Mediteam.us 개발 - Python & Selenium을 이용한 구글검색 크롤링
'관련글 검색' 기능을 넣기 위해 마지막으로 생각해낸 방식이 바로 사이트 내부의 구글 검색엔진을 이용하는 방법이었다. 핵심 키워드를 구하고, 그것을 검색창에 넣어 값을 가져오면 쉽게 가능할 것 같았다. 그리고 주기적으로 전체를 갱신해준다면, 그 값도 점점 최신이 될 것이라고 판단.
이를 위해 필요한 라이브러리가 바로 Selenium 이라는 것이다. 이전 포스팅에서도 소개했었지만,

이 책을 슥 읽어보면 어떤 기능을 구현해낼 수 있겠구나 감이 잘 온다.
그럼 왜 이런 번거로운 방식을 사용해야하느냐? 하면 바로, 우리가 바로 받을 수 있는 페이지 소스(HTML)은 우리가 원하는 결과물이 아니기 때문이다.
아래의 메디팀 사이트에 있는 구글 검색엔진을 이용할 경우 나오는 결과값이다. 그러나 실제 이 페이지는 달랑 몇줄의 자바스크립스로 쓰여진다.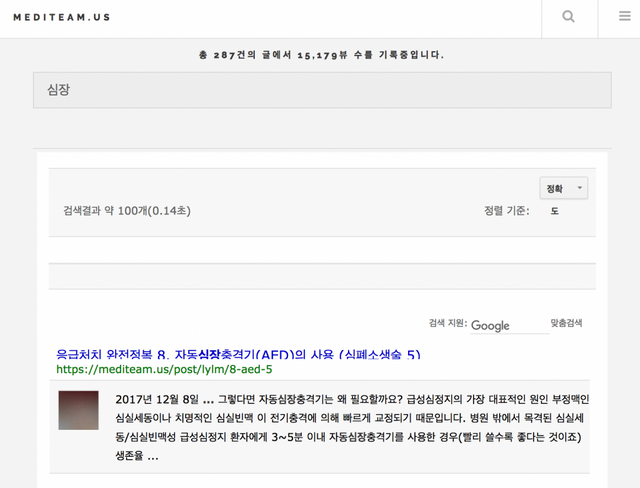
아래와 같다.
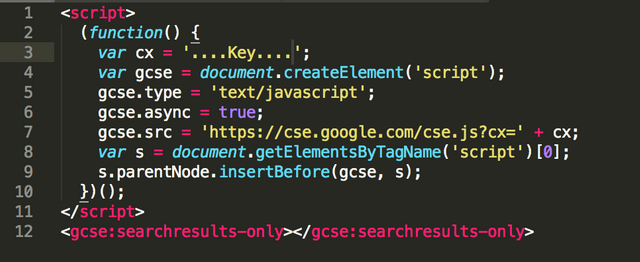 즉, 우리가 원하는 것은 페이지의 기본 소스(HTML)값이 아니라, 실제로 저 페이지가 읽어진 다음 들어오는 진짜 결과이기 때문에, 셀레니움이 필요하게 된다.
즉, 우리가 원하는 것은 페이지의 기본 소스(HTML)값이 아니라, 실제로 저 페이지가 읽어진 다음 들어오는 진짜 결과이기 때문에, 셀레니움이 필요하게 된다.
셀레니움은 일종의 껍데기이고, 실제로 그 안에서 구동하는 드라이브가 필요하다. 크롬, 파이어폭스, PhantomJS 등이 있고, 나는 chromedriver를 사용하였다. 이유는 특별히 없었다.
크롬드라이버 최신버전을 받아 같은 폴더에 넣어준다. (https://sites.google.com/a/chromium.org/chromedriver/downloads)
깃헙 소스는 조금 바꿔서 올려서 동일한 결과가 나오진 않는다.
첫번째 예제 먼저 설명하면,
Github : https://github.com/junn279/python_examples/blob/master/selenium_basic.py

일단 주석을 무시하면,
10 : Chrome 드라이버를 불러온다.
11 : Chrome을 800x600으로 띄운다.
12 : '내용을 다운로드 받을때까지 5초까지 기다릴 것' 임을 선언하다.
13 : 해당 주소를 연다.
14 : 받아진 소스를 받는다.
19 : 프로세스를 종료한다. (이것을 주석처리 안해놓으면, 작업이후에 창이 알아서 종료된다.) * 매우 중요한 한줄인데, 리눅스에서 이 처리를 안해놓으면 일종의 좀비 프로세스들이 계속 생성된다.
driver.quit은 프로세스 자체를 종료, driver.close는 창을 닫는 명령이다.
아래와 같이 페이지를 구성했고,
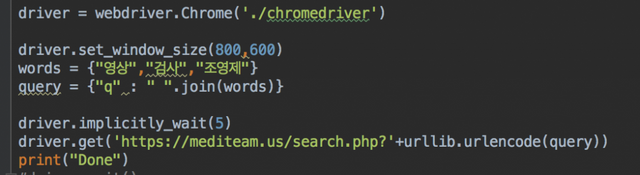
소스를 실행시키면 '자동화된 테스트 소프트웨어에 의해 제어되고 있습니다.' 라는 것이 출력되면서 원하는 주소가 오픈된다.
다시 소스로 돌아가면, 주석처리된 6, 7, 8, 22 번째 줄은 크롬을 직접 띄우지 않고 가상의 화면으로 돌릴 때 사용하는 코드이다. 이를 'Headless Chrome with Selenium' 이라고 표현한다. 혹은 크롬드라이버를 띄울 때 --headless 옵션을 주는 방법이 있다. 이것은 두번째 소스에 포함되어 있다.
options = Options()
options.add_argument('--no-sandbox')
그러나 저 소스를 바로 리눅스 서버로 옮기면 시작부터 에러가 난다.
그것을 해결한 것이 두번째 깃헙 소스인데, 사실 --sandbox 옵션 하나만 더 넣음으로써 모든것이 끝나버렸다.
그 다음 발생한 문제는 바로 implicity wait에 관련된 문제다.
실제로 충분한 인터넷 속도가 보장된 데스크탑 환경에서는 5초정도 기다림으로서 대부분의 값을 다 받아낼 수 있으나, 리눅스에 넣었을 경우 이 속도가 상당히 느려지는 것을 확인할 수 있었다. 실제로 객체를 찾지못하고 중간에 exception이 생기는 것을 확인하기도 했다.
implicity wait이란 명시된 시간동안 일단 기다리고, 그 후에 object를 찾는 다는 의미로서, 만약 5초로 명시할 경우 최대 5초가 지나면 우리가 원하는 객체 여부와 상관없이 작업이 진행된다. 따라서 지정된 시간동안 갑작스런 인터넷 전송 지연으로 값이 받아지지 않는다면 에러가 발생할 수 있게 되는 것.
이를 해결하기 위한 방법으로 아래의 글들을 참조, Explicit wait를 사용하는 방법을 써야한다. (세번째 깃헙 코드) 이는 충분한 시간을 두면서 우리가 원하는 객체가 찾아질 경우 작업을 진행하는 방식이다.
http://toolsqa.com/selenium-webdriver/implicit-explicit-n-fluent-wait/
https://beomi.github.io/2017/10/29/HowToMakeWebCrawler-ImplicitWait-vs-ExplicitWait/
다음 편에서는 Explicit wait을 이용하여 세번째 소스로 실제 검색 결과를 받아오는 과정을 포스팅해보겠다.
Github source :
https://github.com/junn279/python_examples/blob/master/selenium_basic.py (기본, Implicitly Wait)
https://github.com/junn279/python_examples/blob/master/selenium_ubuntu.py (Ubuntu setting, Implicitly Wait)
https://github.com/junn279/python_examples/blob/master/selenium_ubuntu.py (Explicitly Wait)
References :
https://sites.google.com/a/chromium.org/chromedriver/downloads
https://christopher.su/2015/selenium-chromedriver-ubuntu/
https://beomi.github.io/2017/10/29/HowToMakeWebCrawler-ImplicitWait-vs-ExplicitWait/
Thank you great post :)
Awesome!
지금 공부중인 내용이라 리스팀 합니다... 좋은 글 써주셔서 감사합니다.
감사합니다~ 항상 그렇지만 부족한 글이죠..
저도 가상으로 사용하는데 직접 브라우저를 띄운 것처럼 동작이 여의치는 않은듯 합니다. 로그를 보면 스크립트 오류가 잡다하게 많이 나오는것을 보면요 . 잘보고 있습니다. 올려주시는게 제가 사용했다거나 관심있는 쪽이라 무척 흥미롭군요 ㅎㅎ
아 그렇군요. 크롤링 때문에 잠깐 이용해본 것이라, 제대로 자동화로 들어가려면 만만치 않은가보네요 ㅎ 감사합니다~ㅎ
PhantomJs 를 추천합니다. headless 브라우저로 chrome처럼 html코드들을 모두 랜더링 하지 않아서 그나마 빠릅니다.^^
Selenium를 통해서 크롤링하면서 맞닥들였던 문제가 원하는 객체들이 브라우저에 띄워졌는지에 대해 확인하기가 어렵다는것입니다. 그나마 최선은 Fluent Wait로 Explicit waiting 하면서 주기적으로 크롤링을 원하는 객체가 호출 가능한 상태에 이르는지 확인하는 것입니다.
Selenium을 써야할때가 하나 더 있는데, Cloudflare와 같은 DDOS방지 서비스가 들어가있는경우 Selenium을 써서 javascript를 실행해줘야 원래 url로 접속하게 해야 할때 입니다. 인증만하고..
selenium web-driver를 통해서 받은 cookies들을 python requests로 넘겨서 더 빠르게 크롤링이 가능합니다.
아 ㅎ스팀을 시작하셨군요! 포스팅 올려주시면 열심히 배우겠습니다 ㅋ 크롬은 그냥 골랐던 건데, 시작을 잘못했군요 ㅠㅠ