (cATP) module. We analyze and explained why a cATP module with SDS is better than other typical pooling modules from the perspective of feature space. According to the co-occurrence of several categories in the multi-label classification task, we also propose a disentangled feature (DF) to reduce interference between categories, which optimizes the high-level feature space by disentangling it based on class-wise identifiable information in the training set and obtaining multiple different subspaces. Experiments show that our approach achieves state-of-art performance on Task4 of the DCASE2018 challenge.
Variational Autoencoders and Nonlinear ICA: A Unifying Framework (1907.04809v1)
Ilyes Khemakhem, Diederik P. Kingma, Aapo Hyvärinen
2019-07-10
The framework of variational autoencoders allows us to efficiently learn deep latent-variable models, such that the model's marginal distribution over observed variables fits the data. Often, we're interested in going a step further, and want to approximate the true joint distribution over observed and latent variables, including the true prior and posterior distributions over latent variables. This is known to be generally impossible due to unidentifiability of the model. We address this issue by showing that for a broad family of deep latent-variable models, identification of the true joint distribution over observed and latent variables is actually possible up to a simple transformation, thus achieving a principled and powerful form of disentanglement. Our result requires a factorized prior distribution over the latent variables that is conditioned on an additionally observed variable, such as a class label or almost any other observation. We build on recent developments in nonlinear ICA, which we extend to the case with noisy, undercomplete or discrete observations, integrated in a maximum likelihood framework. The result also trivially contains identifiable flow-based generative models as a special case.
Quantifying Error in the Presence of Confounders for Causal Inference (1907.04805v1)
Rathin Desai, Amit Sharma
2019-07-10
Estimating average causal effect (ACE) is useful whenever we want to know the effect of an intervention on a given outcome. In the absence of a randomized experiment, many methods such as stratification and inverse propensity weighting have been proposed to estimate ACE. However, it is hard to know which method is optimal for a given dataset or which hyperparameters to use for a chosen method. To this end, we provide a framework to characterize the loss of a causal inference method against the true ACE, by framing causal inference as a representation learning problem. We show that many popular methods, including back-door methods can be considered as weighting or representation learning algorithms, and provide general error bounds for their causal estimates. In addition, we consider the case when unobserved variables can confound the causal estimate and extend proposed bounds using principles of robust statistics, considering confounding as contamination under the Huber contamination model. These bounds are also estimable; as an example, we provide empirical bounds for the Inverse Propensity Weighting (IPW) estimator and show how the bounds can be used to optimize the threshold of clipping extreme propensity scores. Our work provides a new way to reason about competing estimators, and opens up the potential of deriving new methods by minimizing the proposed error bounds.
Congratulations @maroonv! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Vote for @Steemitboard as a witness to get one more award and increased upvotes!