[논문 소개] Realistic Evaluation of Semi-Supervised Learning Algorithms
- 논문 정보
- 논문 제목: Realistic Evaluation of Semi-Supervised Learning Algorithms
- 논문 링크: https://arxiv.org/abs/1804.09170v1, https://openreview.net/forum?id=ByCZsFyPf
- 학회 정보: ICLR 2018 Workshop Submission
오늘 소개드릴 논문은 "Realistic Evaluation of Semi-Supervised Learning Algorithms" (https://arxiv.org/abs/1804.09170v1)입니다. ICLR 2018 워크샾에 제출된 논문이고, 1저자가 Google Brain Residency Program동안 한 결과물을 제출한 논문입니다. Google Brain Residency Program에서 낸 논문이기엔 저자에 Google Brain 사람들이 포함되어 있습니다. 그 중 Ian J. Goodfellow도 포함되어 있습니다. 그냥 다른 곳에서 다른 저자들이랑 썼으면 좋은 내용과 비판에도 불구하고 공격을 받을 수도 있었을거 같습니다. (제가 공격하겠다는건 아닙니다. 전 이런 류의 논문 정말 좋아합니다.)
일단 늘 그렇듯 논문의 제목을 보시면, Semi-Supervised Learning (SSL) Algorithms에 관련된 내용입니다. Supervised, Semi-supervised, Weakly supervised, Un-supervised 등 많은 용어가 나오는데, 일단 제가 Semi-supervised를 가장 잘 표현한 장표는 얼마 전 NIPS에서 발표한 "Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results" (https://arxiv.org/pdf/1703.01780.pdf) 저자들의 그림을 좋아합니다.
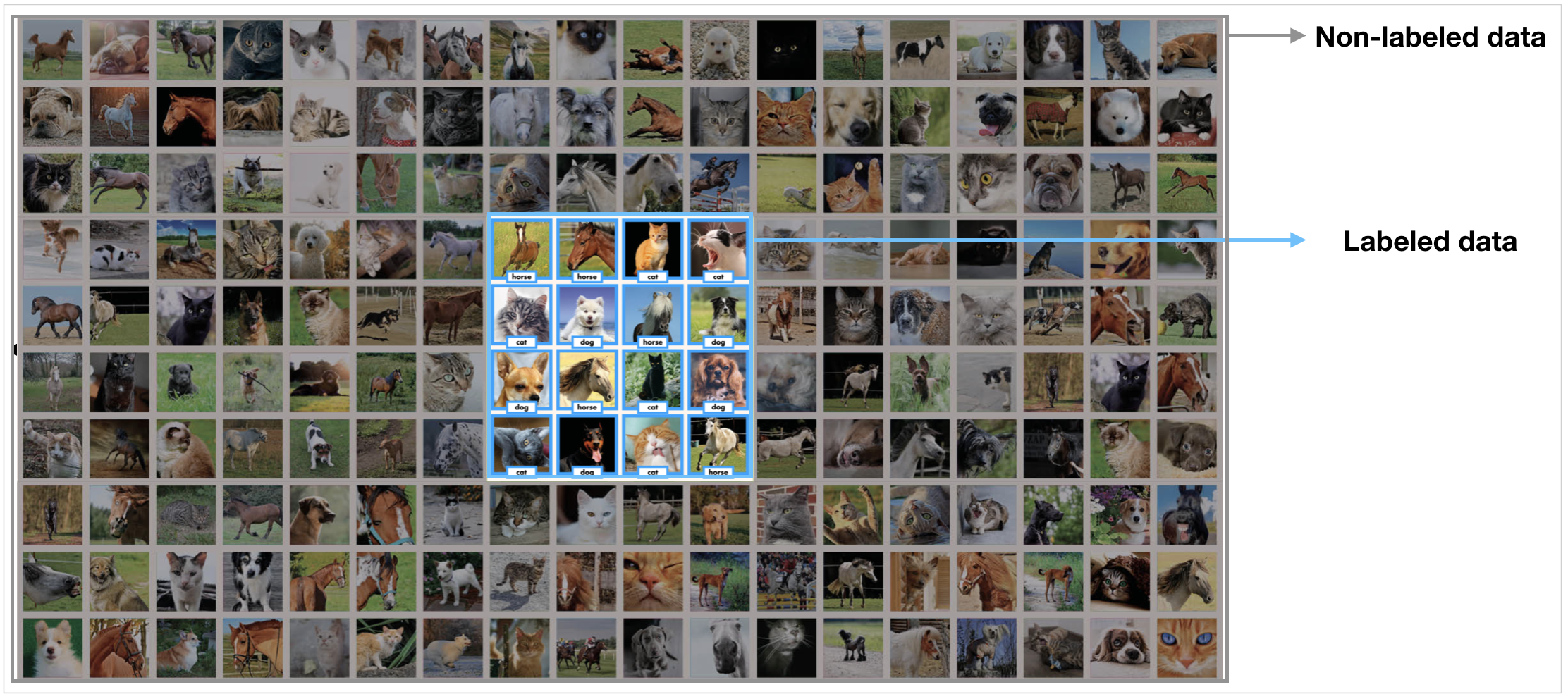
위 그림과 같이 데이터가 많은데, 그 중 일부만 labeled data고 나머지는 unlabeled data인 상황에서 진행되는 학습 방법입니다. 그러니깐 SSL 방식의 핵심은 unlabeled data를 어떻게 학습에 사용해서 적은 수의 labeled data만 이용할 수 있는 상황에서 최대한 성능을 끌어올리느냐 입니다. 아래 그림을 보시면, 정말 적은 수의 labeled data (큰 검은 점들, 큰 하얀 점들)들을 가지고는 당연히 점선의 decision boundary를 구성할 건데, 나머지 많은 unlabeled data(작은 점들)을 가지고 좋은 decision boundary를 찾아가는 방법에 대한 방식입니다.

위 논문 그림에 나오듯 여러 SSL 방법들이 이 논문에서 비교되고 분석됩니다. 이 논문은 제안된 많은 SSL 방식들을 실제로 실험하고 동일한 조건에서 비교해서 그 성능을 평가하고, 분석합니다. 그럼 그 분석 사항을 보기 전에 SSL에 대해서 간단히 (정말 간단히.. 안 그래도 너무 길어질거 같아.. 주말에 내가 미쳤지..한화 야구보다가.. 왜 논문을 읽어서 -_- ) 언급하고 넘어가면 크게 3가지 방법으로 나뉩니다. 앞에서 말씀드렸다 시피 unlabeled data를 어떻게 활용하냐에 따라 크게 1. Consistency regularization, 2. Entropy-based 3. Pesudo-labeling 입니다.
최근 논문적으로는 가장 각광받고 있는 부류가 1번 Consistency regularization입니다. 위에서 언급한 NIPS 2017에 나온 Mean teacher방식 뿐 아니라, 최근 좋은 성능을 보인 virtual adversarial training, 그리고 Π Model도 여기에 속합니다. 입력 데이터 포인트에 어떤 perturbation (단 모델의 아웃풋을 바꾸지 않은 realistic perturbation임)을 더해졌을 때, 이 데이터에 대한 모델의 결과가 perturbation이 없는 데이터를 받은 모델의 결과와 비슷하도록 학습해 나갑니다. 그러니깐.. labeled data로 잘 학습한 모델 혹은 그걸 기반으로 더 정교해진 모델이 노이즈 없는 데이터를 판단한 결과를 정답이라고 믿고, 라벨이 없는 경우 그 정답과 결과가 가까워지도록 loss 텀에 그 두 값을 거리를 추가 시킵니다. 그러니깐.. 답이 없는 문제를 풀 때, 평소 문제를 잘 푸는 애의 결과를 그 문제를 더 꼬은 문제를 풀 때 정답으로 여기겠다는거 같습니다.
자 그럼 그 세부적인 것으로 들어가면, 먼저 가장 오래된 Π Model... 아래 그림처럼 y가 있을 경우에는 cross entropy로 평소 학습하듯 배웁니다. 그리고 없거나 활용 안 할 때면, dropout을 하던, augmentation을 하던 좀 문제를 어렵게 하고 그 값을 어렵지 않게 풀었을 때와 비교합니다. 여기서는 이 텀을 consistent cost와 같은 텀으로 부릅니다.
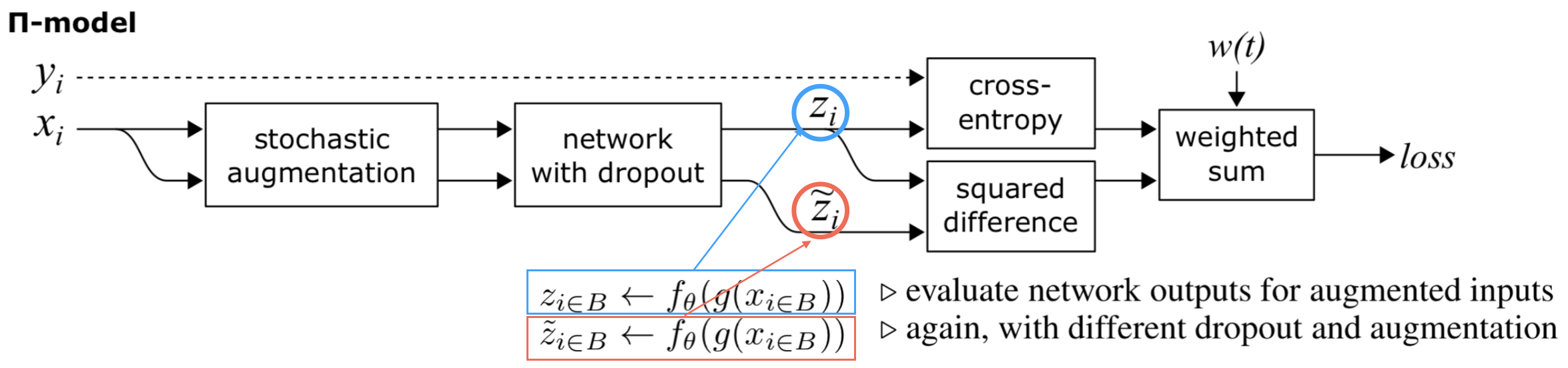
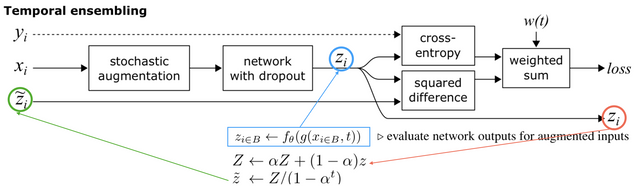
그리고 같은 논문에서 소개된 Temporal ensemble... Π Model과의 차이점은 잘 푸는 애를 어떻게 설정하냐에 있는데, 과거 모델들의 앙상블 결과를 정답으로 활용하고 그 값과 consistent하도록 줍니다. 그러니깐, 과거 모델들의 앙상블 결과가 더 정확한 결과라고 보고, 그 것을 따라 가게 만듭니다.
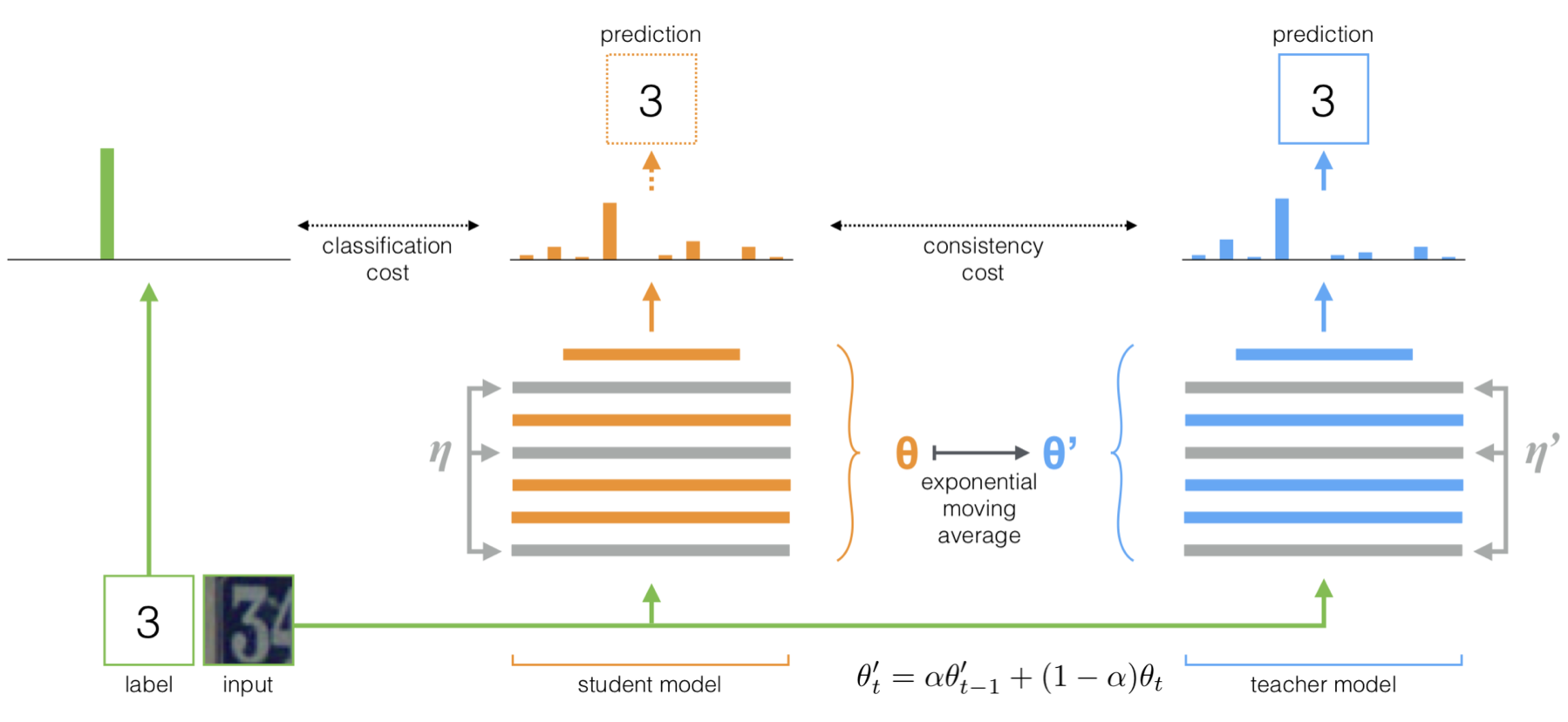
그리고 작년 NIPS에 나온 발표자료 잘 만들던 Mean teacher.. 위 Temporal ensemble은 과거 모델의 결과를 앙상블하는데, 이 방법은 모델이 과거 모델의 파라미터의 weighted sum으로 변합니다. -_- 그리고 또 달라진 점은 위 Π Model과Temporal ensemble은 모델을 공유합니다. 그런데, 이 방법은 student model과 teacher model이 분리되어 있습니다. 그래서 mean이란 단어만 쓰지 않고, teacher란 단어까지 붙여서 이름을 지은듯 합니다.
자 이제 이 방법론의 마지막 주자이자, 그래도 성능 가장 잘 뽑아주고 있는 VAT(Virtual Adversarial Training) 방법.. 이 방법은 perturbation을 찾는 방식에 있겠는데, 위 방법들은 적당히 augmentation을 해 준다거나 dropout을 건다거나 그런식이나 이 방식은 adversarial training에서 착안해 최대한 흔들어 주겠다 입니다. -_- ..

아.. 아직 첫그룹 소개 끝났다는거... -_- 아 지금이라도 그만 쓸까..
두번째 그룹은 entropy를 이용한 방식입니다. 그렇다고 어려운건 아니고, loss 텀에 아래와 같이 추가해 주어 unlabeled data에 대해서도 모델이 가야할 방향을 제시해 주는 방식입니다.

그리고 마지막이자, 가장 간단해서 젤 많이 쓰이는.. 아니 저같은 놈도 쓴.. psedo-labeling입니다. 이 방법은 더 간단한데.. 이 전 모델로 판단해서 간단한 규칙을 통해서 (어떤 분들은 threshold를 사용하시는 분들도 있고, 어떤 분들은 그냥 쓰시기도 하시더라구요..) 모델의 결과를 label이라고 잠시 주어줍니다. 그리고 다시 그 라벨을 가진 데이터까지 포함해서 다시 학습을 돌립니다. 어찌 보면 K-NN 알고리즘이 생각나는..그런.. -_- 암튼 제 경험상 문제가 어렵지 않다 싶거나 데이터의 벨런싱 조정한다거나 할 때 짬짬히 쓸만 했습니다.
아.. SSL 알고리즘 간단 리뷰 끝!!! 아.. 이제 다시 논문으로 돌아가서.. (이제서야 논문 내용 시작..)
이 논문은 Realistic Evaluation입니다. 그러니 논문 내용 안 믿고 다시 다 구현해보고 실험했겠죠. 그리고 비교를 위해서 동일한 조건에서 비교하려고 합니다. 내 알고리즘만 더 이쁘게 노력해서 구현하고 실험하지 않는다는거죠.
그래서 첫 실험은 재현!! 결과는 좀.. direct 비교는 하지 말라고 친절히 썼지만.. 결과는 재현 안 됨!! 이라고 봐도 될거 같습니다.
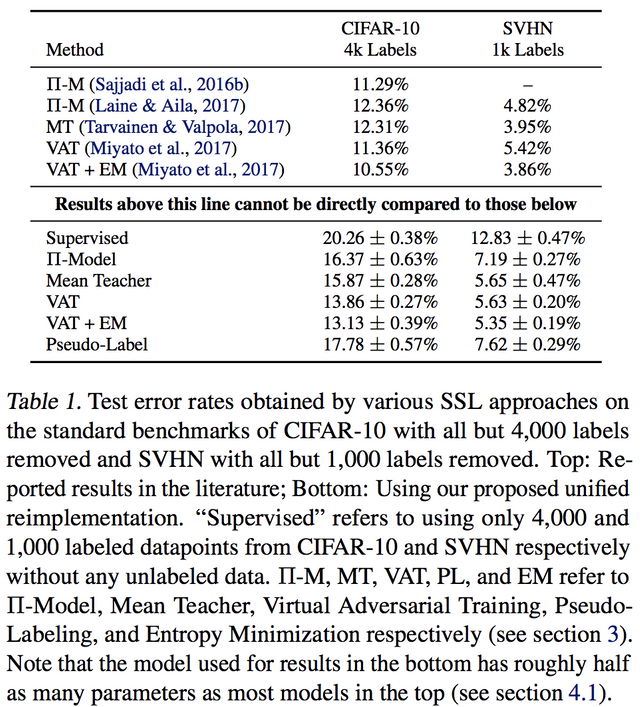
그리고 두번째, 이 부분이 중요하긴 한데요. labeled data로 진행한 fully supervised baseline을 통일 시킵니다. 그리고 그걸 잘 만들어보려고 했더니... 생각보다 논문들에서 주장한거보다 fully supervised baseline과 SSL의 결과의 차이가 그리 크지 않다는 겁니다. 한마디로 fully supervised baseline를 잘 해주는 것이 중요하고, 제대로된 비교를 위해서는 SSL에서 잘 하는 것도 중요하지만 기준에 대해서도 잘 해야 한다는거 같습니다.

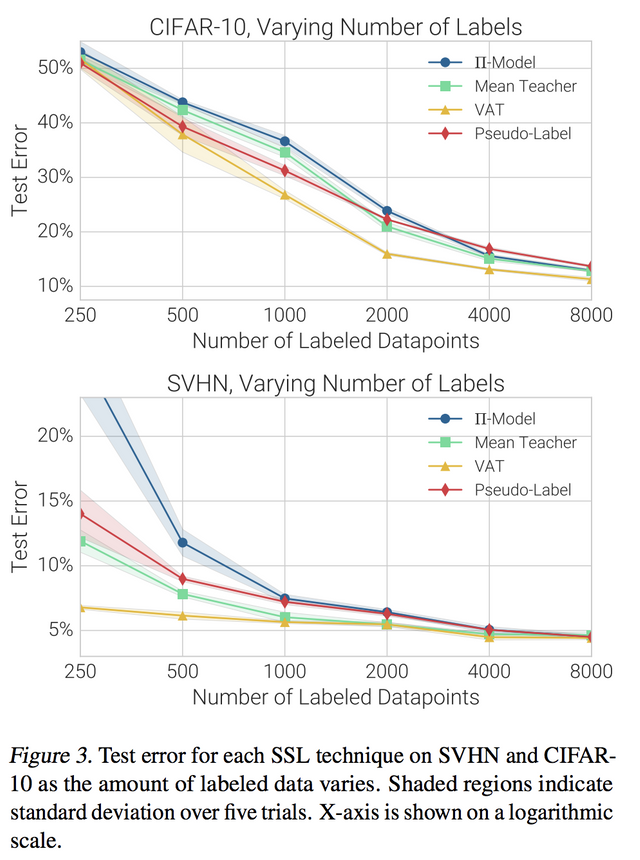
다음은.. 데이터가 적을 때, labeled data가 적을 때 SSL을 쓰기 전에 우리가 먼저 배운 것은 Transfer learning입니다. 그 결과를 놓고 비교하고자 그 결과를 뽑습니다. 그랬더니?.... Transfer learning 제대로 하니 SSL보다 좋은데? 입니다.

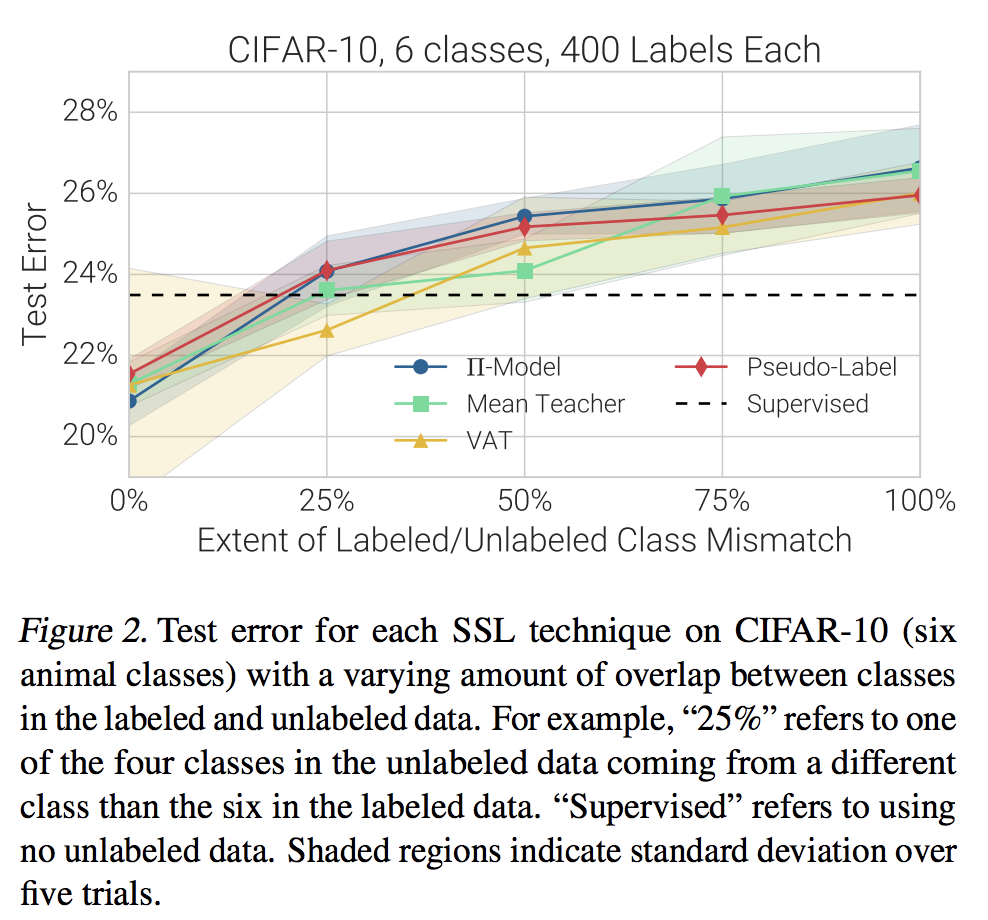
이제.. 그럼 SSL에서 언급 안 했던 부분.. 데이터를 unlabeled와 labeled로 나누었는데, 그 두 data의 class distribution이 다르면 어떨까 입니다. 많은 논문이 이 두 그룹의 class distrinution이 같다고 가정하고 그런 데이터만 썼지만, 현실은 시궁창이니깐요. 결과를 놓고 보자면.. 그 두 분포가 다르면.. 논문들의 주장과는 달리 급격히 성능이 떨어집니다. 한마디로 하나의 데이터를 나누어 한쪽으로 label을 지우는 방식의 실험에서 잘 나왔다고 현실에서 잘 나오리란 보장이 없다입니다.
그리고.. semi-supervised의 백미는 unlabeled data나 엄청 많을거란 기대감인데.. 그렇지 않을 수 있으니 비교합니다. 예상과 같이 기대감을 만족하지 않으면 참.. 힘듭니다.
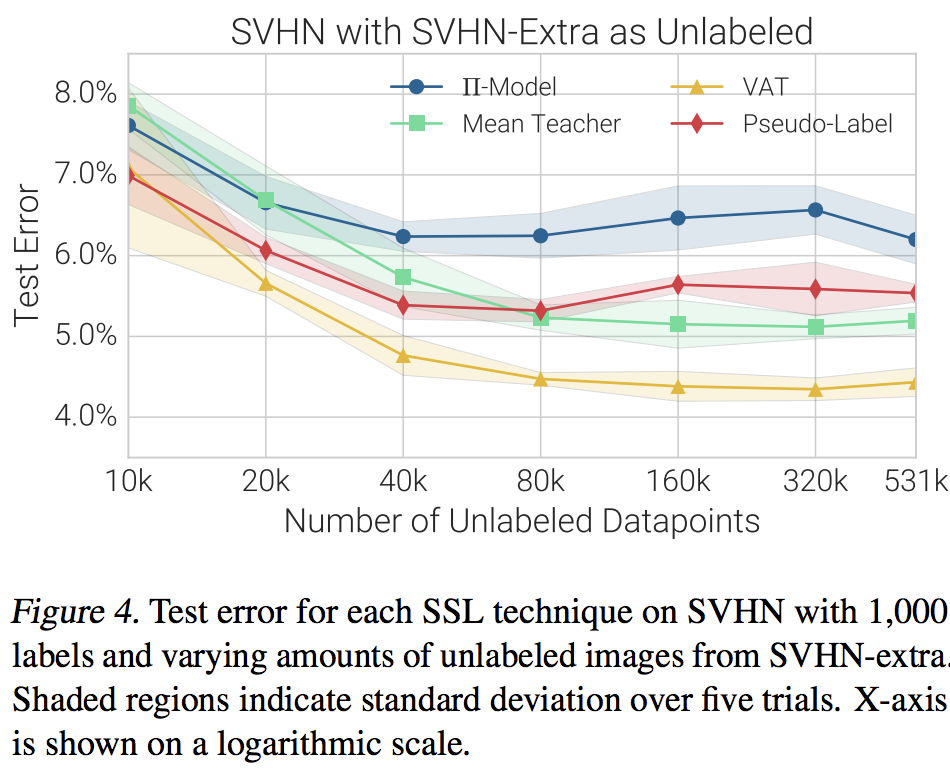
더 재밋는건.. 어떤 경우에는 알고리즘에 따라서 데이터 더 넣어주면 더 떨어질 때도 있었다는거..
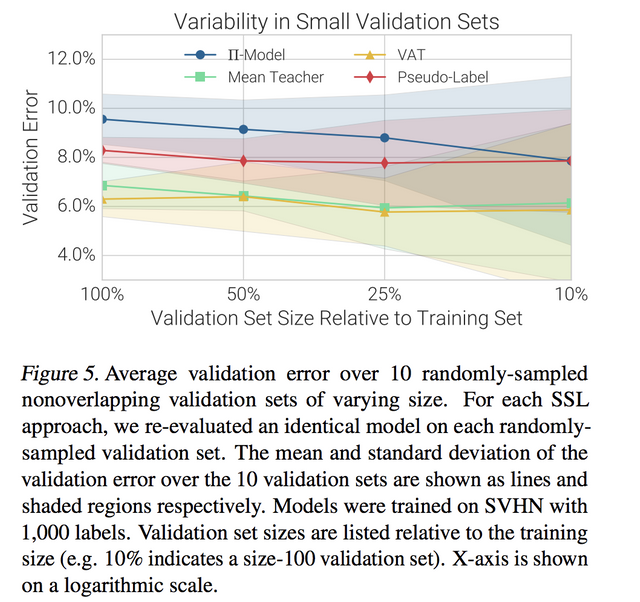
그리고 이 것도 중요한데, 이론상으로 필요한 validation set을 가져가지 못 할 때가 많은데 validation data 사이즈에 따른 결과 분석을 보여줍니다. 제대로 validation set을 가져가지 않으면 알고리즘 비교가 그닥 ... 쓸모가.. 없어질 수 있다고 합니다.
참.. 그동안 좋은 학회 ICLR, NIPS 등에 발표된 논문을 가열차게 평가하고 까는 논문이고 그 분석을 노력해서 잘 해 가서 좋은데.. 이상한 곳에서 했으면 니들 구현이나 실험이 틀렸을거란 공격을 받았겠지만, Ian과 그 동료들 아래서 착착한 실험이라 그런 공격은 오픈 리뷰에도 안 나오네요. (구글 형님 짱..)
그래서 논문의 내용을 다시 정리하면.. (야구 패배의 정신 상태에서 막쓴 리뷰라..) 아래와 같습니다.
- 우리는 같은 조건에서 비교했다.
- carefully-tuned fully-supervised accuracy 와 transfer learning performance 보고했다. 음.. SSL은 이거보다 훨 좋아야 하는거 아님? 제대로 하고 있니?
- class distribution mismatch에서 실험해 봤더니 안 좋더라.. 이래가지고 현실에서 쓰겠냐?
- SSL은 labeled data 엄청 조금 있을 때 unlabeld data 엄청 많은 때 좋은거 아님?
- validation set 사이즈 제대로 가져가야 하는거 아님?
그래서 충고는 위 상황을 고려해서 쓸만할 때 SSL을 써야할거 같다. 무조건 논문처럼 잘 되는거 아니더라.. 였습니다.
음..
이런 논문이 더 나왔으면 좋겠습니다. 다들 된다.. 잘 된다.. 내가 짱이다.. 정확도 봤냐? 쩔지? 이런 류의 논문만 나오고 설명은.. 설명하기엔 너무 흐름이 빨라서 논문 쓸라면 어쩔 수 없었다. 딥러닝 아직 블랙박스라 아무도 모른다.. 이러고 논문이 나오는데..
이런 논문들이 어떨 때 되고, 어떨 때는 안 되고, 어떻게 해 보니 좀 그렇고 어떤 경우에는 진짜 좋더라.. 라고 해 주는 이런 지식이 좋은거 같습니다. 논문의 목적은 지식, 아이디어의 공유이지, 무조건 새롭고 좋은 거의 천하제일무술대회가 아니니깐요.
저도 이 논문 읽어봐야겠네요. 좋은 논문 소개해주셔서 감사요~~