인공지능시대를 준비하는 나만의 방법
1. 도입
어디를 가나 4차 산업혁명이라는 주제로 인공지능 이야기를 한다. (물론 최근에는 암호화폐 이야기로 넘어갔지만…^^) 알파고가 세계최고의 바둑기사를 이겼다는 소식은 전 세계를 놀라게 했고, 특히나 한국인들에게 큰 충격을 가져온 것 같다.
나는 솔직히 알파고가 이세돌을 이겼을 때 큰 충격을 받지 않았다. 기계가 사람보다 경우의 수를 따지는 속도가 훨씬 빠르니까 당연히 기계가 이길 것이라고 생각했다. 오히려 이세돌이 한 번 이겼을 때 아직도 기계의 계산처리능력이 사람을 따라가지 못한다는 생각에 놀라워했던 기억이 난다. 그래서 나는 사람들이 인공지능이 인간을 지배할 것이라는 이야기를 들어도 말도 안 된다고 생각하고 별거 아닌 것으로 여겼다.
그러다가 ‘waitbutwhy블로그의 인공지능 글'을 읽게 되었다. 이 글을 읽고 인공지능에 대한 나의 생각은 180도 변해버렸다. 역사상 가장 급변의 시기가 찾아오고, 어쩌면 인공지능이 인류를 지배할 수도 있겠다는 생각이 나를 사로잡았다. 그리고 인공지능이 무서워지기 시작했다.
하지만 무서워하고만 있을 수는 없었다. 그래서 나는 인공지능이 무엇이며 어디까지 발전했는지 정확히 알아보기로 했다. 그래서 인공지능을 공부하기 시작했다.
2. 현재 인공지능은 어디까지 왔을까?
인공지능은 최근에 나타난 용어도, 개념도 아니다. 1956년에 다트머스 대학의 존 매카시 교수가 처음으로 인공지능(AI)라는 용어를 사용했고, 1968년에 개봉한 영화 ‘2001 스페이스 오딧세이’에는 ‘HAL9000’이라는 생각하는 기계가 등장한다. 인간처럼 생각하고 문제를 푸는 인공지능을 만드려는 연구가 1970년대까지 이어졌지만, 큰 성과를 내지 못하며 인공지능 연구는 빙하기를 맞게 된다.
기나긴 빙하기가 이어지다, 인터넷이 등장해 방대한 데이터가 생기면서 1990년대 후반부터 빙하기에서 깨어나기 시작한다. 방대한 데이터를 통해 기계를 학습시키는 ‘머신러닝’기법을 통해 성과가 나오기 시작한 것이다.
기존의 컴퓨터는 ‘두 개의 입력 값이 들어오면 더하라’라는 연산과정을 입력하고 a와 b라는 입력 값을 넣어줘서 c(a+b)라는 결과 값을 얻어내는 것이었다면, 머신러닝은 연산과정을 입력하지 않고 많은 양의 입력 값과 결과 값 데이터 (1,2/3) (4,5/9) (10,11/21)…을 제공하여 컴퓨터가 ‘두 개의 입력 값이 들어오면 더하라’라는 연산과정을 ‘학습’하는 것이다. 즉, 입력 값과 연산과정을 넣어 결과를 얻던 기존의 방식에서 입력 데이터와 결과 데이터를 넣어서 ‘데이터를 분석하는 방법’을 학습하는 새로운 방식을 구현해낸 것이다.
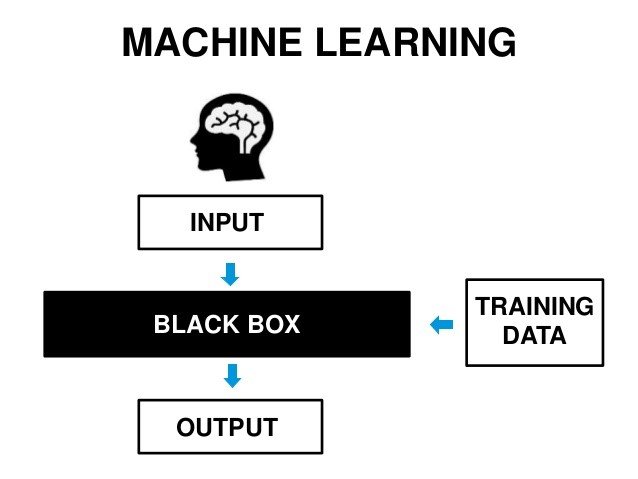
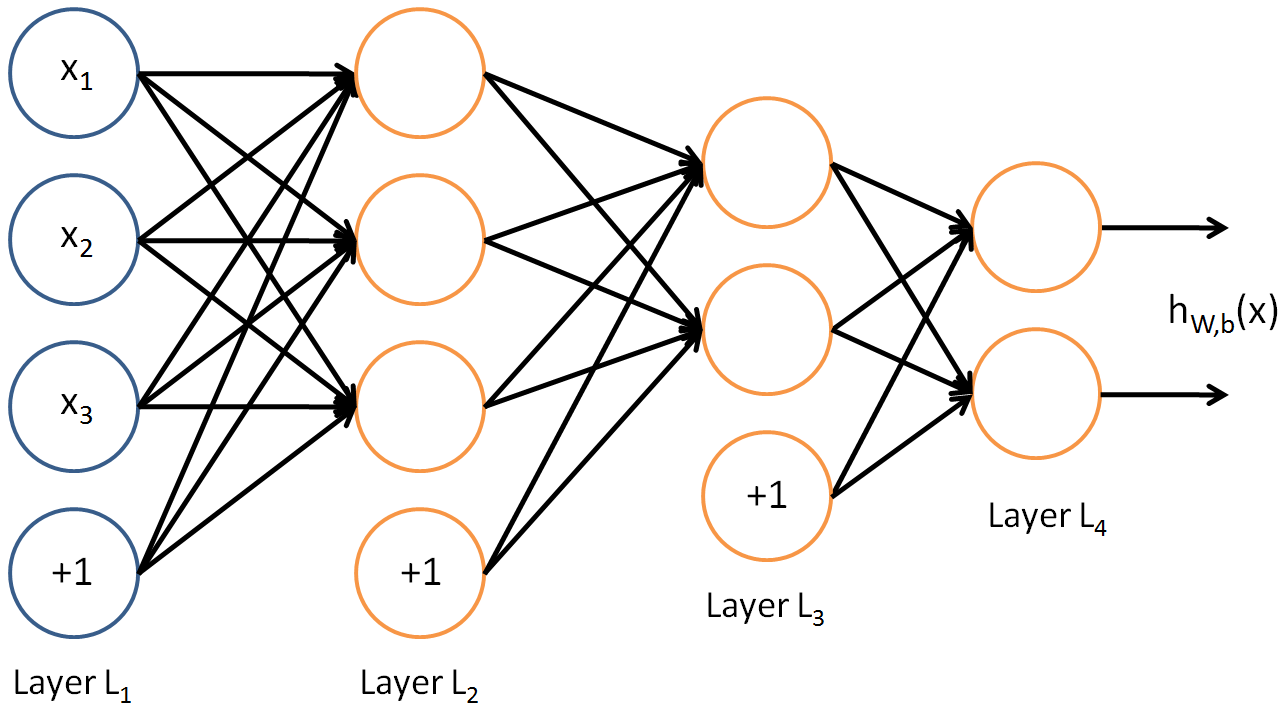
머신러닝을 구현하기 위한 수 많은 알고리즘이 존재하는데, 그 중에서 인간의 신경망(neural network)를 본따서 구현한 딥러닝(deep earning) 엄청난 성과를 이루어냈다.
사람은 뉴런이라는 신경망을 통해 신호를 전달한다. 뉴런은 어떠한 자극을 받았을 때 일정한 수치(역치)를 넘어선다면 시냅스를 통해 다음 뉴런으로 신호를 전달한다. 다음 뉴런은 이전 뉴런들의 신호를 합쳐서 일정한 수치를 넘는다면 또 다음 뉴런으로 신호를 보낸다. 뉴런마다 일정한 수치가 다르기 때문에 이것은 정보가 되고, 우리는 이것으로 판단을 내려 결과를 얻는다. 과학자들은 이 구조를 본따서 뉴런과 같은 역할의 ‘퍼셉트론’을 만들어 인공신경망을 구현해낸다.
딥러닝은 이 일정한 수치(역치)를 결정하는 요소를 사람이 설정하지 않고, 수 많은 데이터 속에서 패턴을 스스로 찾도록 만든 것이다. 기존에는 지도 학습(supervised learning)이라고 하는, 기계에 ‘이 이미지가 강아지야’라고 알려주면 이를 기준으로 강아지 사진인지 아닌지 판별하는 기술을 사용했다면, 딥러닝에는 비지도 학습(unsupervised learning)이라는 ‘이 이미지가 강아지야’라는 과정이 없이도 ‘이런게 강아지겠구나’라고 스스로 패턴을 찾게 되는 기술을 사용한다.
CPU, GPU, 메모리 등의 하드웨어 성능이 강력해지면서 인공신경망 구현이 가능해졌고, 결국 2012년 세계 최대의 이미지 인식 경연대회 ‘ILSVRC’에서 제프리 힌튼 교수가 ‘딥러닝’을 통해 기존의 머신러닝 팀들을 압도하는 성능을 내보이며 딥러닝의 시대를 맞이하고,
결국 딥러닝은 ‘알파고’라는 인공지능을 탄생시키며 우리를 놀라게 만들었다.
3. 인공지능을 걱정해야 할까?
‘딥러닝’이 인공지능 역사에 획을 그엇고, 딥러닝은 이미 우리 주위에서 엄청 많이 사용되기 시작했다 (참고: https://brunch.co.kr/@itschloe1/23). 그렇다면, 우리는 인공지능이 세상을 지배할 것을 걱정해야할까? 그래서 인공지능 연구를 그만둬야할까?
나의 대답은 ‘아직은 걱정하기에 이르고, 지금처럼 인공지능을 발전시켜 나아가야한다’이다.
읽은 것과 같이, 지금 성행하는 인공지능은 기계가 스스로 생각하는 그러한 개념의 인공지능이 아니다. 현재의 인공지능은 사람이 제공한 데이터를 어떻게 분석해야할지를 찾아내는 프로그램이다. 따라서, 지금의 인공지능은 데이터 분석의 패러다임 변화라고 이해하는 것이 올바르다.
많은 사람들이 두려워하는 HAL9000과 같은 인공지능은 아직 나오지도 않았고, 당분간은 나오지 않을 것으로 예상되니 두려워할 필요 없다. 우리가 정말 두려워해야할 것은 스스로 생각하는 기계가 인류를 지배할까가 아니라, 인공지능으로 인해 사라질 직업이 많아질 것이라는 사실이다.
이제는 질문을 바꿔서, ‘우리는 인공지능에게 어떤 작업을 물려주고, 우리 인간이 집중해야 할 일은 무엇인가’를 고민해야한다. 데이터를 수집해 해결할 수 있는 단순반복적인 노동은 인공지능에게 물려주고, 우리 인간은 정말 인간만이 할 수 있는 ‘창의성’가득한 일에 집중해야 한다. 그리고 미리 사라질 직업들을 예측하고, 직업을 잃게 될 이들을 위한 기본 소득과 같은 정책을 논의해봐야 하는 시점이다.
4. 인공지능시대를 준비하는 방법
다시 한 번 말하지만, 스스로 생각하는 기계가 탄생하는 건 머나먼 이야기고, 지금 우리가 접하는 인공지능은 데이터 분석의 패러다임이 바뀐 것이다. 입력 값과 연산과정을 넣어 결과를 얻던 기존의 방식에서 많은 데이터를 넣어서 ‘데이터를 분석하는 방법’을 구하는 새로운 방식을 구현해낸 것이다.
이러한 인공지능시대를 맞이하여 우리가 준비해야할 것은 ‘데이터를 다루는 사고방식'이라고 생각한다. 어떠한 방식으로 머신러닝이 이루어지는가는 전문가에게 맡기고, 우리들은 무슨 데이터를 모으고, 어떻게 데이터를 모으며, 더 좋은 데이터를 제공하기 위해 노력해야한다고 생각한다.
구체적으로, 첫째. 무슨 데이터를 모아야하는지 고민해야 한다. 주위에 어떤 문제점이 존재하는지 분명하게 파악하는 것이 가장 중요하다. 문제점을 파악한 후 그냥 생각을 통해 해결할지, 기존의 데이터 분석과정을 통해 해결할지, 인공지능을 활용하여 해결할지 결정한다. 정말 인공지능이 필요할 때에, 문제점을 해결하기 위한 데이터를 모아야 한다.
둘째. 어떻게 데이터를 모아야 할지 고민해야 한다. 손으로 적던 기계로 모으던 데이터를 모아야 인공지능을 돌릴 수 있다. 처음부터 거창하게 빅데이터를 모으려들지 말고, ‘내가 밥을 언제 먹는지’같은 일상적인 부분을 적어보는 것부터 연습해서 데이터를 모으는 사고과정을 익히는 것이 중요하다고 생각한다. 이것이 익숙해질 때 데이터 마이닝이나 사물인터넷과 같은 기술, 기기를 이용해서 데이터를 모으는 단계로 넘어가보자.
셋째. 인공지능에게 더 좋은 데이터를 제공하려고 고민해야 한다. 인공지능을 잘 학습시키려면 잘 가공된 데이터가 필요하다. 뒤죽박죽 데이터보다 정리된 데이터에서 더 특별한 특징을 뽑아낼 가능성이 높기 때문이다. 하지만 우리 현실 속의 데이터는 생각보다 정리되어있지 않다. 데이터를 잘 정리할 수 있는 사람이 인공지능을 더 잘 활용할 것이라고 나는 확신한다.
이렇게 ‘데이터를 다루는 사고방식’을 익힌 사람이라면, 정말 인공지능이 필요한 시점에서 인공지능을 하나의 도구로서 이용할 수 있을 것이고, 그런 사람이 인공지능시대를 가장 현명하게 살아가는 사람이 될 것이라고 나는 예상하고 있다.
5. 내가 준비하는 것
나는 인공지능시대를 맞아 ‘데이터를 다루는 사고방식’을 학습하기 위해 이번년도부터 산업공학과를 복수전공한다. 산업공학과는 산업시스템에서 필요한 요소들(사람, 컴퓨터, 기계 등)을 공부하는데, 그 중 데이터 다루는 것을 굉장히 핵심으로 배운다. 또한 산업공학과에서 통계적 모델링을 배우기 때문에 데이터를 다루는데 도움이 될 것이라고 판단하기도 했다.
그리고 일상생활에서 데이터를 모으기 시작했다. ‘디스코에 글 공유하는 시간에 따른 좋아요 수’, ‘내가 카페에 들어가는 시간에 따라서 달라지는 머무르는 시간’과 같은 사소하지만 생산성을 높이는데 사용될 수 있는 데이터를 모아보는 중이다. 이것은 ‘헬로데이터과학’이라는 책을 보고서 영감을 받아 시작한 것인데, 데이터에 기본지식이 없던 나에게 정말 도움이 되는 책이었다.
그리고 인공지능에 대한 공부를 계속하는 중이다. 2017년에는 ‘인공지능이 무엇인지’ 기본 개념을 알아보는데 초점을 맞추었다면, 2018년에는 ‘머신러닝이 어떻게 구현되었는지’ 기술적인 부분을 공부하고 ‘텐서플로우’를 이용해서 직접 부딪혀볼 생각이다. 그리고 ‘인공지능이 정말 필요한 곳이 어디이고, 어떻게 서비스화 시켜야할지’ 아주 많이 생각해볼 것이다. 딥러닝을 이용한 인공지능은 세상을 엄청나게 변화시킬 도구이기 때문에 최고의 비즈니스 기회라고 생각하기 때문이다.
이미 우리 앞으로 다가온 인공지능시대를 현명하게 살아가는데 이 글이 조금이라도 도움이 되었으면 좋겠다.
[참고]
https://ko.wikipedia.org/wiki/%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5
http://m.news.naver.com/read.nhn?mode=LSD&sid1=001&oid=020&aid=0003067173
http://news.joins.com/article/21972067
https://hunkim.github.io/ml/ > 머신러닝, 딥러닝을 공부하고 싶은 사람에게 강추!
https://www.coursera.org/learn/machine-learning > 머신러닝의 바이블 강의!
https://www.slideshare.net/yongho/ss-79607172
https://brunch.co.kr/@nsung/7
머신러닝, 딥러닝 간단 설명 영상
책: 인공지능의 시대, 인간을 다시 묻다.
권용진 퀀트님의 오프라인 강의
헉 뼈 속부터 문과인 저는 머리가 핑 도네요..ㅎㅎ 그래도 설명을 잘해주셔서 끝까지 읽을 수 있었습니다. 잘 읽고 갑니다~
읽어주셔서 감사합니다!!!^^
역시 데이터가 갑이죠.
데이터 공부 저도 해야하는데요... ㅎㅎ
많은 공유 바랍니다 ㅎ