Deep Learning 3) 가장 쉽게 사용할 수 있는 딥러닝 구조는? Artificial neural network (ANN)
안녕하세요, 지행무간(知行無間)입니다.
저는 지금 딥러닝 관련 프로젝트를 진행하고 있습니다.
맨 밑의 지난글을 보시면 아무나 참여할 수 있습니다.
보상도 있습니다...
아무도 관심이 없었는데 @hogu님께서 댓글을 달아주셔서 정말 고마웠습니다.
다시 감사의 말씀을 올리며, hogu님께서 제안해주신 내용을 보니 빨리 딥러닝 설명 포스팅을 해야겠다고 생각했습니다.
우선 딥러닝은 만능이 아닙니다.
굉장히 제한된 범위에서만 사용될 수 있고, 사용하기 전의 전처리 과정이 매우 까다롭습니다.
하지만 그 제한된 범위 내에서 엄청나게 강력한 힘을 발휘할 수 있기 때문에 많이 각광받고있기는 하죠.
우선 가장 간단한 구조의 딥러닝을 설명하겠습니다.
이번 포스팅을 보시면 정말로 딥러닝이 별거아닐 수 있다는걸 느끼실겁니다.
Artificial neural network (ANN); 인공신경망
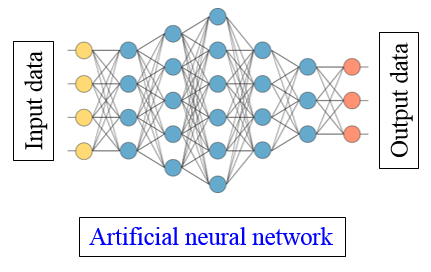
흔히 인공신경망이라고 불리는 구조입니다.
Multilayer perceptron (MLP)으로도 불립니다.
...간단하죠?
구조는 아주 간단하지만 구글의 한 조사에 따르면 대부분의 복잡한 문제도 이러한 ANN만 잘 활용해도 해결가능했다는 결과가 있기때문에, 굉장히 굉장히 중요한 구조이고, 가장 기본이 되는 구조입니다.
그림의 왼쪽을 보시면 input data가 있고, 오른쪽을 보시면 output data가 있습니다.
학습하는 방법은 간단합니다.
(사실 ANN은 조금의 선형대수학과 미적분학을 사용하면 수학적으로도 간단합니다.)
많은 데이터를 모읍니다. 흔히 빅데이터라고 불리는 것이죠.
어떤 종류의 데이터냐하면 Feature data와 정답 데이터의 쌍으로 이루어진 데이터입니다.
Feature를 어떻게 번역해야할지 모르겠는데 그냥 feature라고 부르는게 좋을 것 같습니다.
예시를 들어야 이해하기 쉬울 것 같은데요.
가장 기초적으로 많이 쓰이는 데이터가 MNIST database입니다.
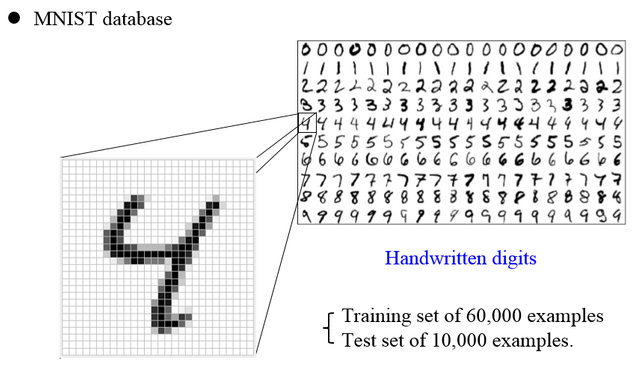
많이들 보셨을 겁니다.
사람들의 손글씨를 모아놓은 데이터세트인데, MNIST database는 총 6만 개의 training set와 1만 개의 test set으로 이루어져있습니다.
이때의 feature는 손글씨가 되는 것이죠.
training set은 학습하기위한 데이터 셋이고, test set은 학습된 ANN을 사용하여 학습이 잘 되었는지 확인하기 위한 데이터 셋입니다.
!중요! test set은 학습에 사용되지 않습니다.
다음 그림을 보시죠
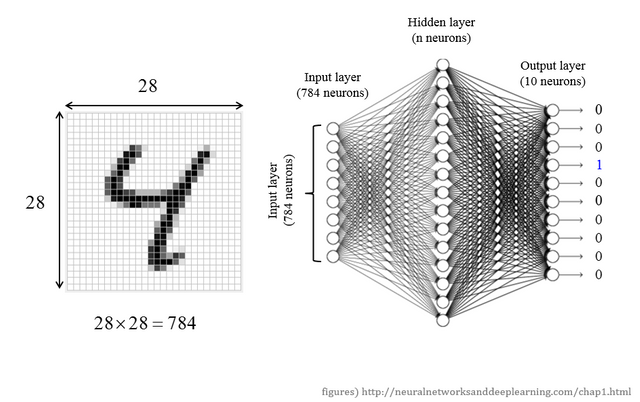
좀 전 그림에서의 손글씨 4의 경우 실제 data가 어떻게 구성되어있는지를 보여줍니다.
입력 부분에 들어갈 하나의 숫자는 보이는것처럼 총 28 x 28 개인 784개의 정보로 이루어져있습니다.
각각의 칸은 0~1 사이의 값으로, 하얀 부분은 0, 검정으로 갈수록 1의 값이 되는 것이죠.
!중요! 이렇게 딥러닝 학습에는 데이터들을 컴퓨터가 이해할 수 있는 숫자로 변형해주어야하는데, 이 작업이 사실 굉장히 시간이 많이 걸리고, 어떻게 데이터를 처리했느냐에따라 학습의 결과도 크게 달라지기때문에 매우매우매우 중요한 작업입니다.
MNIST database는 이러한 작업이 모두 이루어져있는 데이터 셋입니다.
이러한 784개의 정보(784개의 뉴런, 또는 784개의 노드)가 입력으로 들어가고,
출력에는 무엇이 들어가냐하면 총 10개의 정보로 이루어진 데이터가 들어갑니다.
이 예시에서는 숫자 4를 의미하는 4번째만 1이고, 나머지는 모두 0인 데이터입니다.
만약 입력의 손글씨가 6이었다면 출력인 정답은 "0 0 0 0 0 1 0 0 0 0"이 들어가겠죠.
그래서 각 숫자마다 출력에는 그 숫자의 정답이 저런 디지털 형태로 들어가게 되는 것입니다.
그리고는 6만개의 training data를 계속 바꿔가며 중간에 보이는 아주 많은 선들의 값들을 변화시켜가며 학습이라는 과정을 하게됩니다.
학습된 정보는 각 노드와 노드를 이은 선들, 즉 가중치(weight)에 저장되게 됩니다. 덤으로 바이어스(bias)도 있습니다.
이를 한 예시를 다시 들면 다음과 같습니다.
입력 데이터가 9개, 히든 레이어가 2개, 각각의 히든 노드가 4개씩, 그리고 출력 데이터가 1개인 경우의 ANN 구조입니다.
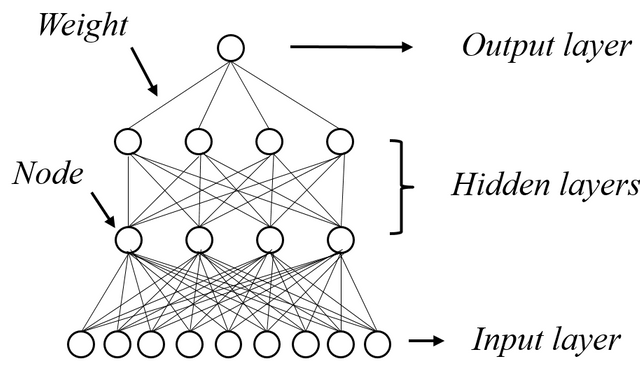
입력 데이터, 출력 데이터, 히든 레이어, 히든 노드 이런 것들이 늘어날수록 그것들을 이어주는 가중치(weight)가 기하급수적으로 늘어나게되는 구조를 확인할 수 있습니다.
학습을 마친 후에는, 입력에 손글씨를 넣어주면, 출력에서 가장 높게 나온 숫자의 순서에 해당하는 것이 내가 예측하는 답에 해당합니다.
만약 잘 이해가 안되신다면 차근차근 다시 읽어보시고, 질문을 해주시면 성실히 답변해드리겠습니다.
많이 질문해주세요~
따라서 정리를 하면 다음과 같습니다.
지금까지의 정리
- ANN 학습을 위해서는 입력과 출력의 쌍으로 이루어진 많은 데이터가 필요하다.
- 학습을 위한 데이터들은 모두 숫자의 값으로 변환가능해야 한다.
별 것 없지 않나요?
부가적으로 딥러닝은 무엇이냐면 단순히 이러한 네트워크의 층이 매우 많은 것을 의미합니다.
맨 위의 그림는 hidden layer라고 불리는 은닉층이 1개입니다.
그 다음에 설명된 그림은 은닉층이 2개인 경우이구요.
저런 층이 매우 많아지게되면 깊다고 표현하고, 딥러닝이라고 불릴 수 있을겁니다.
물론 층이 깊을수록 학습은 더 어려워지게되는 반면 더 복잡한 연관성도 학습할 수 있는 가능성이 더 생깁니다.
글의 초반에 ANN은 강력하다고 했습니다.
심지어 층이 깊지않아도 강력합니다.
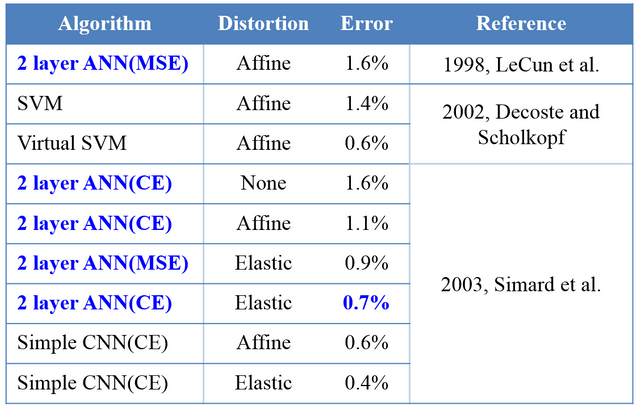
이 표는 알고리즘에 따라 MNIST database에 대한 학습 결과를 나타낸 것입니다.
알고리즘에서 주목해야 할 점은 파란색 글씨입니다.
무려 2개의 층만으로도 0.7%의 에러율을 보입니다.
에러율이란 위에서 학습에 참여하지 않은 test data, 다시말하면 ANN이 한번도 경험해보지 못한 데이터를 1만개에 대해 손글씨를 예측해보았을때 틀릴 확률입니다.
0.7%면 1만개중에 70개만 틀린 것입니다.
실제로 ANN이 틀린 것을 눈으로 확인해보면 사람도 잘 예측하기 힘든 꼬부랑글씨인 경우가 많습니다.
정말 강력하지않나요?
무언가 입력과 출력의 연관성을 찾고 싶을때 ANN만으로도 정말 강력하다는 것을 다시 강조하고 싶습니다.
뭐 이런 예시도 있을 수 있겠죠.
입력 데이터에 지난 100분간의 가상화폐 시세를 넣고,
출력 데이터에 그 다음 1분의 가상화폐 시세를 넣을 수 있겠죠.
이러한 데이터를 정말 많이 확보해서 학습을 한다면 과연 될까요?
실제로 머신러닝을 통한 주식 거래나 가상화폐 거래는 많이 하고있죠.
우리가 알지 못할 뿐이지 이미 오래전부터 사용되어왔습니다.
만약 저런 상황에서 입력과 출력 데이터 사이의 우리가 알지 못하지만 어떠한 연관성이 있다면 혹은 확률적인 상관관계가 있다면 학습이 될 수도 있습니다.
하지만 좋은 학습을 위해서는 또 다른 많은 테크닉이 필요한데요.
다음엔 이러한 좋은 학습을 위한 테크닉에 대한 포스팅을 하도록 하겠습니다.
저의 석사 졸업 논문도 ANN만을 사용해서 굉장히 만족스러운 결과를 얻을 수 있었습니다.
자, 아주 간략하게 ANN에 대해서 설명했는데, 이해가 잘 되었을지 모르겠습니다.
피드백을 주신다면 더 좋은 포스팅을 할 수 있을 것 같습니다.
그리고 딥러닝 프로젝트도 많이 참여해주시면 감사하겠습니다.
딥러닝) 지난글
Deep Learning 1) 딥러닝을 활용한 유용한 사이트들을 소개합니다
Deep Learning 2) 누구나 참여할 수 있는 딥러닝 프로젝트가 지금 시작합니다!
Congratulations @jihangmoogan! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOP아.. 어제도 읽고 오늘도 읽었지만.. 저로선 너무 이해하기가 힘드네요..ㅠㅠ 빅데이터가 필요한 것 정도는 알 것 같은데...
다시 하나의 아이디어를 내볼까 합니다.
제가 스팀을 시작한 지가 얼마 되지 않아 제가 스팀에서 읽고자 했던 글을 선별하여 찾는 과정이 아직까진 힘든면이 있습니다.
"계정내의 업보트를 한 내역을 바탕으로 관심 있게 볼 만한 글을 검색해주는기능이 스팀에 있었으면 좋겠다"는 생각이 들었습니다.
어찌 보면 참신한 아이디어는 아니겠지만..
스팀에 어울릴것 같다는 생각에 적고 갑니다.
딥러닝 기술 자체가 아직 이해가 잘 안 되긴 하네요.. ㅠㅠ
아 그러신가요 ㅠㅠ 구체적으로 어떤부분이 이해 안가시는지 말씀해주시면 최대한 자세히 작성해보겠습니다...
그런데 @hogu님께서 이번에 말씀해주신 아이디어는 굉장히 흥미롭습니다.
일종의 추천시스템을 말씀하시는거 같은데요.
대표적으로 유튜브의 추천동영상 기능이 Deep Neural Networks를 사용했습니다.
다음과 같은 논문인데요.
2016, P. Covington et al, Deep Neural Networks for YouTube Recommendations
이 논문에 쓰인 알고리즘을 스팀에서 reproduce하는 것은 매우 매우 재미있을것같습니다.
하지만 스팀의 데이터를 다룰 수 있어야하고, 이러한 학습을 할 수 있는 정보가 충분히 제공되고 있는지 아직 확실하지 않습니다. 조만간 이 논문에서 어떤 핵심 아이디어들이 사용되었는지 포스팅하도록 하겠습니다. 그리고 좀 더 실력을 갈고닦아서 시간이 좀 걸리겠지만 이 아이디어로 꼭 한번 도전해보도록 하겠습니다. 감사합니다.
아 답장이 너무 늦었네요. .죄송합니다 ㅠㅠ
우선 주제가 너무 어렵습니다..ㅠ
어려운 만큼 이해라도 쉬웠으면 좋겠는데...
어려운 용어들과 낯선 단어들이 많고...
하나하나 검색해가면서 읽은 것 같습니다..ㅠㅠ
ANN이 인공지능을 구현하기 위한 방법 중 하나 인지...
많이 들어본 단어 딥러닝과 ANN은 다른 알고리즘인지... ANN이 딥러닝 중 하나인지...
의문도 드네요..ㅠㅠ
에공.. 죄송합니다..ㅠㅠ
Congratulations @jihangmoogan! You have received a personal award!
Click on the badge to view your own Board of Honor on SteemitBoard.
Congratulations @jihangmoogan! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Vote for @Steemitboard as a witness to get one more award and increased upvotes!