[논문 소개] The Devil of Face Recognition is in the Noise
- 논문 정보
- 논문 제목: The Devil of Face Recognition is in the Noise
- 논문 링크: https://arxiv.org/abs/1807.11649
- 학회 정보: ECCV 2018
오늘 소개드릴 논문은 "The Devil of Face Recognition is in the Noise" (https://arxiv.org/abs/1807.11649)으로 ECCV 2018에 나올 논문입니다. Face Recognition을 주제로 하고 있고, 그 분야에서는 최근 가장 좋은 성과 (그냥 제 느낌.. )을 보여주고 있는 중국의 SenseTime에서 나온 논문입니다. 회사 얘기를 먼저 하는 이유는 이 논문은 자본력이 없으면 안 되는 논문... 그런 논문입니다. 알고리즘을 제안하는 논문이 아니라 데이터베이스 자체에 있는 Noise의 영향력에 대해 보는데, 그 데이터베이스가 엄청 큽니다. -_- 노동력 == 돈!!!
"The Devil of Face Recognition is in the Noise" 이라는 거창한 제목은 "The devil is in the detail"에서 착안한거 같은 느낌이지만, 요즘은 중국인들의 논문도 제목에 유머까지 넣어서 섹시하게 지으려고 노력하는거 같네요. 저같은 공돌이는 그런거 못 하는데.. -_- 제목에서 알수 있듯이 이 논문은 얼굴 인식 테스크에서 데이터베이스 안에 노이즈에 대한 영향력을 분석합니다. 주로 답하려는 대답은 적은 clean data는 얼마나 큰 Noisy data와 비슷한 효과를 데이터 기반 방법인 딥러닝 기반 방법에서 보이는가? 데이터 노이즈를 줄이려면 어떻게 데이터를 정제해야하는가? 등등의 질문에 답하고자 합니다.

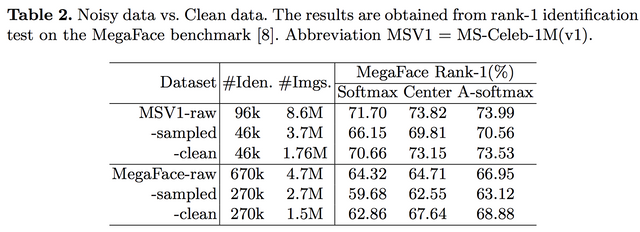
아시겠지만, 얼굴 인식 데이터 베이스는 일종의 검색 알고리즘 기반 클롤러를 이용하여 모으는 경우가 많고, 그 크기가 크기때문에 노이즈 합니다. 논문에서 제시한 바와 같이 그 노이즈는 쉬운 노이즈도 있지만, 사람이 봐도 쉽지 않은 노이즈도 많이 있죠. 또한 아래 표와 같이 그 크기도 방대하고, 포함하고 있는 사람의 수(Identities)도 엄청납니다. 그래서 이 논문에서 노동력을 기울여 만든 IMDb-Face 말고는 자동화된 정제 방식을 사용하고 있습니다. (1.7M장을 사람한테 정제 시키는 중국의 노동력 클라스!!!)
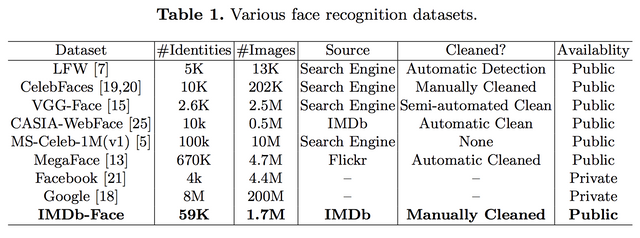
일단 이런 데이터 베이스의 현 상황부터 봐야 합니다. 이 논문에서도 많이 보긴 하지만 다 보진 못 합니다. 그래서 일부 셋을 추리고, 일부 사람을 추려서 그 데이터베이스의 상황을 분석합니다. 그런데 상황이 생각보다 좋지 않습니다. 데이터베이스가 클수록 노이즈의 양이 많고, 일부의 경우 그 노이즈의 수치가 50%이상입니다. -_- ....그리고 노이즈가 어느 정도 분포로 있는지 보면 테일부분에서 더 문제가 될거 같습니다.
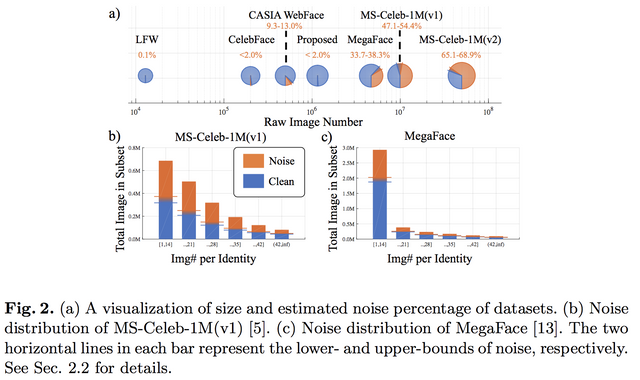
그래서 이 논문에서 Noise-Controlled Face Dataset을 만들어 버립니다. 30%이상 노이즈가 섞인 기존 데이터 셋과 분석해야 하니깐요.

대륙의 패기 쩔지 않나요? 50명을 고용해서 한달동안 데이터 정제만 시킵니다. (인건비!!!) 그리고 그 퀄리티도 체크하죠.. -_- 중국에서는 가능한 연구인듯 합니다.
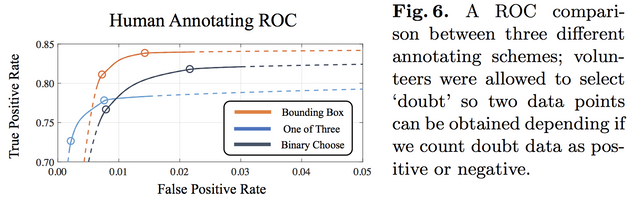
또 여기서 재밋는 연구를 제시합니다. 그럼 어떤 방식으로 정제를 해야 정확하냐 이겁니다. 사람을 보고 바운딩 박스를 치게 하거나, 3개 얼굴 중 제시한 사람의 얼굴이 뭔지 찾거나, 있다 없다식으로 정제하는 방법을 제시하고 얼마나 정확한지 체크합니다.

결과는 아래와 같습니다. 결론이... 사람이 할 때, 하나의 셈플에 대해서 더 많은 시간 .. 그러니깐 더 노동력을 투입하게 하면 더 정확하다는 겁니다. -_- 역시 노동력!!
이제 Noise-Controlled Face Dataset를 만들었으니, 그 영향력을 분석합니다. 분석은 Deep Learning is Robust to Massive Label Noise (https://arxiv.org/abs/1705.10694) 논문의 영향을 많이 받은듯 합니다. 그 논문은 노이지하건 뭐하건 일단 데이터 많으면 좋다!!를 다시 주창한 논문인데, 이 논문은 그렇게 무제한적으로 늘리지 못할 때, 노이즈의 영향을 다시 보는거 같습니다. 일단 그 논문에서와 같이 labeling이 서로 바뀌는 경우 더 많이 떨어지고, 고정된 clean data에 대해 노이즈가 많으면 확실히 떨어지나 그래도 양이 많아지면 조금씩 오르는거 같습니다.
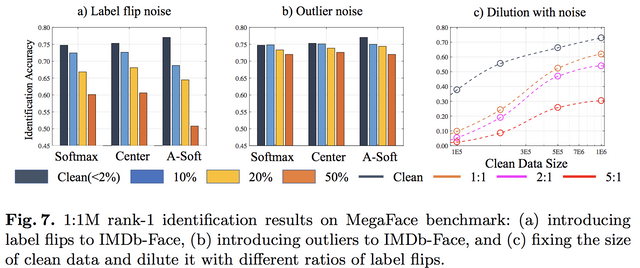
또한 다른 데이터로 실험했을 때도 적은 수의 정제된 데이터를 사용하면 큰 데이터베이스를 사용한 것만큼 성능이 나옵니다. 그리고 이 논문에서는 "Reducing noisy samples could help an algorithm focuses more on hard examples learning, rather than picking up meaningless noises"라고 주장하는데... 퍼포먼스가 올라간건 이해하겠는데 이렇게까지 분석할 수 있는 개연성을 제공했는지는 잘 모르겠습니다. -_-..
데이터 정제의 중요성은 얼굴 인식 뿐 아니라, 의료 영상 등에 중요한 이슈로 늘 남아있습니다. 무한정 데이터가 공급될 수 없기에 Deep Learning is Robust to Massive Label Noise (https://arxiv.org/abs/1705.10694) 논문에서 주장하듯 계속 늘릴 수 없고 이 논문에서 제시되었듯 큰 데이터베이스일수록 정제 노력을 기울이기도 힘들기 때문입니다. 알고리즘으로 1% 올리긴 정말 어렵고 그것또한 많은 GPU를 이용한 최적화가 중요한 요인 중 하나인데, 데이터베이스 정제도 그런 규모의 경제에서 오는 문제가 있고, 또한 알고리즘으로 1% 올리는 거보다 노력대비 효과가 확실한듯 합니다. 그러나 이건 중국과 같이 노동력이 풍부한 경우 그 장점을 가지고, 또한 의료와 같이 도메인이 특정적일 경우 그 전문가의 투입과 유지가 그 질을 좌우할건데, 그 부분이 ... 걱정입니다. 논문 보면 세상 걱정을...
Hello jiwoopapa
You are welcomed by the service of FreeResteem.
We want to bring more people to your post.
If you like our service then put a upvote under this comment.
Thank you for remain with Steemit.
생각치도 못한 엄청난 방법이네요ㅋㅋㅋ
아니... 스팀잇에서 논문을 소개하는 분이 계시는구나... 했는데...
@sleeprince 왕자님이 여기에 계셨...? ㅋㅋㅋㅋㅋ
ㅋㅋㅋㅋㅋㅋㅋ반갑습니다